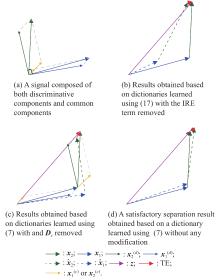
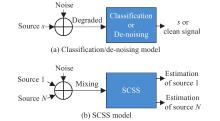
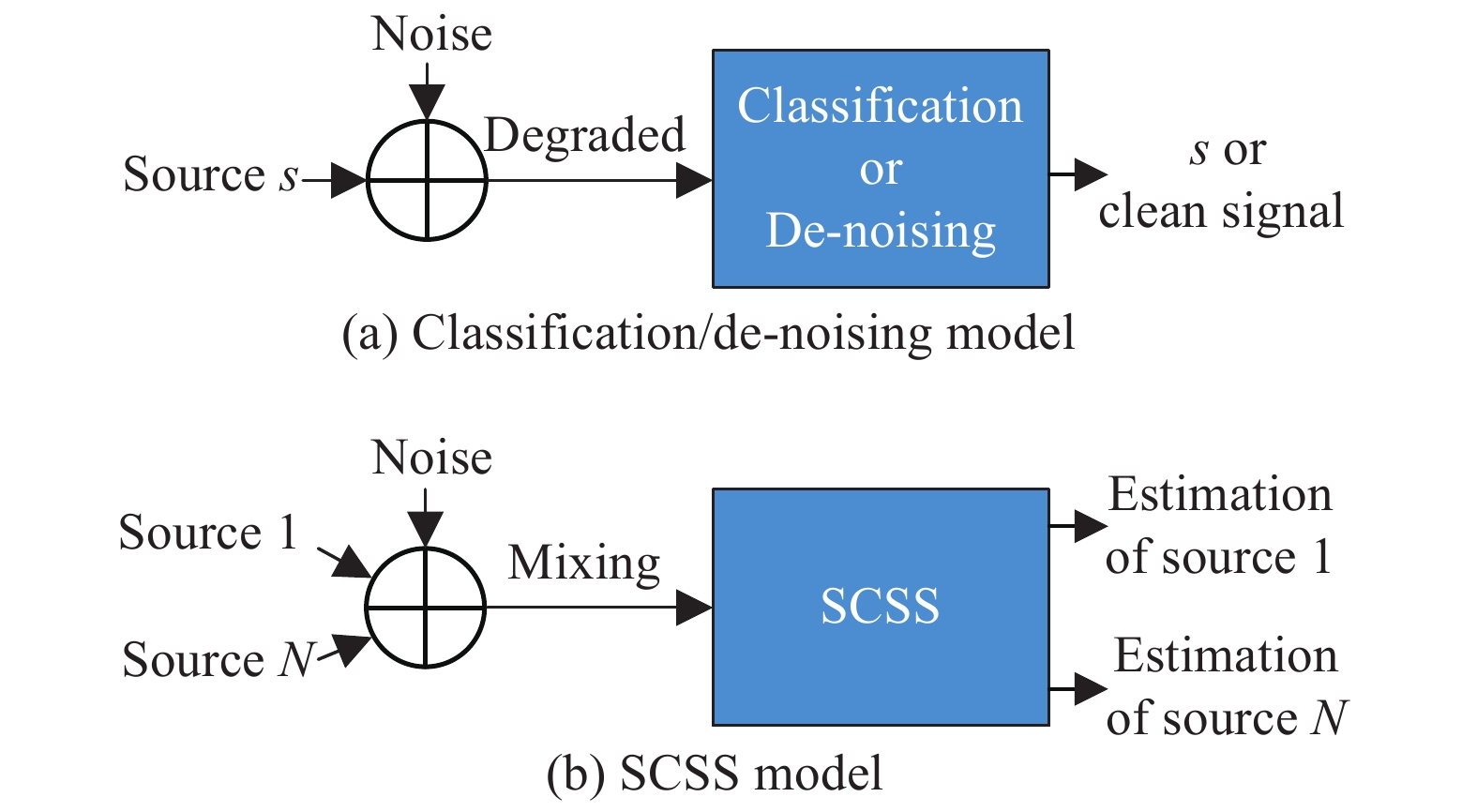
| 1 |
ROWEIS S T. One microphone source separation. Advances in Neural Information Processing Systems, 2000, 13: 793–799.
|
| 2 |
VINCENT E, VIRTANEN T, GANNOT S. Audio source separation and speech enhancement. New York: John Wiley & Sons Press, 2018.
|
| 3 |
XU C, RAO W, XIAO X, et al. Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2018: 6–10.
|
| 4 |
WANG Q, WOO W L, DLAY S S, et al. Informed single channel speech separation with time-frequency exemplar GMM-HMM model. Proc. of the International Conference on Digital Signal Processing, 2015: 1130–1134.
|
| 5 |
YEMINY Y R, KELLER Y, GANNOT S. Single microphone speech separation by diffusion-based HMM estimation. EURASIP Journal on Audio, Speech, and Music Processing, 2016. DOI: 10.1186/s13636-016-0094-9.
|
| 6 |
ZIBULEVSKY M, PEARLMUTTER B A Blind source separation by sparse decomposition in a signal dictionary. Neural Computing, 2001, 13 (4): 863- 882.
doi: 10.1162/089976601300014385
|
| 7 |
GOWREESUNKER B V, TEWFIK A H. Blind source separation using monochannel overcomplete dictionaries. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2008: 33−36.
|
| 8 |
QIAN Y M, WENG C, CHANG X K, et al. Past review, current progress, and challenges ahead on the cocktail party problem. Frontiers of Information Technology & Electronic Engineering, 2018, 19: 40–63.
|
| 9 |
BAO C L, JI H, QUAN Y H, et al Dictionary learning for sparse coding: algorithms and convergence analysis. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2015, 38 (7): 1356- 1369.
|
| 10 |
AHARON M, ELAD M, BRUCKSTEIN A K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. on Signal Processing, 2006, 54 (11): 4311- 4322.
doi: 10.1109/TSP.2006.881199
|
| 11 |
LEE D D, SEUNG H S Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401 (6755): 788- 791.
doi: 10.1038/44565
|
| 12 |
HOYER P O. Non-negative sparse coding. Proc. of the 12th Workshop on Neural Networks for Signal Processing, 2002: 557−565.
|
| 13 |
YANG J C, WANG Z W, LIN Z, et al Coupled dictionary training for image super-resolution. IEEE Trans. on Image Processing, 2012, 21 (8): 3467- 3478.
doi: 10.1109/TIP.2012.2192127
|
| 14 |
WEI X, SHEN H, LI Y X, et al Reconstructible nonlinear dimensionality reduction via joint dictionary learning. IEEE Trans. on Neural Networks and Learning Systems, 2018, 30 (1): 175- 189.
|
| 15 |
SCHMIDT M N, OLSSON R K. Single-channel speech separation using sparse non-negative matrix factorization. Proc. of the 9th International Conference on Spoken Language Processing, 2006: 2614–2617.
|
| 16 |
KING B J, ATLAS L Single-channel source separation using complex matrix factorization. IEEE Trans. on Audio Speech and Language Processing, 2011, 19 (8): 2591- 2597.
doi: 10.1109/TASL.2011.2156786
|
| 17 |
GRAIS E M, ERDOGAN H. Single channel speech music separation using nonnegative matrix factorization with sliding window and spectral masks. Proc. of the 12th Annual Conference on International Speech Communication Association, 2011: 1773–1776.
|
| 18 |
GRAIS E M, ERDOGAN H. Discriminative nonnegative dictionary learning using cross-coherence penalties for single channel source separation. Proc. of the 14th Annual Conference on International Speech Communication Association, 2013: 808–812.
|
| 19 |
GANG A, BIYANI P On discriminative framework for single channel audio source separation. Proc. of the 17th Annual Conference on International Speech Communication Association, 2016, 565- 569.
|
| 20 |
XU Y F, BAO G Z, XU X, et al Single channel speech separation using sequential discriminative dictionary learning. Signal Processing, 2015, 106, 134- 140.
doi: 10.1016/j.sigpro.2014.07.012
|
| 21 |
SUN L H, ZHAO C, SU M, et al Single-channel blind source separation based on joint dictionary with common sub-dictionary. International Journal of Speech Technology, 2018, 21 (1): 19- 27.
doi: 10.1007/s10772-017-9469-2
|
| 22 |
WANG Z, SHA F. Discriminative non-negative matrix factorization for single-channel speech separation. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2014: 3749–3753.
|
| 23 |
WENINGER F, ROUX J L, HERSHEY J R, et al. Discriminative NMF and its application to single-channel source separation. Proc. of the 15th Annual Conference on International Speech Communication Association, 2014: 865–869.
|
| 24 |
WANG Y, WANG D L Towards scaling up classification-based speech separation. IEEE Trans. on Audio Speech and Language Processing, 2013, 21 (7): 1381- 1390.
doi: 10.1109/TASL.2013.2250961
|
| 25 |
WENINGER F, HERSHEY J R, ROUX J L, et al. Discriminatively trained recurrent neural networks for single-channel speech separation. Proc. of the Global Conference on Signal and Information Processing, 2014: 577–581.
|
| 26 |
GRAIS E M, PLUMBLEY M D. Single channel audio source separation using convolutional denoising autoencoders. Proc. of the Global Conference on Signal and Information Processing, 2017: 1265–1269.
|
| 27 |
HERSHEY J R, CHEN Z, ROUX J L, et al. Deep clustering: discriminative embeddings for segmentation and separation. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2016: 31–35.
|
| 28 |
WRIGHT J, YANG A Y, GANESH A, et al Robust face recognition via sparse representation. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2009, 31 (2): 210- 227.
doi: 10.1109/TPAMI.2008.79
|
| 29 |
CHRISTENSEN H, BARKER J, MA N, et al. The CHiME corpus: a resource and a challenge for computational hearing in multisource environments. Proc. of the 11th Annual Conference on International Speech Communication Association, 2010: 1918–1921.
|
| 30 |
VINCENT E, GRIBONVAL R, FEVOTTE C Performance measurement in blind audio source separation. IEEE Trans. on Audio Speech and Language Processing, 2006, 14 (4): 1462- 1469.
doi: 10.1109/TSA.2005.858005
|
| 31 |
MAJEED S A, HUSAIN H, SAMAD S A, et al Mel frequency cepstral coefficients (MFCC) feature extraction enhancement in the application of speech recognition: a comparison study. Journal of Theoretical and Applied Information Technology, 2015, 79 (1): 38- 56.
|
 ), Xing WANG2(
), Xing WANG2(