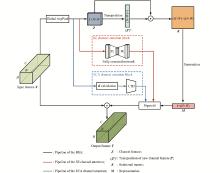
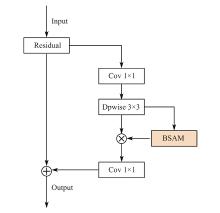
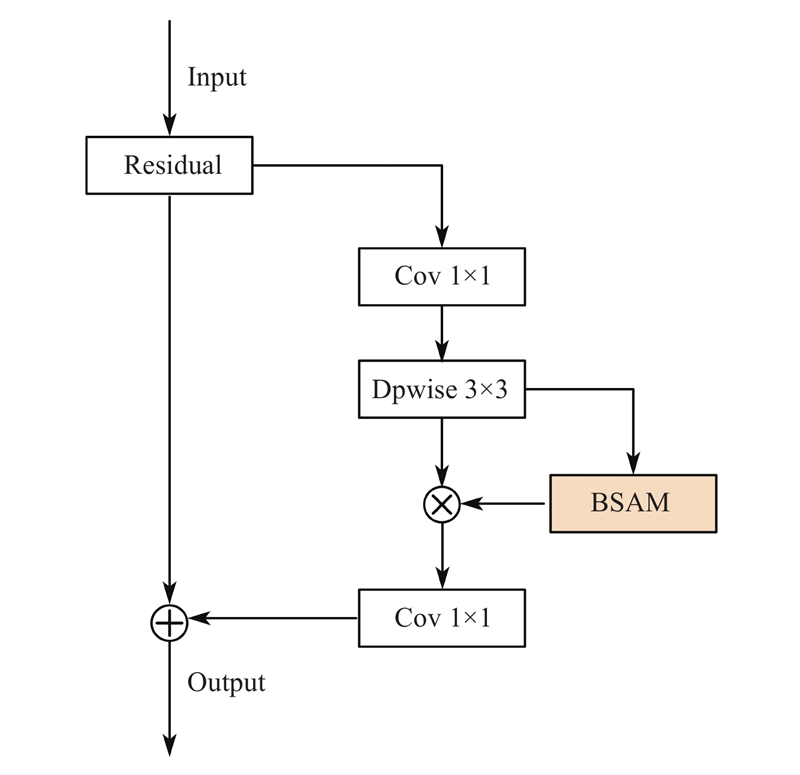
| 1 |
HU J, SHEN L, ALBANIE S. Squeeze-and-excitation networks. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2018: 7132–7141.
|
| 2 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module. Proc. of the European Conference on Computer Vision, 2018: 3–19.
|
| 3 |
FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2019: 3146–3154.
|
| 4 |
ZHANG H, GOODFELLOW I, METAXAS D, et al. Self-attention generative adversarial networks. Proc. of the 36th International Conference on Machine Learning, 2019: 7354–7363.
|
| 5 |
PARK J, WOO S, LEE J Y, et al. BAM: bottleneck attention module. https://arxiv.org/abs/1807.06514v1.
|
| 6 |
WANG Q L, WU B G, ZHU P H, et al. ECA-Net: efficient channel attention for deep convolutional neural networks. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020: 11531–11539.
|
| 7 |
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4510–4520.
|
| 8 |
ZHOU D Q, HOU Q B, CHEN Y P, et al. Rethinking bottleneck structure for efficient mobile network design. Proc. of the European Conference on Computer Vision, 2020: 680–697.
|
| 9 |
BOSSARD L, GUILLAUMIN M, VAN GOOL L. Food-101–mining discriminative components with random forests. Proc. of the European Conference on Computer Vision, 2014: 446–461.
|
| 10 |
GRIFFIN G, HOLUB A, PERONA P. Caltech-256 object category dataset. California Institute of Technology, 2007: 1–20.
|
| 11 |
VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning. Advances in Neural Information Processing Systems, 2016, 29: 8909022.
|
| 12 |
IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. https://arxiv.org/abs/1602.07360v4.
|
| 13 |
GHOLAMI A, KWON K, WU B, et al. SqueezeNext: hardware-aware neural network design. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2018: 1638–1647.
|
| 14 |
ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2018: 6848–6856.
|
| 15 |
HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2017: 4700–4708.
|
| 16 |
HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. https://arXiv preprint arXiv: 1704.04861.
|
| 17 |
HOWARD A, SANDLER M, CHU G, et al. Searching for MobileNetV3. Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 1314–1324.
|
| 18 |
MEHTA S, RASTEGARI M, CASPI A, et al. ESPNet: efficient spatial pyramid of dilated convolutions for semantic segmentation. Proc. of the European Conference on Computer Vision, 2018: 552–568.
|
| 19 |
HUANG G, LIU S, VAN DER M L, et al. CondenseNet: an efficient DenseNet using learned group convolutions. Proc. of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2018: 2752–2761.
|
| 20 |
WANG R J, LI X, LING C X. Pelee: a real-time object detection system on mobile devices. Advances in Neural Information Processing Systems, 2018: 31: 1967−1976.
|
| 21 |
ZOPH B, LE Q V. Neural architecture search with reinforcement learning. https://arxiv.org/abs/1611.01578.
|
| 22 |
TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks. Proc. of the 36th International Conference on Machine Learning, 2019: 6105–6114.
|
| 23 |
CAI H, ZHU L G, HAN S. ProxylessNAS: direct neural architecture search on target task and hardware. https://arxiv.org/abs/1812.00332.
|
| 24 |
WU B C, DAI X L, ZHANG P Z, et al. FBNet: hardware-aware efficient convnet design via differentiable neural architecture search. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 10734–10742.
|
| 25 |
MA N N, ZHANG X Y, HUANG J W, et al. WeightNet: revisiting the design space of weight networks. Proc. of the European Conference on Computer Vision, 2020: 776–792.
|
| 26 |
MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention. Advances in Neural Information Processing Systems, 2014: 2204-2212.
|
| 27 |
HUANG Z L, WANG X G, WEI Y C, et al. CCnet: criss-cross attention for semantic segmentation. Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 603–612.
|
| 28 |
LI X, ZHONG Z S, WU J L, et al. Expectation-maximization attention networks for semantic segmentation. Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 9167–9176.
|
| 29 |
ROBBINS H, MONRO S. A stochastic approximation method. The Annals of Mathematical statistics, 1951: 400–407.
|
| 30 |
DENG J, DONG W, SOCHER R, et al. Imagenet: a large-scale hierarchical image database. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2009: 248–255.
|
| 31 |
GALLO I, RIA G, LANDRO N, et al. Image and text fusion for UPMC Food-101 using BERT and CNNs. Proc. of the 35th International Conference on Image and Vision Computing New Zealand, 2020. DOI: 10.1109/IVCNZ51579.2020.9290622.
|
| 32 |
CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations. Proc. of the International Conference on Machine Learning, 2020: 1597–1607.
|
| 33 |
GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 2020: 21271–21284.
|
| 34 |
GOYAL P, DUVAL Q, SEESSEL I, et al. Vision models are more robust and fair when pretrained on uncurated images without supervision. https://arxiv.org/abs/2202.08360.
|
| 35 |
CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 2020: 9912–9924.
|
| 36 |
DWIBEDI D, AYTAR Y, TOMPSON J, et al. With a little help from my friends: nearest-neighbor contrastive learning of visual representations. Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 9588–9597.
|
| 37 |
LU Z, SREEKUMAR G, GOODMAN E, et al Neural architecture transfer. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2021, 43 (9): 2971- 2989.
doi: 10.1109/TPAMI.2021.3052758
|
| 38 |
TOUVRON H, SABLAYROLLES A, DOUZE M, et al. Grafit: learning fine-grained image representations with coarse labels. Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 874–884.
|
 ), Yingmei WEI1(
), Yingmei WEI1(