
Journal of Systems Engineering and Electronics ›› 2024, Vol. 35 ›› Issue (3): 509-531.doi: 10.23919/JSEE.2023.000159
• HIGH-DIMENSIONAL SIGNAL PROCESSING •
Xinwei OU( ), Zhangxin CHEN(), Ce ZHU(), Yipeng LIU()
), Zhangxin CHEN(), Ce ZHU(), Yipeng LIU()
Received:2022-09-21
Accepted:2023-07-21
Online:2024-06-18
Published:2024-06-19
Contact:
Zhangxin CHEN, Yipeng LIU
E-mail:xinweiou@std.uestc.edu.cn;zhangxinchen@uestc.edu.cn;eczhu@uestc.edu.cn;yipengliu@uestc.edu.cn
About author:Supported by:Xinwei OU, Zhangxin CHEN, Ce ZHU, Yipeng LIU. Low rank optimization for efficient deep learning: making a balance between compact architecture and fast training[J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 509-531.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks

Fig 1
Overview of low rank optimization for efficient deep learning"
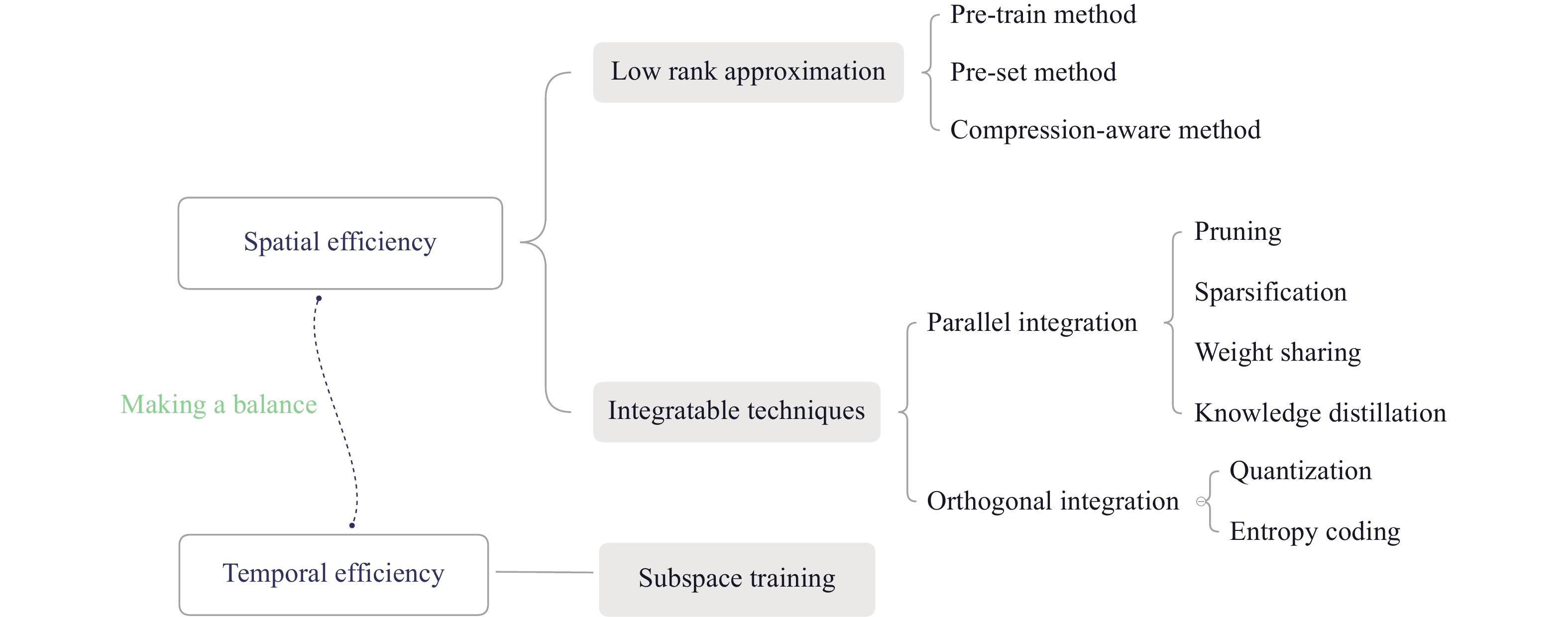
Table 1
Comparison of compression performance of advanced tensor decomposition methods on ResNet32 with Cifar10 dataset"
| Method | Top-1 Accuracy/% | Compression ratio |
| Tucker [ | 87.70 | 5 times |
| TT [ | 88.3 | 4.8 times |
| TR [ | 90.6 | 5 times |
| BTD [ | 91.1 | 5 times |
| GKPD [ | 91.5 | 5 times |
| HT [ | 89.9 | 1.6 times |
| STT [ | 91.0 | 9 times |
Table 2
Notations used in this paper"
| Notation | Description |
| diag(·) | Generation of a diagonal matrix by taking the input vector as the main diagonal |
| Kronecker product | |
| Vector outer product | |
| n-mode product | |
| Semi-tensor product |
Table 3
Comparison among FC layer compressed by TT, TR, HT, BTD, STR, and KPD on computation costs and storage consumption"
| Method | Computation | Storage |
| FC | ||
| TT | ||
| TR | ||
| HT | ||
| BTD | ||
| STR | ||
| KPD |
Table 4
Comparison among convolutional layer compressed by TT, TR, HT, BTD, STR, GKPD on computation costs and storage consumption."
| Method | Computation | Storage |
| Conv | ||
| TT | ||
| TR | ||
| HT | ||
| BTD | ||
| STR | ||
| GKPD |
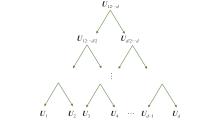
Fig 2
HT decomposition"
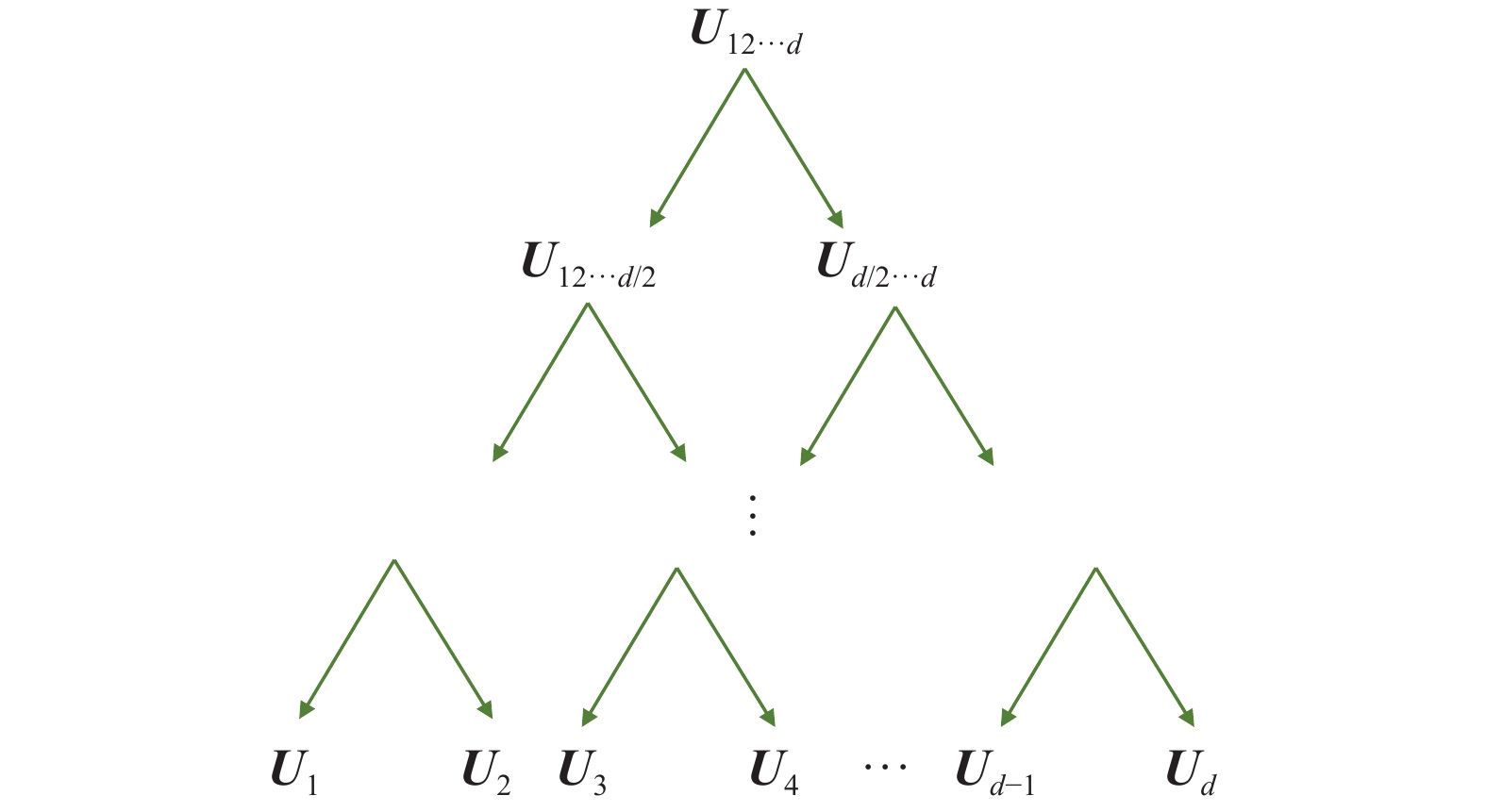

Fig 3
The chain computation for a fourth-order case"
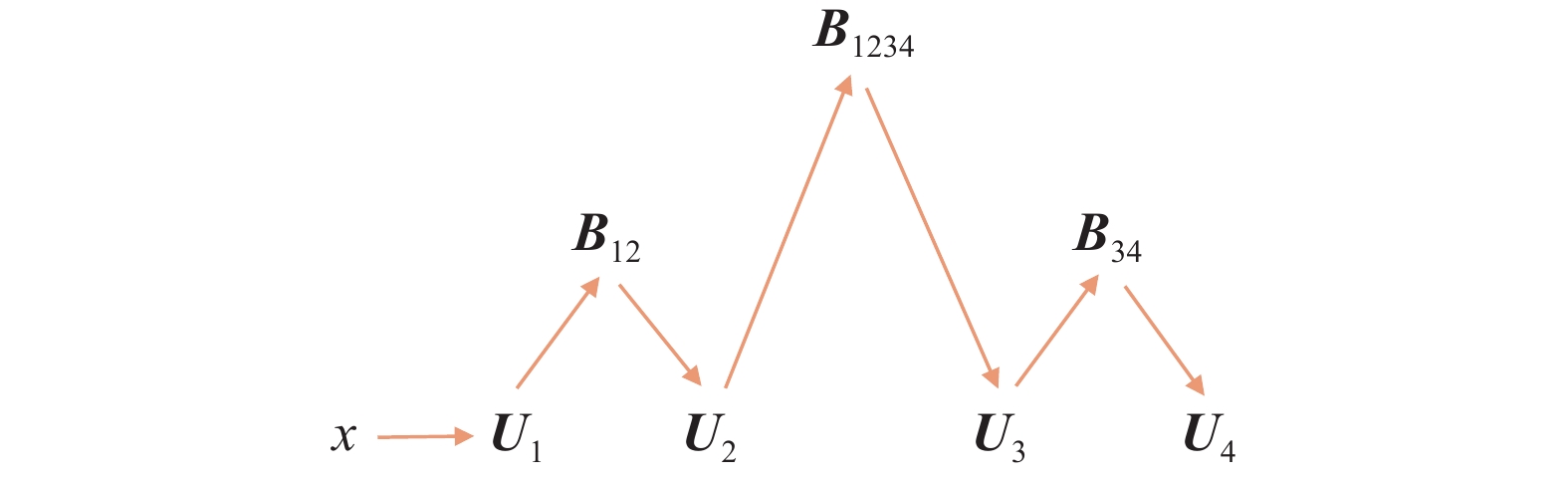
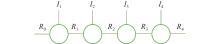
Fig 4
A fourth order tensor in TT format"

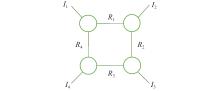
Fig 5
A fourth-order tensor in TR format"
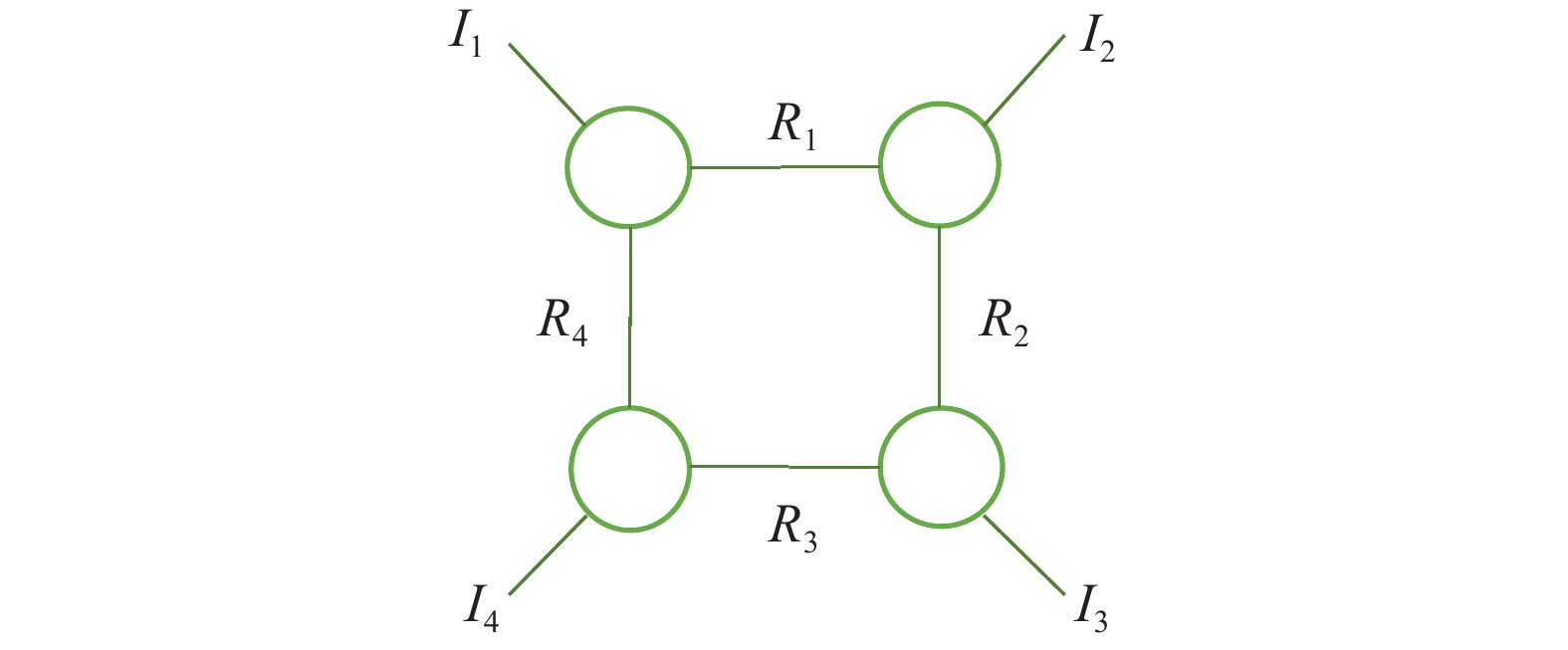
Table 5
Three types of low rank optimization method for model compression"
| Method | Description | Representative works |
| Pre-train | Pretrain the target model, apply tensor decomposition to trained weight tensors, and then fine-tune to recover accuracy | [ |
| Pre-set | Construct tensorized netwoks, set properinitialization, and then train the whole network | [ |
| Compression-aware | Train the original network with normal optimizersbut enforce weight tensors to enjoy low rank structure | [ |
Fig 6
A graphical illustration of Gini Index for a vector [1,2,3,4,10]"
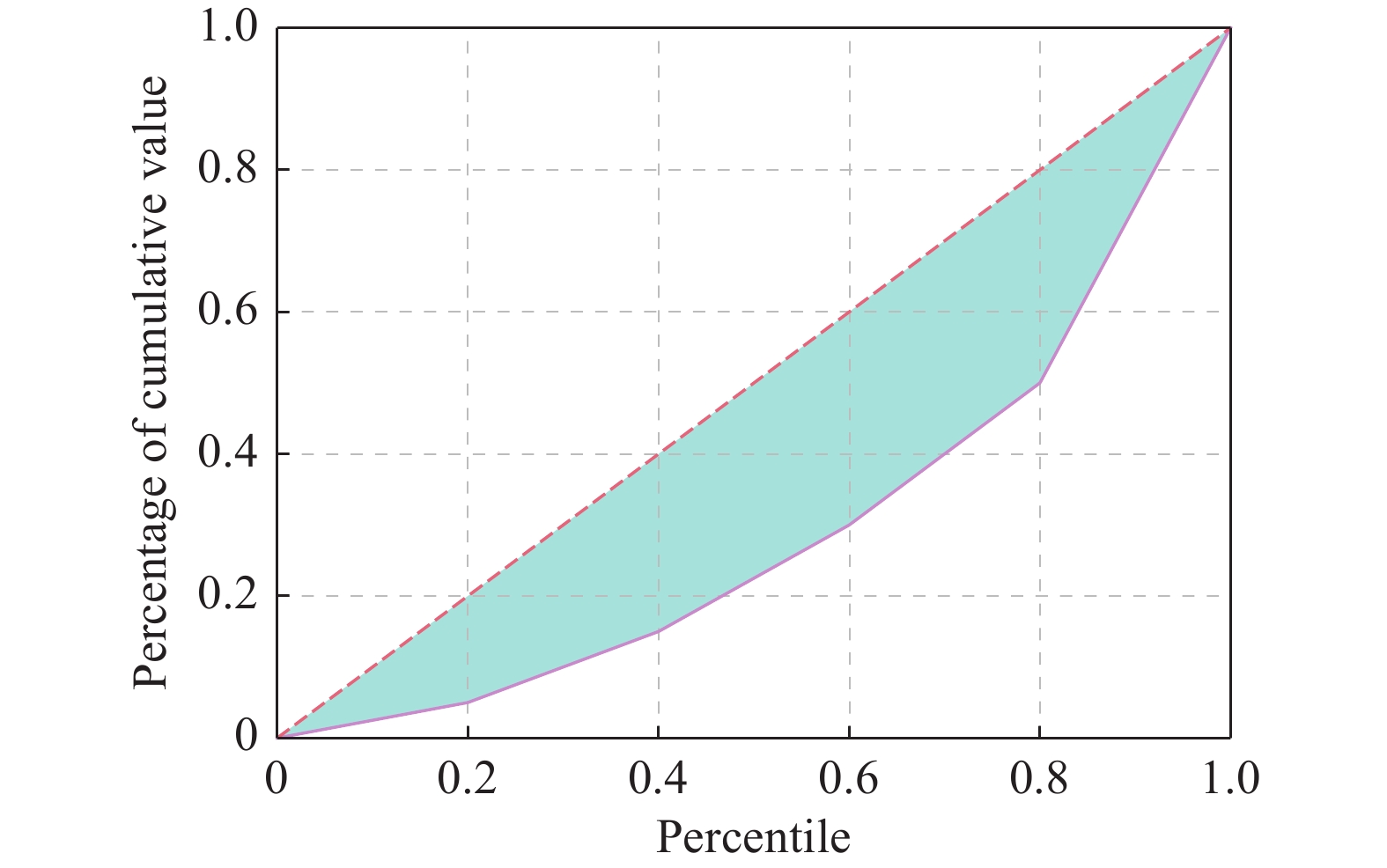
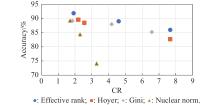
Fig 7
Accuracy on Cifar10 v.s. compression ratio of the number of parameters in ResNet32"
Table 6
Integratable techniques"
| Type of integration | Technique | Description | Representative integration works |
| Parallel integration | Pruning | Discard insignificant connections | [ |
| Sparsification | Zero out insignificant weights | [ | |
| Weight sharing | Share weights across different connections | [ | |
| Knowledge distillation | Transfer knowledge learned from teacher to student | [ | |
| Orthogonal integration | Quantization | Reduce precision | [ |
| Entropy coding | Encode weights into binary codewords | [ |
Table 7
Ability to compress and accelerate for various techniques"
| Technique | Acceleration | Compression |
| Pruning | √ | √ |
| Sparsification | √ | √ |
| Weight sharing | × | √ |
| Knowledge distillation | √ | √ |
| Quantization | √ | √ |
| Entropy coding | × | √ |

Fig 8
Normalized error v.s. rank when projecting SVD-compressed LeNet-300-100 on a 5D subspace"
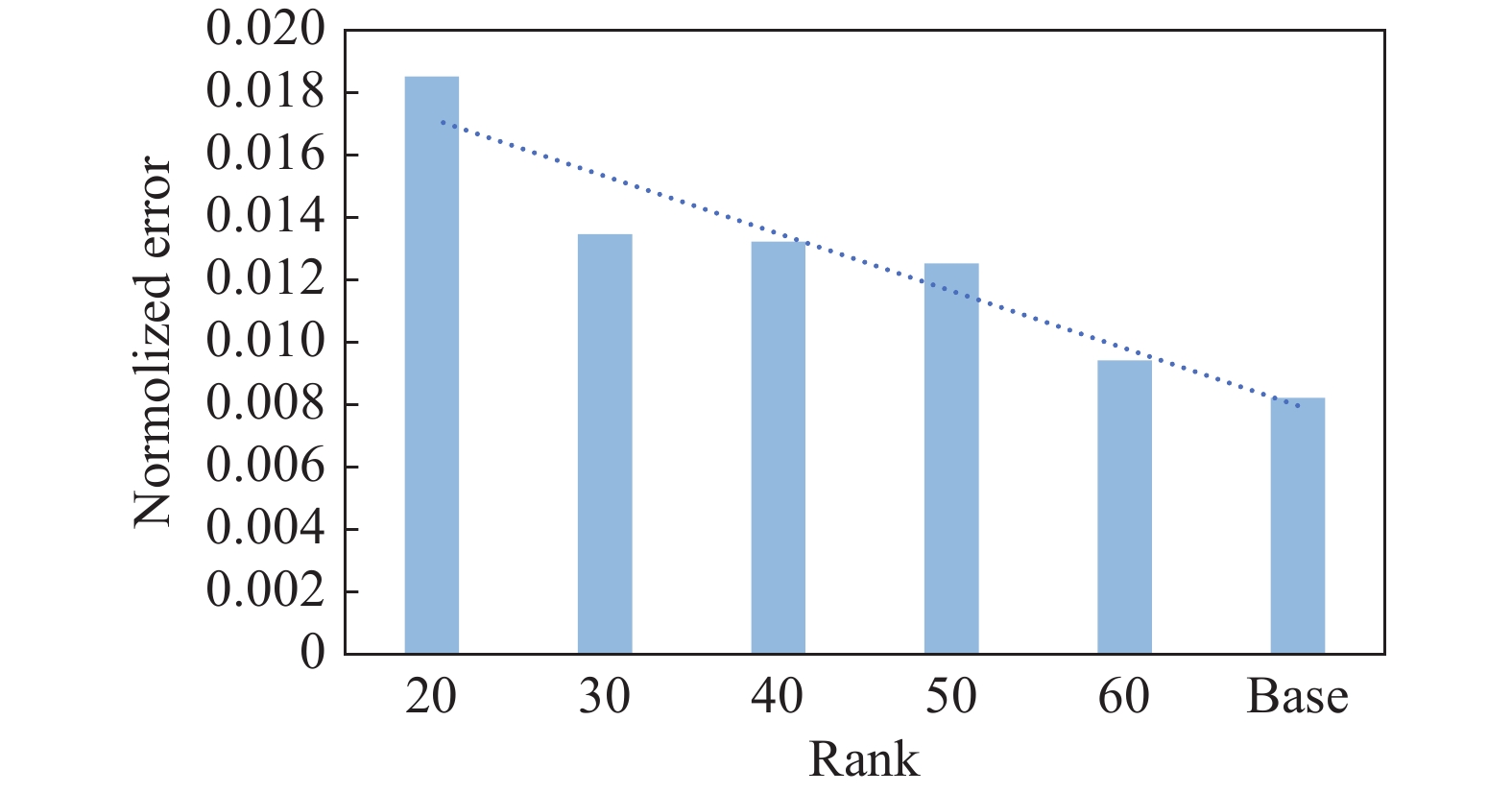
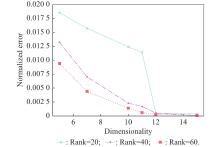
Fig 9
Normalized error v.s. dimensionality of subspace under different ranks (different compression extents)"
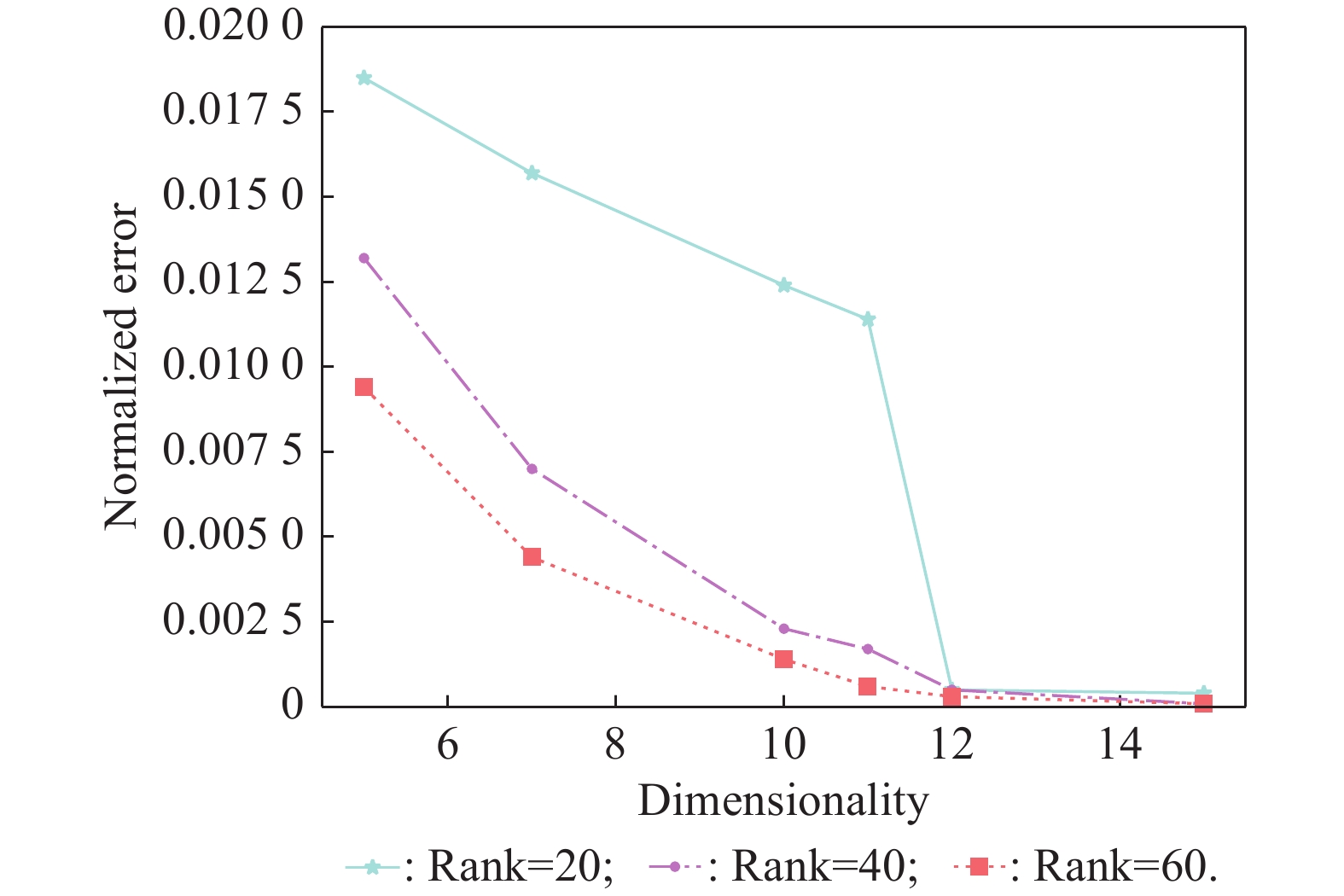
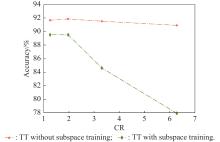
Fig 10
Comparison of the accuracy degradation when applying subspace training to TT-Nets"
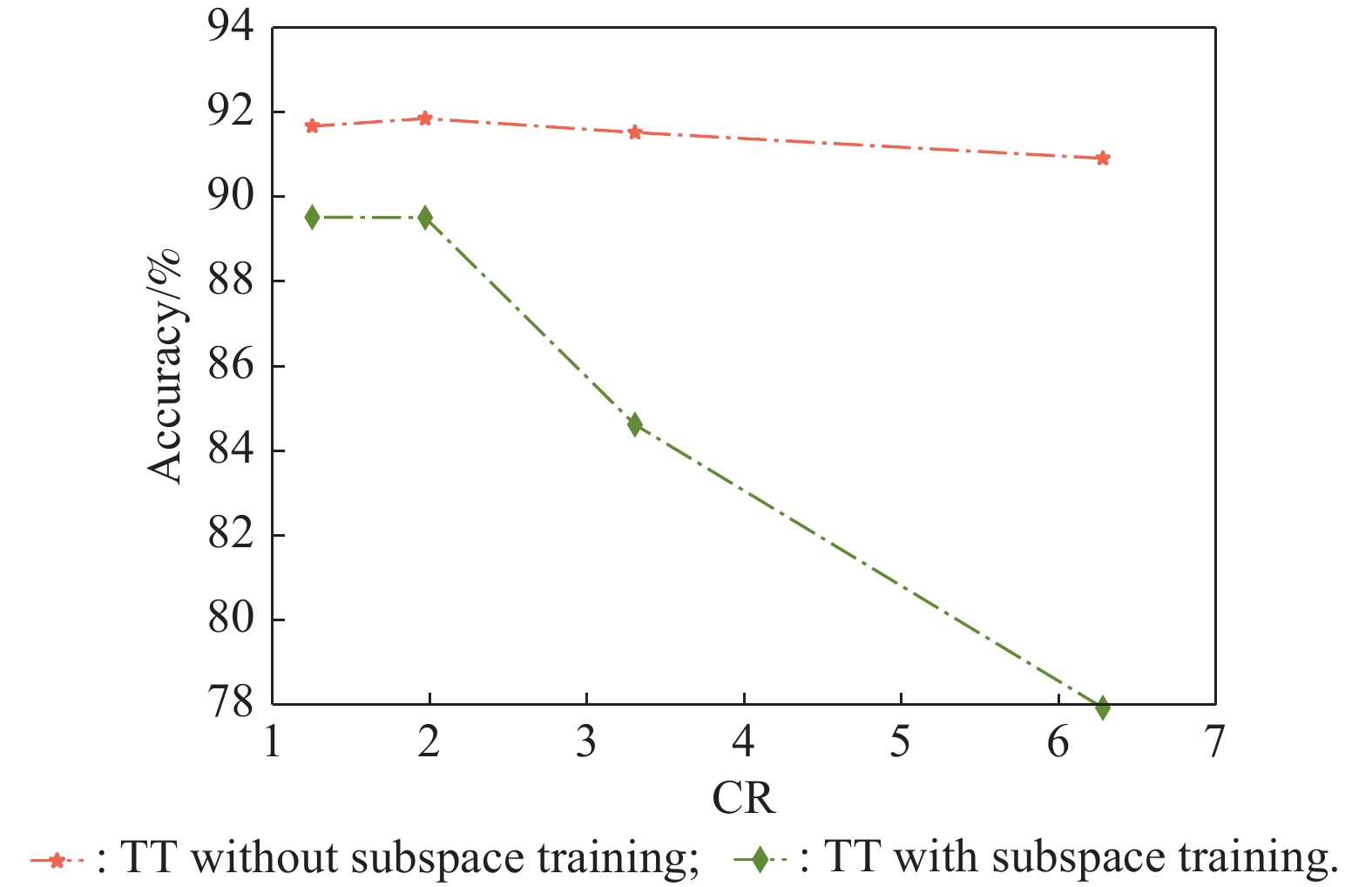
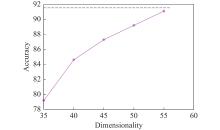
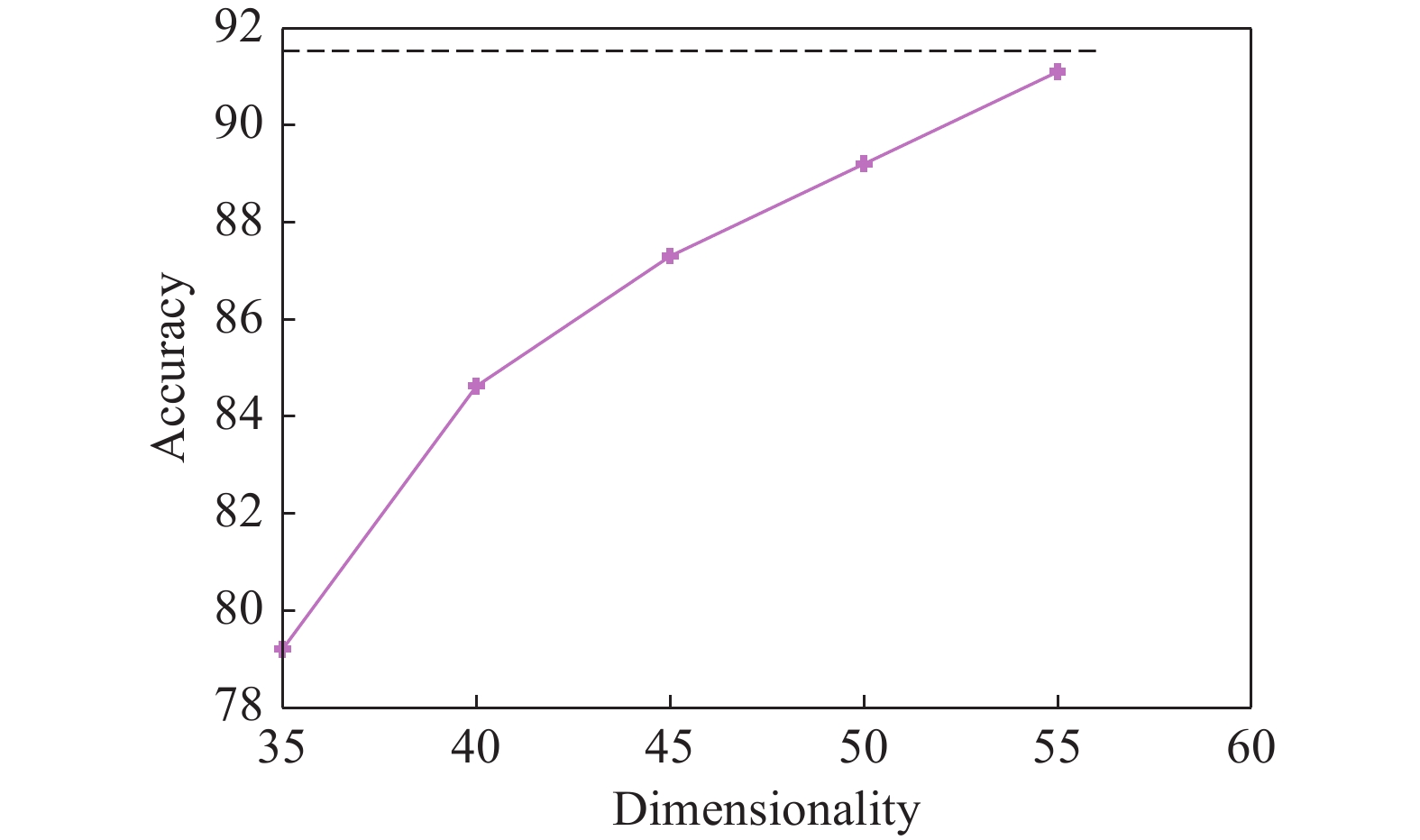
Fig 11
Effect of increasing the dimensionality of subspace on training TT-Nets in subspace"
| 1 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 2017, 60 (6): 84- 90. |
| 2 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition. https://arxiv.org/abs/1409.1556. |
| 3 | JIANG Y G, WU Z X, WANG J, et al Exploiting feature and class relationships in video categorization with regularized deep neural networks. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2017, 40 (2): 352- 364. |
| 4 | ZHANG Z H, LIU Y P, CAO X Y, et al. Scalable deep compressive sensing. https://arxiv.org/abs/2101.08024. |
| 5 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need. https://arxiv.org/abs/1706.03762. |
| 6 | GRAVES A, MOHAMED A R, HINTON G. Speech recognition with deep recurrent neural networks. Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2013: 6645−6649. |
| 7 | HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing coadaptation of feature detectors. https://arxiv.org/abs/1207.0580. |
| 8 | DENIL M, SHAKIBI B, DINH L, et al Predicting parameters in deep learning. Proc. of the 26th International Conference on Neural Information Processing Systems, 2023, 12 (2): 2148- 2156. |
| 9 | KIM Y D, PARK E, YOO S, et al. Compression of deep convolutional neural networks for fast and low power mobile applications. https://arxiv.org/abs/1511.06530. |
| 10 | LANE N D, BHATTACHARYA S, GEORGIEV P, et al. An early resource characterization of deep learning on wearables, smartphones and internet-of-things devices. Proc. of the International Workshop on Internet of Things Towards Applications, 2015: 7−12. |
| 11 | ABDUL HAMID N, MOHD NAWI N, GHAZALI R, et al. Accelerating learning performance of back propagation algorithm by using adaptive gain together with adaptive momentum and adaptive learning rate on classification problems. Proc. of the International Conference on Ubiquitous Computing and Multimedia Applications, 2011: 559−570. |
| 12 | LEBEDEV V, GANIN Y, RAKHUBA M, et al. Speeding-up convolutional neural networks using finetuned CP-decomposition. https://arxiv.org/abs/1412.6553v2 |
| 13 | JADERBERG M, VEDALDI A, ZISSERMAN A. Speeding up convolutional neural networks with low rank expansions. https://arxiv.org/abs/1405.3866. |
| 14 | WANG W Q, SUN Y F, ERIKSSON B, et al. Wide compression: tensor ring nets. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 9329−9338. |
| 15 | LIU Y P, LIU J N, LONG Z, et al. Tensor decomposition in deep networks. Tensor Computation for Data Analysis. Cham: Springer, 2022. |
| 16 | LUO J H, WU J X, LIN W Y. Thinet: a filter level pruning method for deep neural network compression. Proc. of the IEEE International Conference on Computer Vision, 2017: 5058−5066. |
| 17 | ZHANG T Y, YE S K, ZHANG K Q, et al. A systematic dnn weight pruning framework using alternating direction method of multipliers. Proc. of the European Conference on Computer Vision, 2018: 184−199. |
| 18 | ULLRICH K, MEEDS E, WELLING M. Soft weight sharing for neural network compression. https://arxiv.org/abs/1702.04008. |
| 19 | HUANG J Z, ZHANG T, METAXAS D Learning with structured sparsity. Journal of Machine Learning Research, 2011, 12 (103): 3371- 3412. |
| 20 | HAN S, MAO H Z, DALLY W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. https://arxiv.org/abs/1510.00149v4. |
| 21 | GONG Y C, LIU L, YANG M, et al. Compressing deep convolutional networks using vector quantization. https://arxiv.org/abs/1412.6115. |
| 22 | WU J X, LENG C, WANG Y H, et al. Quantized convolutional neural networks for mobile devices. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 4820−4828. |
| 23 | WANG M L, PAN Y, YANG X L, et al. Tensor networks meet neural networks: a survey. https://arxiv.org/abs/2302.09019. |
| 24 | RUDER S. An overview of gradient descent optimization algorithms. https://arxiv.org/abs/1609.04747. |
| 25 |
DENG L, LI G Q, HAN S, et al Model compression and hardware acceleration for neural networks: a comprehensive survey. Proceedings of the IEEE, 2020, 108 (4): 485- 532.
doi: 10.1109/JPROC.2020.2976475 |
| 26 |
CHOUDHARY T, MISHRA V, GOSWAMI A, et al A comprehensive survey on model compression and acceleration. Artificial Intelligence Review, 2020, 53 (7): 5113- 5155.
doi: 10.1007/s10462-020-09816-7 |
| 27 | LIU J N, ZHU C, LONG Z, et al. Tensor regression. https://arxiv.org/abs/2308.11419. |
| 28 | LIU Y P. Tensors for data processing: theory methods and applications. San Diego: Elsevier Science & Technology, 2021. |
| 29 | FENG L L, ZHU C, LONG Z, et al. Multiplex transformed tensor decomposition for multidimensional image recovery. IEEE Trans. on Image Processing, 2023, 32: 3397−3412. |
| 30 | ZHANG X Y, ZOU J H, HE K M, et al Accelerating very deep convolutional networks for classification and detection. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2015, 38 (10): 1943- 1955. |
| 31 | TUCKER L R Implications of factor analysis of three-way matrices for measurement of change. Problems in Measuring Change, 1963, 15, 122- 137. |
| 32 | GRASEDYCK L Hierarchical singular value decomposition of tensors. Society for Industrial and Applied Mathematics, 2010, 31 (4): 2029- 2054. |
| 33 |
OSELEDETS I V Tensor-train decomposition. Siam Journal on Scientific Computing, 2011, 33 (5): 2295- 2317.
doi: 10.1137/090752286 |
| 34 | ZHAO Q B, ZHOU G X, XIE S L, et al. Tensor ring decomposition. https://arxiv.org/abs/1606.05535. |
| 35 | DE LATHAUWER L. Decompositions of a higher-order tensor in block terms—part II: definitions and uniqueness. SIAM Journal on Matrix Analysis and Applications, 2008, 30(3). DOI: 10.1137/070690729. |
| 36 | HAMEED M G A, TAHAEI M S, MOSLEH A, et al. Convolutional neural network compression through generalized kronecker product decomposition. Proc. of the AAAI Conference on Artificial Intelligence, 2022: 771−779. |
| 37 | ZHAO H L, LIU Y P, HUANG X L, et al. Semi-tensor product-based tensor decomposition for neural network compression. https://arxiv.org/abs/2109.15200. |
| 38 | GARIPOV T, PODOPRIKHIN D, NOVIKOV A, et al. Ultimate tensorization: compressing convolutional and fc layers alike. https://arxiv.org/abs/1611.03214. |
| 39 |
YE J M, LI G X, CHEN D, et al Block-term tensor neural networks. Neural Networks, 2020, 130, 11- 21.
doi: 10.1016/j.neunet.2020.05.034 |
| 40 |
WU B J, WANG D H, ZHAO G S, et al Hybrid tensor decomposition in neural network compression. Neural Networks, 2020, 132, 309- 320.
doi: 10.1016/j.neunet.2020.09.006 |
| 41 | LIU Y P, LONG Z, HUANG H Y, et al Low CP rank and tucker rank tensor completion for estimating missing components in image data. IEEE Trans. on Circuits and Systems for Video Technology, 2019, 30 (4): 944- 954. |
| 42 |
TUCKER L R Some mathematical notes on three-mode factor analysis. Psychometrika, 1966, 31 (3): 279- 311.
doi: 10.1007/BF02289464 |
| 43 | LIU Y P, LONG Z, ZHU C Image completion using low tensor tree rank and total variation minimization. IEEE Trans. on Multimedia, 2018, 21 (2): 338- 350. |
| 44 |
LIU Y P, LIU J N, ZHU C Low-rank tensor train coefficient array estimation for tensor-on-tensor regression. IEEE Trans. on Neural Networks and Learning Systems, 2020, 31 (12): 5402- 5411.
doi: 10.1109/TNNLS.2020.2967022 |
| 45 | NOVIKOV A, PODOPRIKHIN D, OSOKIN A, et al. Tensorizing neural networks. https://arxiv.org/abs/1509.06569. |
| 46 | YIN M, SUI Y, YANG W Z, et al. HODEC: towards efficient high-order decomposed convolutional neural networks. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 12299−12308. |
| 47 |
HUANG H Y, LIU Y P, LONG Z, et al Robust low rank tensor ring completion. IEEE Trans. on Computational Imaging, 2020, 6, 1117- 1126.
doi: 10.1109/TCI.2020.3006718 |
| 48 | LIU J N, ZHU C, LIU Y P Smooth compact tensor ring regression. IEEE Trans. on Knowledge and Data Engineering, 2020, 34 (9): 4439- 4452. |
| 49 |
LONG Z, ZHU C, LIU J N, et al Bayesian low rank tensor ring for image recovery. IEEE Trans. on Image Processing, 2021, 30, 3568- 3580.
doi: 10.1109/TIP.2021.3062195 |
| 50 | THAKKER U, BEU J, GOPE D, et al. Compressing RNNs for IoT devices by 15−38x using Kronecker products. https://arxiv.org/abs/1906.02876. |
| 51 |
CHENG D Z, QI H S, XUE A C A survey on semi-tensor product of matrices. Journal of Systems Science and Complexity, 2007, 20 (2): 304- 322.
doi: 10.1007/s11424-007-9027-0 |
| 52 | LIEBENWEIN L, MAALOUF A, FELDMAN D, et al Compressing neural networks: towards determining the optimal layer-wise decomposition. Advances in Neural Information Processing Systems, 2021, 34, 5328- 5344. |
| 53 | IDELBAYEV Y, CARREIRA-PERPINÁN M A. Low-rank compression of neural nets: learning the rank of each layer. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 8049−8059. |
| 54 | YIN M, SUI Y, LIAO S Y, et al. Towards efficient tensor decomposition-based dnn model compression with optimization framework. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 10674−10683. |
| 55 | YIN M, PHAN H, ZANG X, et al. BATUDE: budget-aware neural network compression based on tucker decomposition. Proc. of the AAAI Conference on Artificial Intelligence, 36(8): 8874−8882. |
| 56 | NAKAJIMA S, SUGIYAMA M, BABACAN S D, et al Global analytic solution of fully-observed variational bayesian matrix factorization. The Journal of Machine Learning Research, 2013, 14 (1): 1- 37. |
| 57 | REEVES C R. Modern heuristic techniques for combinatorial problems. New York: John Wiley & Sons, 1993. |
| 58 | CHENG Z Y, LI B P, FAN Y W, et al. A novel rank selection scheme in tensor ring decomposition based on reinforcement learning for deep neural networks. Proc. of the ICASSP IEEE International Conference on Acoustics, 2020: 3292−3296. |
| 59 | SAMRAGH M, JAVAHERIPI M, KOUSHANFAR F. AutoRank: automated rank selection for effffective neural network customization. Proc. of the ML-for Systems Workshop at the 46th International Symposium on Computer Architecture, 2019. DOI: 10.1109/JETCAS.2021.3127433. |
| 60 |
MITCHELL B C, BURDICK D S Slowly converging parafac sequences: swamps and two-factor degeneracies. Journal of Chemometrics, 1994, 8 (2): 155- 168.
doi: 10.1002/cem.1180080207 |
| 61 | HARSHMAN R A. The problem and nature of degenerate solutions or decompositions of 3-way arrays. https://www.psychology.uwo.ca/faculty/harshman/aim2004.pdf. |
| 62 |
KRIJNEN W P, DIJKSTRA T K, STEGEMAN A On the non-existence of optimal solutions and the occur rence of degeneracy in the candecomp/parafac model. Psychometrika, 2008, 73 (3): 431- 439.
doi: 10.1007/s11336-008-9056-1 |
| 63 | DENTON E L, ZAREMBA W, BRUNA J, et al. Exploiting linear structure within convolutional networks for efficient evaluation. https://arxiv.org/abs/1404.0736. |
| 64 | ASTRID M, LEE S I. CP-decomposition with tensor power method for convolutional neural networks compression. Proc. of the IEEE International Conference on Big Data and Smart Computing, 2017: 115−118. |
| 65 | ALLEN G. Sparse higher-order principal components analysis. Proc. of the Artifificial Intelligence and Statistics, 2012: 27−36. |
| 66 | PHAN A H, SOBOLEV K, SOZYKIN K, et al. Stable low-rank tensor decomposition for compression of con volutional neural network. Proc. of the European Conference on Computer Vision, 2020: 522−539. |
| 67 | VEERAMACHENENI L, WOLTER M, KLEIN R, et al. Canonical convolutional neural networks. https://arxiv.org/abs/2206.01509v1. |
| 68 |
KOLDA T G, BADER B W Tensor decompositions and applications. SIAM Review, 2009, 51 (3): 455- 500.
doi: 10.1137/07070111X |
| 69 |
ESPIG M, HACKBUSCH W, HANDSCHUH S, et al Optimization problems in contracted tensor networks. Computing and Visualization in Science, 2011, 14 (6): 271- 285.
doi: 10.1007/s00791-012-0183-y |
| 70 | PHAN A H, SOBOLEV K, ERMILOV D, et al. How to train unstable looped tensor network. https://arxiv.org/abs/2203.02617. |
| 71 | GLOROT X, BENGIO Y. Understanding the difficulty of training deep feed forward neural networks. Journal of Machine Learning Research, 2010: 249−256. |
| 72 | PAN Y, SU Z Y, LIU A, et al. A unified weight initialization paradigm for tensorial convolutional neural networks. Proc. of the International Conference on Machine Learning, 2022: 17238−17257. |
| 73 | ZOPH B, LE Q V. Neural architecture search with reinforcement learning. https://arxiv.org/abs/1611.01578. |
| 74 | LI N N, PAN Y, CHEN Y R, et al Heuristic rank selection with progressively searching tensor ring network. Complex & Intelligent Systems, 2022, 8 (2): 771- 785. |
| 75 |
DEB K, PRATAP A, AGARWAL S, et al A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans. on Evolutionary Computation, 2002, 6 (2): 182- 197.
doi: 10.1109/4235.996017 |
| 76 |
HAWKINS C, ZHANG Z Bayesian tensorized neural networks with automatic rank selection. Neurocomputing, 2021, 453, 172- 180.
doi: 10.1016/j.neucom.2021.04.117 |
| 77 | RAI P, WANG Y J, GUO S B, et al. Scalable bayesian low-rank decomposition of incomplete multiway tensors. Proc. of the International Conference on Machine Learning, 2014: 1800−1808. |
| 78 | GUHANIYOGI R, QAMAR S, DUNSON D B Bayesian tensor regression. The Journal of Machine Learning Research, 2017, 18 (1): 2733- 2763. |
| 79 |
BAZERQUE J A, MATEOS G, GIANNAKIS G B Rank regularization and bayesian inference for tensor completion and extrapolation. IEEE Trans. on Signal Processing, 2013, 61 (22): 5689- 5703.
doi: 10.1109/TSP.2013.2278516 |
| 80 |
EO M, KANG S, RHEE W An effective low-rank compression with a joint rank selection followed by a compression-friendly training. Neural Networks, 2023, 161, 165- 177.
doi: 10.1016/j.neunet.2023.01.024 |
| 81 | CAI J F, CANDÈS E J, SHEN Z W. A singular value thresholding algorithm for matrix completion. https://arxiv.org/abs/0810.3286. |
| 82 | ALVAREZ J M, SALZMANN M. Compression-aware training of deep networks. https://arxiv.org/abs/1711.02638. |
| 83 | XU Y H, LI Y X, ZHANG S, et al. Trained rank pruning for efficient deep neural networks. Proc. of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition, 2019: 14−17. |
| 84 | AVRON H, KALE S, KASIVISWANATHAN S, et al. Efficient and practical stochastic subgradient descent for nuclear norm regularization. https://arxiv.org/abs/1206.6384. |
| 85 | YANG H R, TANG M X, WEN W, et al. Learning low-rank deep neural networks via singular vector orthogonality regularization and singular value sparsification. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 678−679. |
| 86 | CARREIRA-PERPINÁN M A, IDELBAYEV Y. Learning-compression algorithms for neural net pruning. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8532−8541. |
| 87 | ZIMMER M, SPIEGEL C, POKUTTA S. Compression aware training of neural networks using Frank-Wolfe. https://arxiv.org/abs/2205.11921. |
| 88 | SHI L, HUANG X L, FENG Y L, et al Sparse kernel regression with coefficient-based ℓq-regularization. Journal of Machine Learning Research, 2019, 20 (161): 1- 44. |
| 89 |
XU P, TIAN Y, CHEN H F, et al ℓp norm iterative sparse solution for EEG source localization. IEEE Trans. on Biomedical Engineering, 2007, 54 (3): 400- 409.
doi: 10.1109/TBME.2006.886640 |
| 90 | BOGDAN M, BERG E V D, SU W, et al. Statistical estimation and testing via the sorted ℓ1 norm. https://arxiv.org/abs/1310.1969. |
| 91 |
HUANG X L, LIU Y P, SHI L, et al Two-level ℓ1 minimization for compressed sensing. Signal Processing, 2015, 108, 459- 475.
doi: 10.1016/j.sigpro.2014.09.028 |
| 92 |
DALTON H The measurement of the inequality of incomes. The Economic Journal, 1920, 30 (119): 348- 361.
doi: 10.2307/2223525 |
| 93 |
LORENZ M O Methods of measuring the concentration of wealth. Publications of the American statistical association, 1905, 9 (70): 209- 219.
doi: 10.1080/15225437.1905.10503443 |
| 94 | RICKARD S. Sparse sources are separated sources. Proc. of the 14th European signal processing conference, 2006: 1−5. |
| 95 | HURLEY N, RICKARD S, CURRAN P. Parameterized lifting for sparse signal representations using the gini index. Proc. of the Signal Processing with Adaptative Sparse Structured Representations Conference, 2005. http://spars05.irisoa.fr/ACTES/TS4-4.pdf. |
| 96 | HOYER P O Non-negative matrix factorization with sparseness constraints. Journal of Machine Learning Research, 2004, 5 (9): 1457- 1469. |
| 97 | ROY O, VETTERLI M. The effective rank: a measure of effective dimensionality. Proc. of the 15th European signal processing conference, 2007: 606−610. |
| 98 |
CHEN Z, CHEN Z B, LIN J X, et al Deep neural network acceleration based on low-rank approximated channel pruning. IEEE Trans. on Circuits and Systems I: Regular Papers, 2020, 67 (4): 1232- 1244.
doi: 10.1109/TCSI.2019.2958937 |
| 99 | OSAWA K, YOKOTA R. Evaluating the compression efficiency of the filters in convolutional neural networks. Proc. of the International Conference on Artificial Neural Networks, 2017: 459−466. |
| 100 | BLALOCK D, GONZALEZ ORTIZ J J, FRANKLE J, et al. What is the state of neural network pruning? https://arxiv.org/abs/2003.03033. |
| 101 | CHEN W L, WILSON J, TYREE S, et al. Compressing neural networks with the hashing trick. Proc. of the International Conference on Machine Learning, 2015: 2285−2294. |
| 102 | HAN S, POOL J, TRAN J, et al Learning both weights and connections for efficient neural network. Proc. of the 28th International Conference on Neural Information Processing Systems, 2015, 1, 1135- 1143. |
| 103 | RUAN X F, LIU Y F, YUAN C F, et al EDP: an efficient decomposition and pruning scheme for convolutional neural network compression. IEEE Trans. on Neural Networks and Learning Systems, 2020, 32 (10): 4499- 4513. |
| 104 |
SWAMINATHAN S, GARG D, KANNAN R, et al Sparse low rank factorization for deep neural network compression. Neurocomputing, 2020, 398, 185- 196.
doi: 10.1016/j.neucom.2020.02.035 |
| 105 | LIU B Y, WANG M, FOROOSH H, et al. Sparse convolutional neural networks. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 806−814. |
| 106 | WEN W J, YANG F, SU Y F, et al. Learning low-rank structured sparsity in recurrent neural networks. Proc. of the IEEE International Symposium on Circuits and Systems, 2020. DOI: 10.1109/ISCAS45731.2020.9181239. |
| 107 | OBUKHOV A, RAKHUBA M, GEORGOULIS S, et al. T-basis: a compact representation for neural networks. Proc. of the International Conference on Machine Learning, 2020: 7392−7404. |
| 108 | LI Y W, GU S H, GOOL L V, et al. Learning filter basis for convolutional neural network compression. Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 5623−5632. |
| 109 | SUN W Z, CHEN S W, HUANG L, et al Deep convolutional neural network compression via coupled tensor decomposition. IEEE Journal of Selected Topics in Signal Processing, 2020, 15 (3): 603- 616. |
| 110 | LI T H, LI J G, LIU Z, et al. Few sample knowledge distillation for efficient network compression. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 14639−14647. |
| 111 | LIN S H, JI R R, CHEN C, et al Holistic CNN compression via low-rank decomposition with knowledge transfer. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018, 41 (12): 2889- 2905. |
| 112 | SADHUKHAN R, SAHA A, MUKHOPADHYAY J, et al. Knowledge distillation inspired fine-tuning of tucker decomposed cnns and adversarial robustness analysis. Proc. of the IEEE International Conference on Image Processing, 2020: 1876−1880. |
| 113 |
LEE D, WANG D H, YANG Y K, et al QTTNET: quantized tensor train neural networks for 3D object and video recognition. Neural Networks, 2021, 141, 420- 432.
doi: 10.1016/j.neunet.2021.05.034 |
| 114 | KUZMIN A, VAN BAALEN M, NAGEL M, et al. Quantized sparse weight decomposition for neural network compression. https://arxiv.org/abs/2207.11048v1. |
| 115 |
NEKOOEI A, SAFARI S Compression of deep neural networks based on quantized tensor decomposition to implement on reconfigurable hardware platforms. Neural Networks, 2022, 150, 350- 363.
doi: 10.1016/j.neunet.2022.02.024 |
| 116 |
CHOI Y, EL-KHAMY M, LEE J Universal deep neural network compression. IEEE Journal of Selected Topics in Signal Processing, 2020, 14 (4): 715- 726.
doi: 10.1109/JSTSP.2020.2975903 |
| 117 |
WIEDEMANN S, KIRCHHOFFER H, MATLAGE S, et al Deepcabac: a universal compression algorithm for deep neural networks. IEEE Journal of Selected Topics in Signal Processing, 2020, 14 (4): 700- 714.
doi: 10.1109/JSTSP.2020.2969554 |
| 118 | CHEN C Y, WANG Z, CHEN X W, et al. Efficient tunstall decoder for deep neural network compression. Proc. of the 58th ACM/IEEE Design Automation Conference, 2021: 1021−1026. |
| 119 | HAN S, LIU X Y, MAO H Z, et al. EIE: efficient inference engine on compressed deep neural network. Proc. of the ACM/IEEE 43rd Annual International Symposium on Computer Architecture. DOI: 10.1109/ISCA.2016.30. |
| 120 | CHEN S, ZHAO Q Shallowing deep networks: Layerwise pruning based on feature representations. IEEE Trans. on pattern analysis and machine intelligence, 2018, 41 (12): 3048- 3056. |
| 121 | HUANG Q G, ZHOU K, YOU S, et al. Learning to prune filters in convolutional neural networks. Proc. of the IEEE Winter Conference on Applications of Computer Vision, 2018: 709−718. |
| 122 | GOYAL S, CHOUDHURY A R, SHARMA V. Compression of deep neural networks by combining pruning and low rank decomposition. Proc. of the IEEE International Parallel and Distributed Processing Symposium Workshops, 2019: 952−958. |
| 123 | MOLCHANOV P, TYREE S, KARRAS T, et al. Pruning convolutional neural networks for resource efficient inference. https://arxiv.org/abs/1611.06440. |
| 124 | ALVAREZ J M, SALZMANN M. Learning the number of neurons in deep networks. https://arxiv.org/abs/1611.06321v1. |
| 125 | KUMAR A. Vision transformer compression with structured pruning and low rank approximation. https://arxiv.org/abs/2203.13444. |
| 126 | LIU X, SMELYANSKIY M, CHOW E, et al. Efficient sparse matrix-vector multiplication on x86-based manycore processors. Proc. of the 27th International ACM Conference on on Supercomputing, 2013: 273−282. |
| 127 |
ZOU H, HASTIE T, TIBSHIRANI R Sparse principal component analysis. Journal of computational and graphical statistics, 2006, 15 (2): 265- 286.
doi: 10.1198/106186006X113430 |
| 128 | LEBEDEV V, LEMPITSKY V. Fast convnets using group-wise brain damage. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2554−2564. |
| 129 |
LECUN Y, BENGIO Y, HINTON G Deep learning. Nature, 2015, 521 (7553): 436- 444.
doi: 10.1038/nature14539 |
| 130 | HINTON G, VINYALS O, DEAN J, et al. Distilling the knowledge in a neural network. https://arxiv.org/abs/1503.02531. |
| 131 |
CHAUDHURI R, FIETE I Computational principles of memory. Nature Neuroscience, 2016, 19 (3): 394- 403.
doi: 10.1038/nn.4237 |
| 132 |
FAISAL A A, SELEN L P, WOLPERT D M Noise in the nervous system. Nature Reviews Neuroscience, 2008, 9 (4): 292- 303.
doi: 10.1038/nrn2258 |
| 133 | VANRULLEN R, KOCH C. Is perception discrete or continuous? Trends in Cognitive Sciences, 2003, 7(5): 207−213. |
| 134 | TEE J, TAYLOR D P Is information in the brain represented in continuous or discrete form? IEEE Trans. on Molecular, Biological and Multi-Scale Communications, 2020, 6 (3): 199- 209. |
| 135 |
KHAW M W, STEVENS L, WOODFORD M Discrete adjustment to a changing environment: experimental evidence. Journal of Monetary Economics, 2017, 91, 88- 103.
doi: 10.1016/j.jmoneco.2017.09.001 |
| 136 |
LATIMER K W, YATES J L, MEISTER M L, et al Single-trial spike trains in parietal cortex reveal discrete steps during decision-making. Science, 2015, 349 (6244): 184- 187.
doi: 10.1126/science.aaa4056 |
| 137 |
VARSHNEY L R, SJÖSTRÖM P J, CHKLOVSKII D B Optimal information storage in noisy synapses under resource constraints. Neuron, 2006, 52 (3): 409- 423.
doi: 10.1016/j.neuron.2006.10.017 |
| 138 | LIN D, TALATHI S, ANNAPUREDDY S. Fixed point quantization of deep convolutional networks. Proc. of the International Conference on Machine Learning, 2016: 2849−2858. |
| 139 | GHOLAMI A, KIM S, DONG Z, et al. A survey of quantization methods for efficient neural network inference. https://arxiv.org/abs/2103.13630. |
| 140 | NAGEL M, FOURNARAKIS M, AMJAD R A, et al. A white paper on neural network quantization. https://arxiv.org/abs/2106.08295. |
| 141 | KOZYRSKIY N, PHAN A H. CNN acceleration by lowrank approximation with quantized factors. https://arxiv.org/abs/2006.08878. |
| 142 | RECANATESI S, FARRELL M, ADVANI M, et al. Dimensionality compression and expansion in deep neural networks. https://arxiv.org/abs/1906.00443v1. |
| 143 |
ZIV J, LEMPEL A A universal algorithm for sequential data compression. IEEE Trans. on information theory, 1977, 23 (3): 337- 343.
doi: 10.1109/TIT.1977.1055714 |
| 144 |
ZIV J, LEMPEL A Compression of individual sequences via variable-rate coding. IEEE Trans. on Information Theory, 1978, 24 (5): 530- 536.
doi: 10.1109/TIT.1978.1055934 |
| 145 |
WELCH T A A technique for high-performance data compression. Computer, 1984, 17 (6): 8- 19.
doi: 10.1109/MC.1984.1659158 |
| 146 |
EFFROS M, VISWESWARIAH K, KULKARNI S R, et al Universal lossless source coding with the burrows wheeler transform. IEEE Trans. on Information Theory, 2002, 48 (5): 1061- 1081.
doi: 10.1109/18.995542 |
| 147 | COSSON R, JADBABAIE A, MAKUR A, et al. Gradient descent for low-rank functions. https://arxiv.org/abs/2206.08257. |
| 148 | LOGAN B F, SHEPP L A Optimal reconstruction of a function from its projections. Duke Mathematical Journal, 1975, 42 (4): 645- 659. |
| 149 | DONOHO D L, JOHNSTONE I M. Projection-based approximation and a duality with kernel methods. The Annals of Statistics, 1989: 58−106. |
| 150 |
CONSTANTINE P G, EMORY M, LARSSON J, et al Exploiting active subspaces to quantify uncertainty in the numerical simulation of the HyShot II scramjet. Journal of Computational Physics, 2015, 302, 1- 20.
doi: 10.1016/j.jcp.2015.09.001 |
| 151 |
LIU Y P, DE VOS M, GLIGORIJEVIC I, et al Multistructural signal recovery for biomedical compressive sensing. IEEE Trans. on Biomedical Engineering, 2013, 60 (10): 2794- 2805.
doi: 10.1109/TBME.2013.2264772 |
| 152 | GUR-ARI G, ROBERTS D A, DYER E. Gradient descent happens in a tiny subspace. https://arxiv.org/abs/1812.04754. |
| 153 | KINGMA D P, BA J. Adam: a method for stochastic optimization. https://arxiv.org/abs/1412.6980. |
| 154 | DAUPHIN Y, DE VRIES H, BENGIO Y Equilibrated adaptive learning rates for non-convex optimization. Proc. of the 28th International Conference on Neural Information Processing Systems, 2015, 1, 1504- 1512. |
| 155 | DUCHI J, HAZAN E, SINGER Y Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 2011, 12 (7): 2121- 2159. |
| 156 | BYRD R H, NOCEDAL J, SCHNABEL R B Representations of quasi-Newton matrices and their use in limited memory methods. Mathematical Programming, 1994, 63 (1): 129- 156. |
| 157 | LI T, TAN L, HUANG Z H, et al. Low dimensional trajectory hypothesis is true: DNNs can be trained in tiny subspaces. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2022, 45(3): 3411−3420. |
| 158 |
SZE V, CHEN Y H, YANG T J, et al How to evaluate deep neural network processors: TOPS/W (alone) considered harmful. IEEE Solid-State Circuits Magazine, 2020, 12 (3): 28- 41.
doi: 10.1109/MSSC.2020.3002140 |
| 159 | HOROWITZ M. 1.1 computing’s energy problem (and what we can do about it). Proc. of the IEEE International Solid-State Circuits Conference Digest of Technical Papers, 2014: 10−14. |
| 160 |
SZE V, CHEN Y H, YANG T J, et al Efficient processing of deep neural networks: a tutorial and survey. Proceedings of the IEEE, 2017, 105 (12): 2295- 2329.
doi: 10.1109/JPROC.2017.2761740 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||