
Journal of Systems Engineering and Electronics ›› 2021, Vol. 32 ›› Issue (4): 927-938.doi: 10.23919/JSEE.2021.000079
• CONTROL THEORY AND APPLICATION • Previous Articles Next Articles
Xin ZENG( ), Yanwei ZHU*(), Leping YANG(), Chengming ZHANG()
), Yanwei ZHU*(), Leping YANG(), Chengming ZHANG()
Received:2020-11-12
Online:2021-08-18
Published:2021-09-30
Contact:
Yanwei ZHU
E-mail:xzavier0214@outlook.com;zywnudt@163.com;ylpnudt@163.com;zhchm_vincent@163.com
About author:Supported by:Xin ZENG, Yanwei ZHU, Leping YANG, Chengming ZHANG. A guidance method for coplanar orbital interception based on reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32(4): 927-938.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
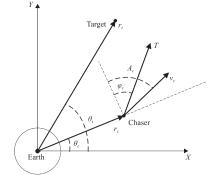
Fig 1
Coplanar coordinates, state variables, and control variables"
Fig 2
Structure of the actor and the critic networks"
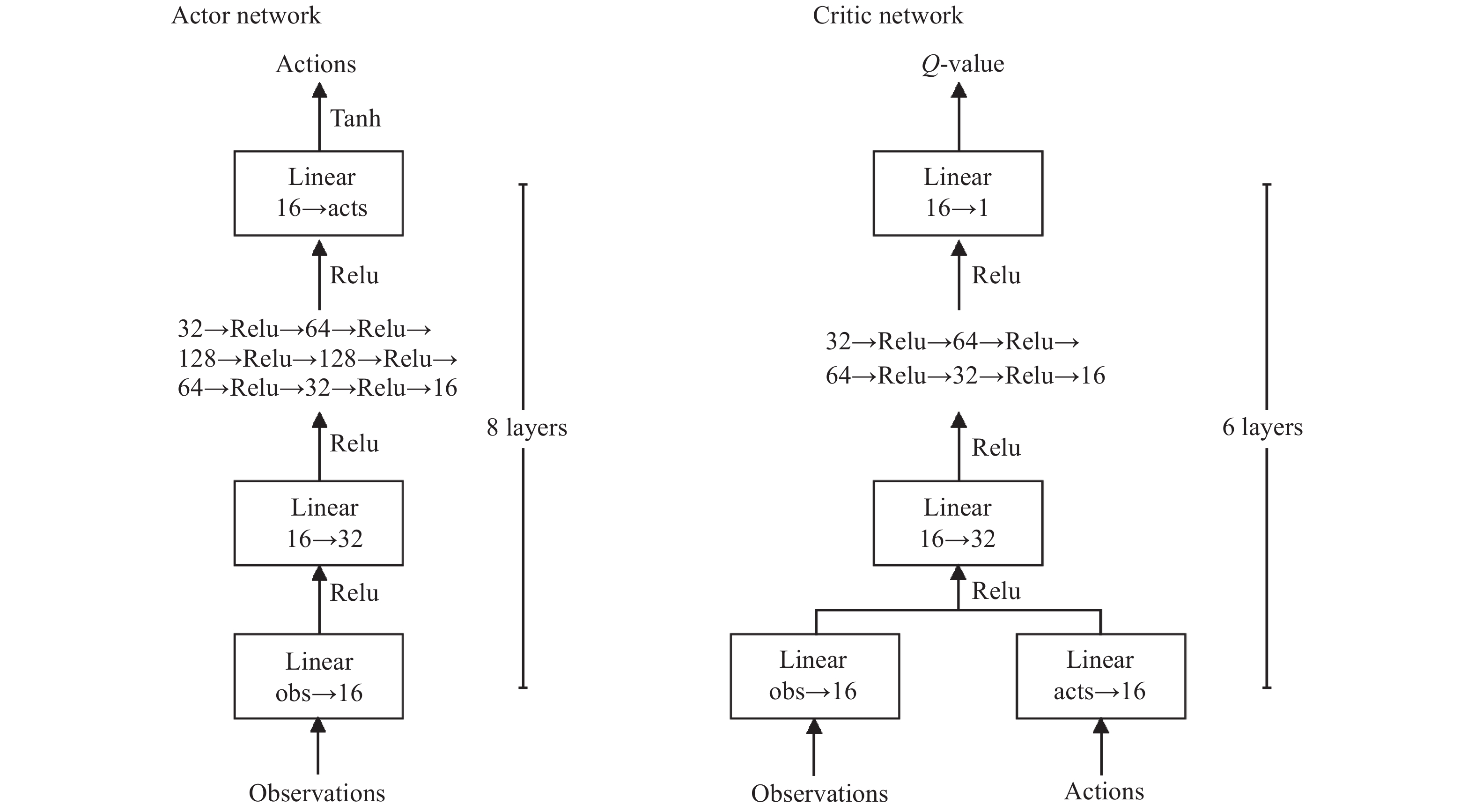
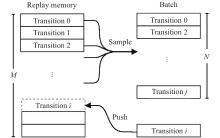
Fig 3
Replay memory"
Fig 4
Trajectory results of three cases with equidifferent azimuths"
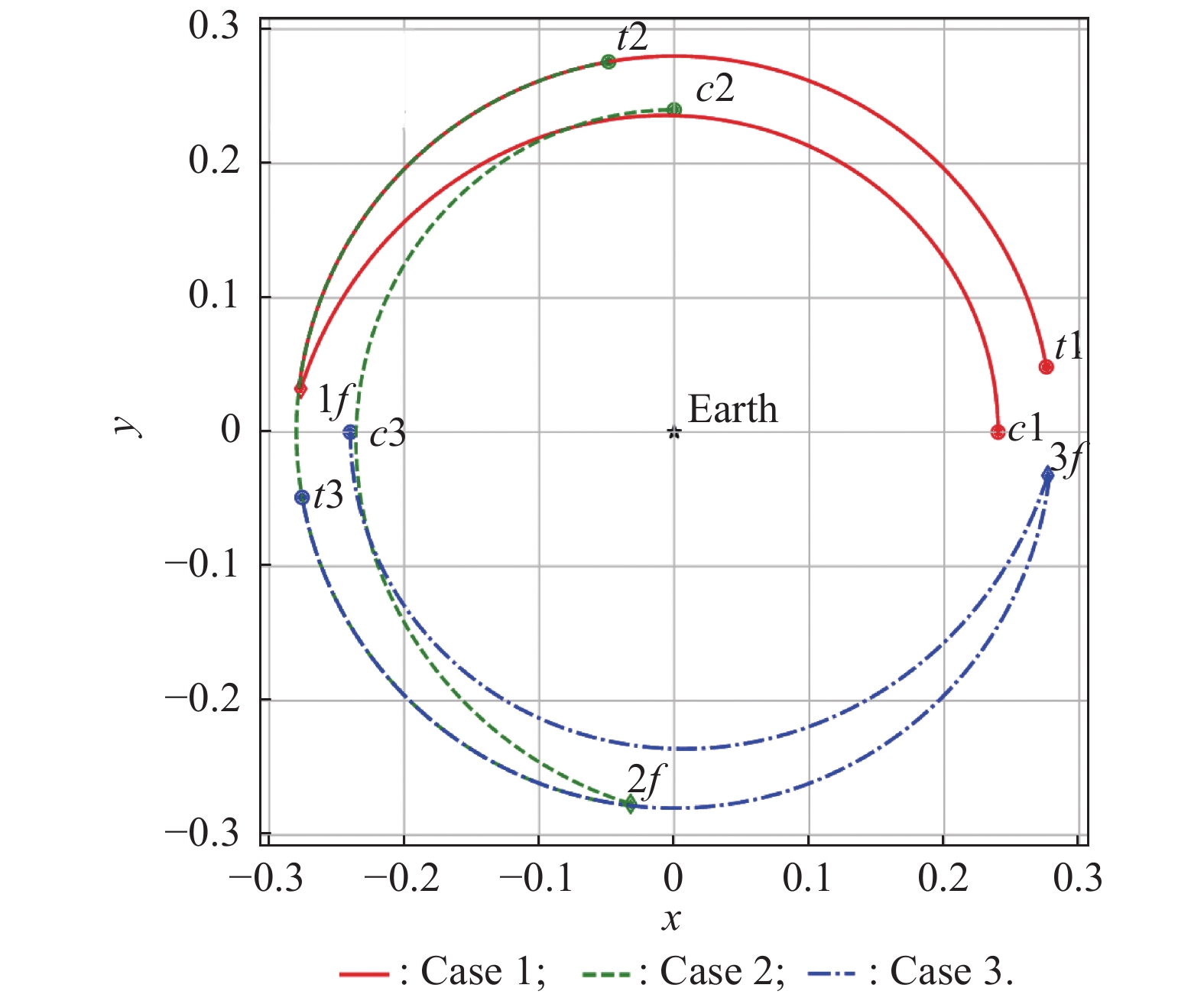
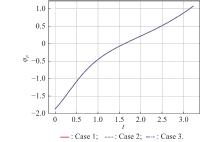
Fig 5
Control variable vs. time for three cases with equidifferent azimuths"
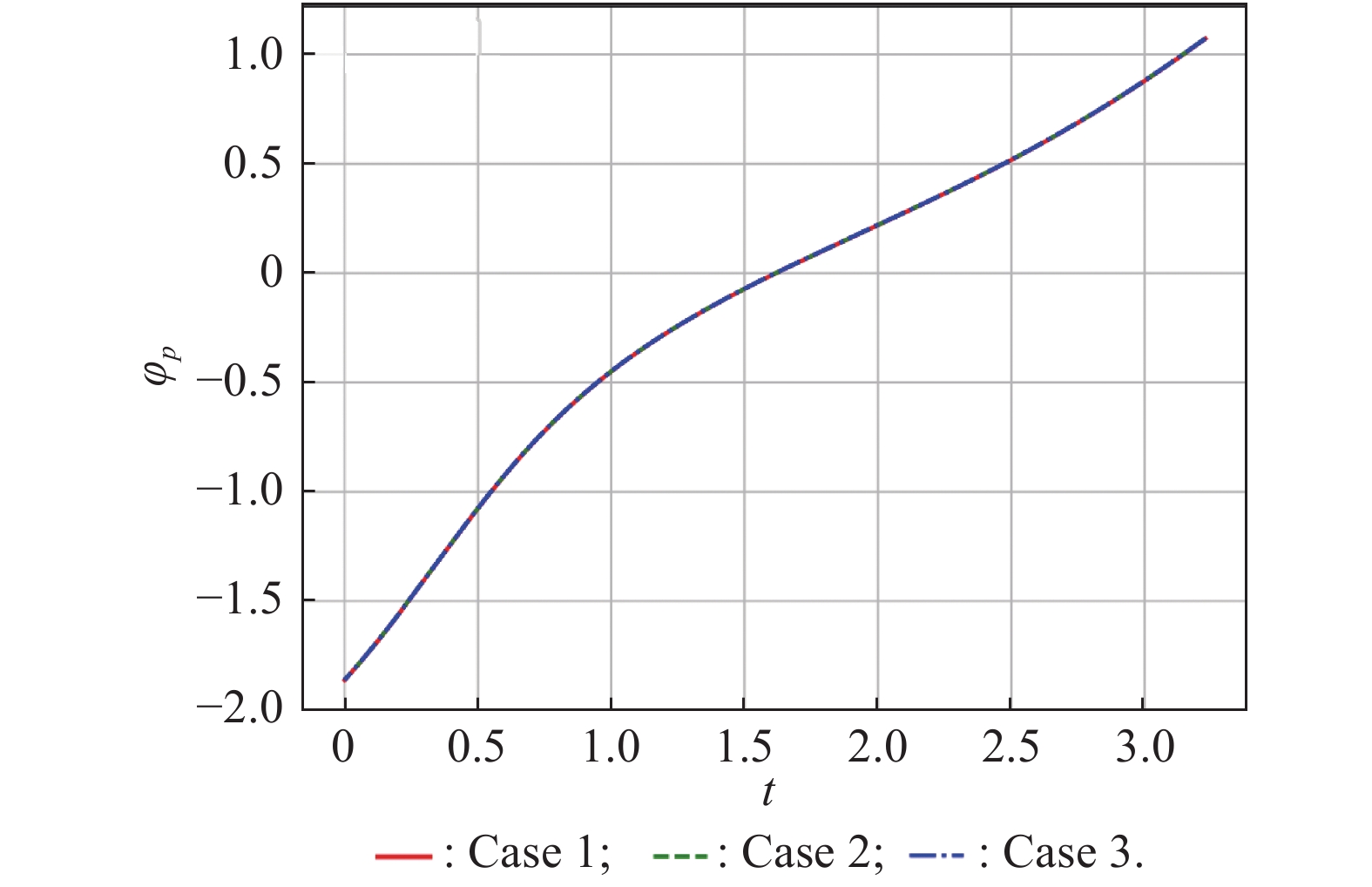
Fig 6
Normalized terminal time vs. initial difference of the azimuth"
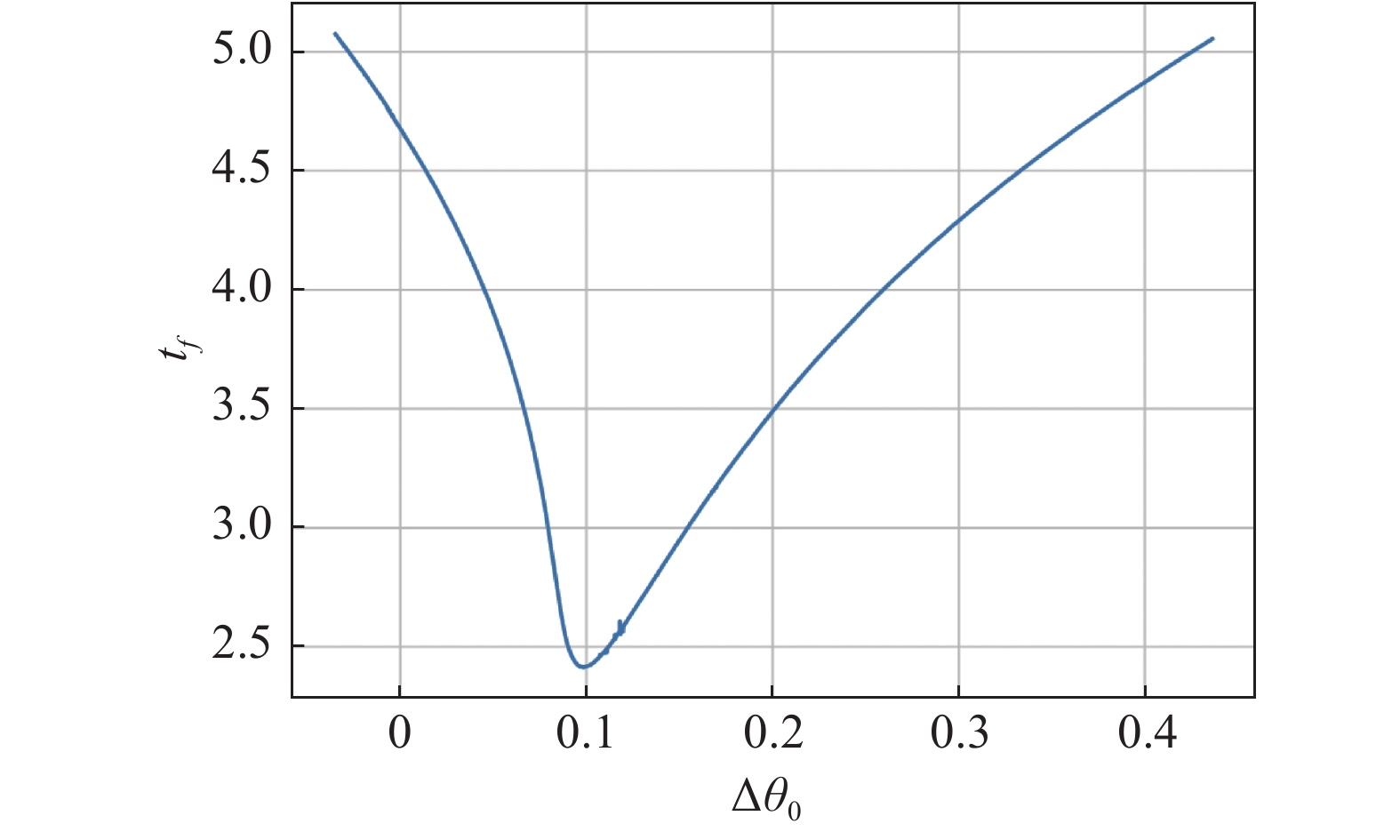
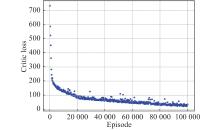
Fig 7
Critic loss vs. episode"
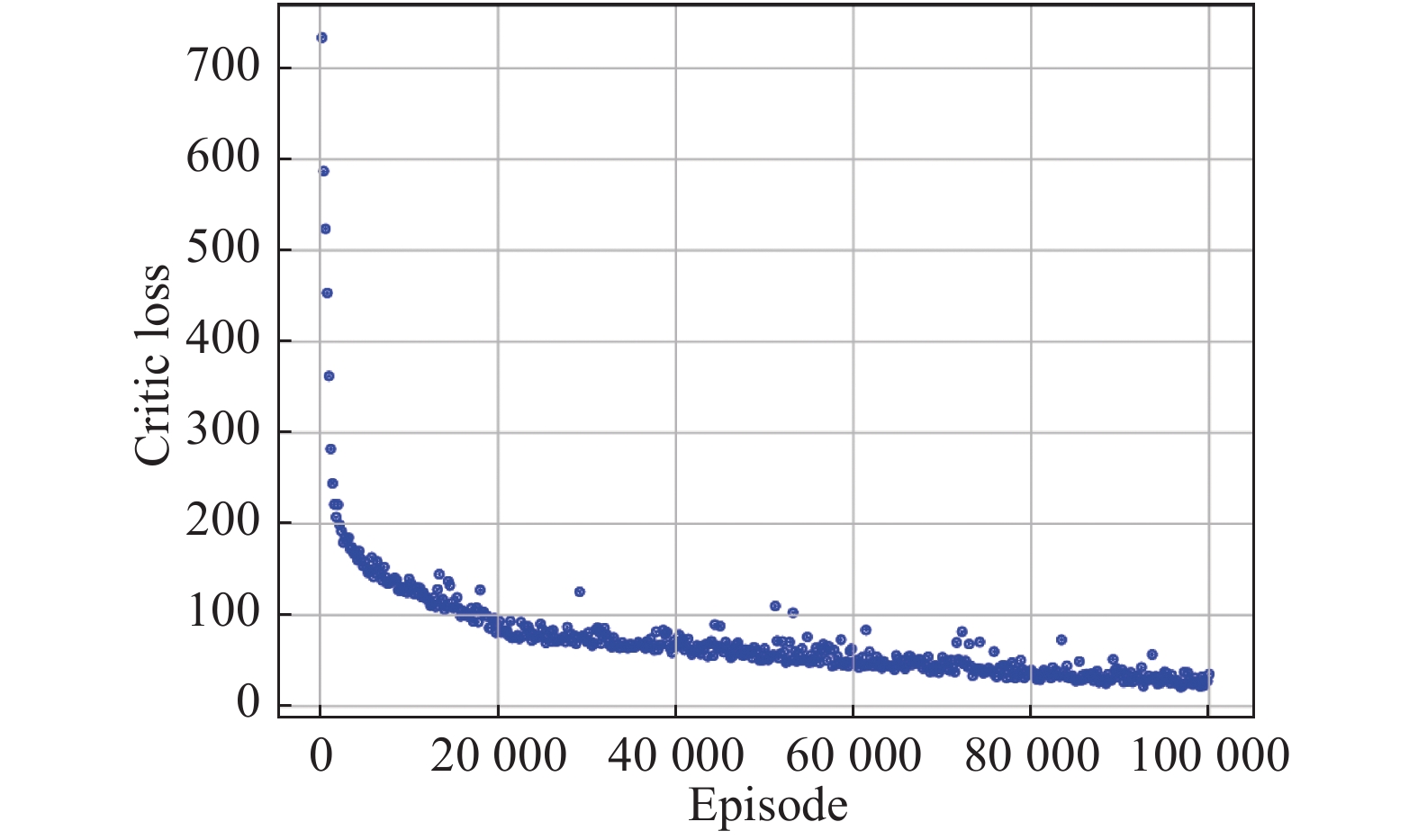
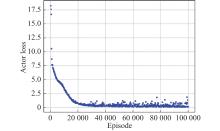
Fig 8
Actor loss vs. episode"
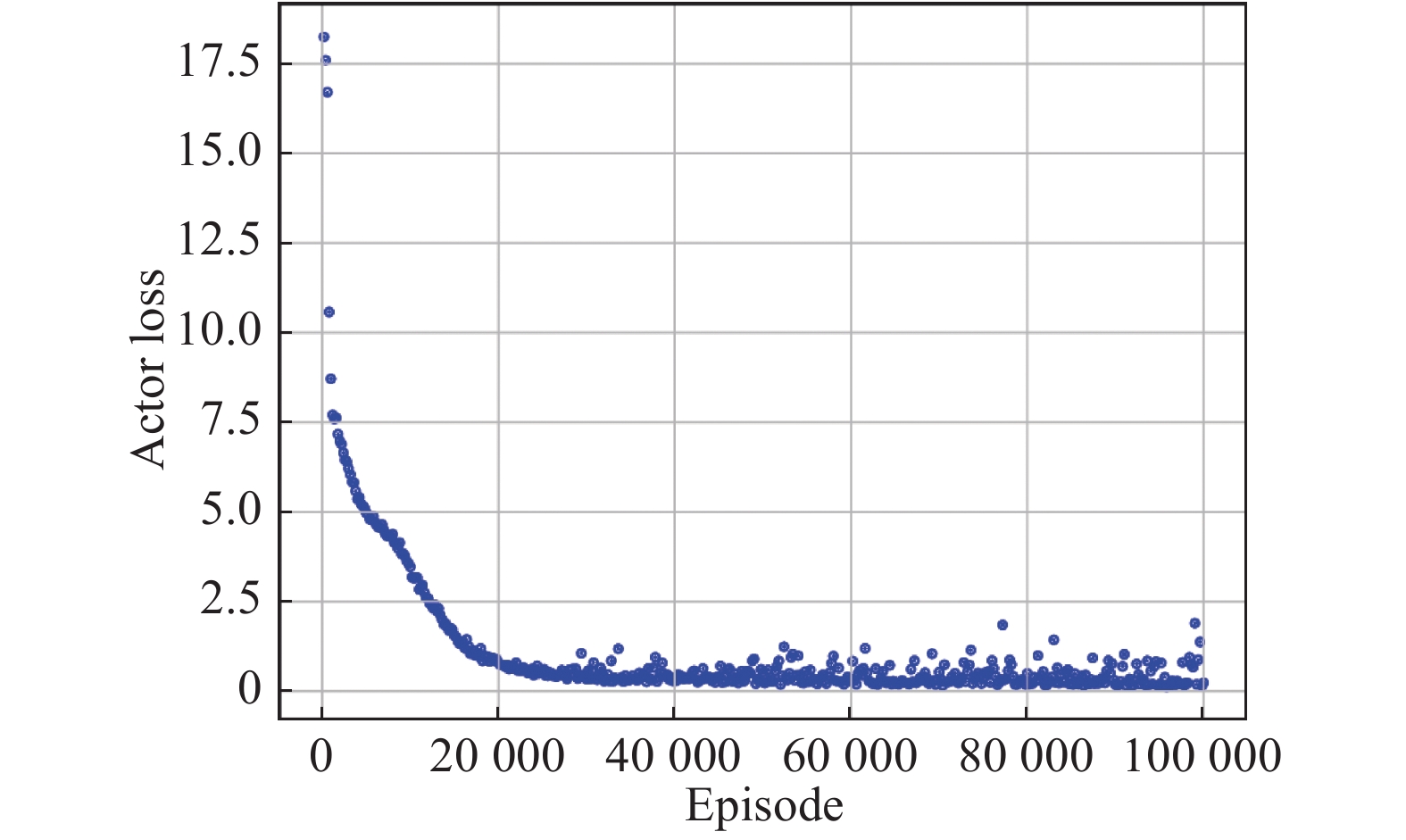
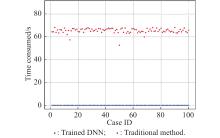
Fig 9
Comparison on time consumption"
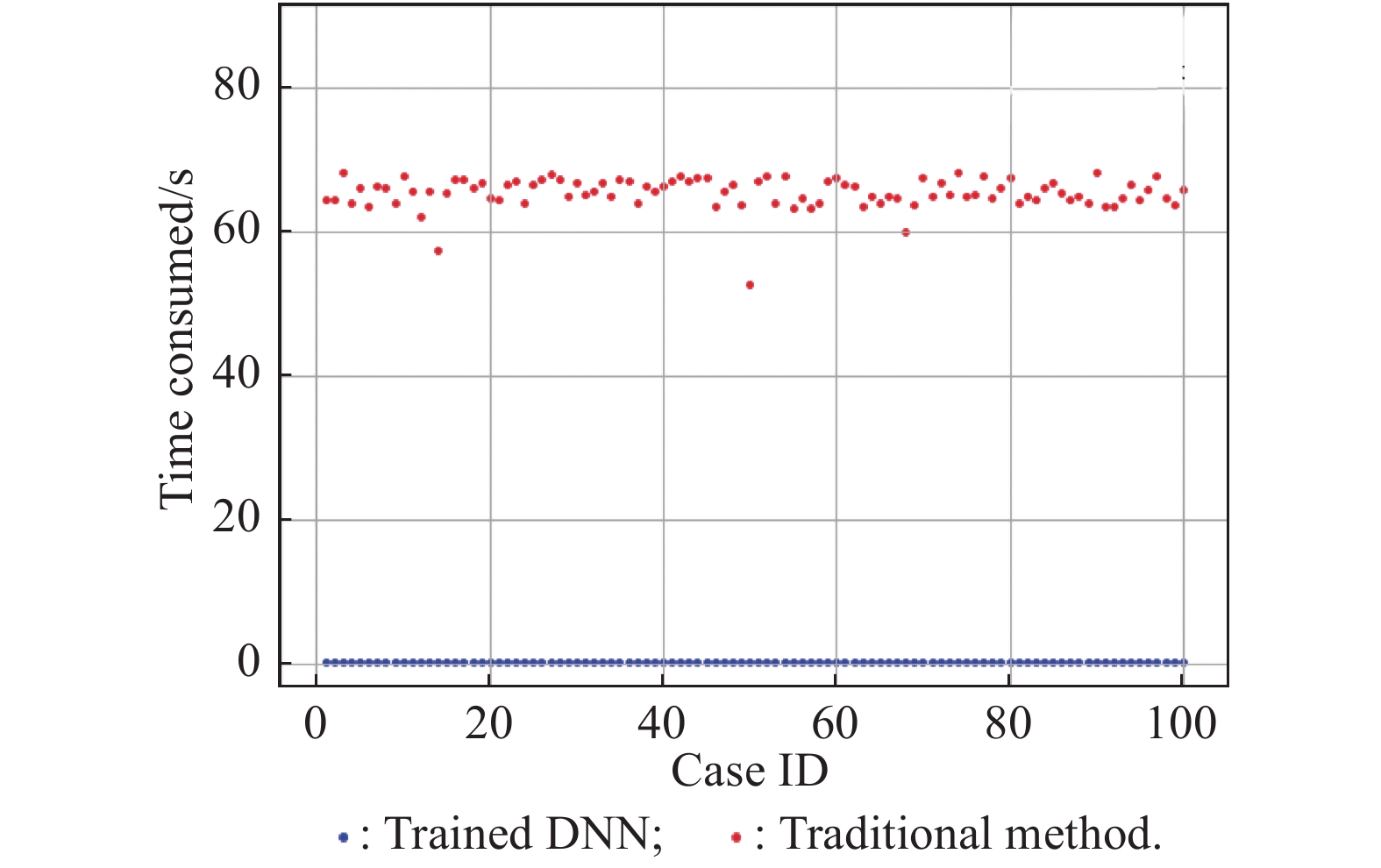
Table 1
Comparison on time consumption"
| Method | | |
| Trained DNN | 0.1088 | 0.0040 |
| Traditional method | 65.3481 | 2.1610 |
Fig 10
Trajectory result"
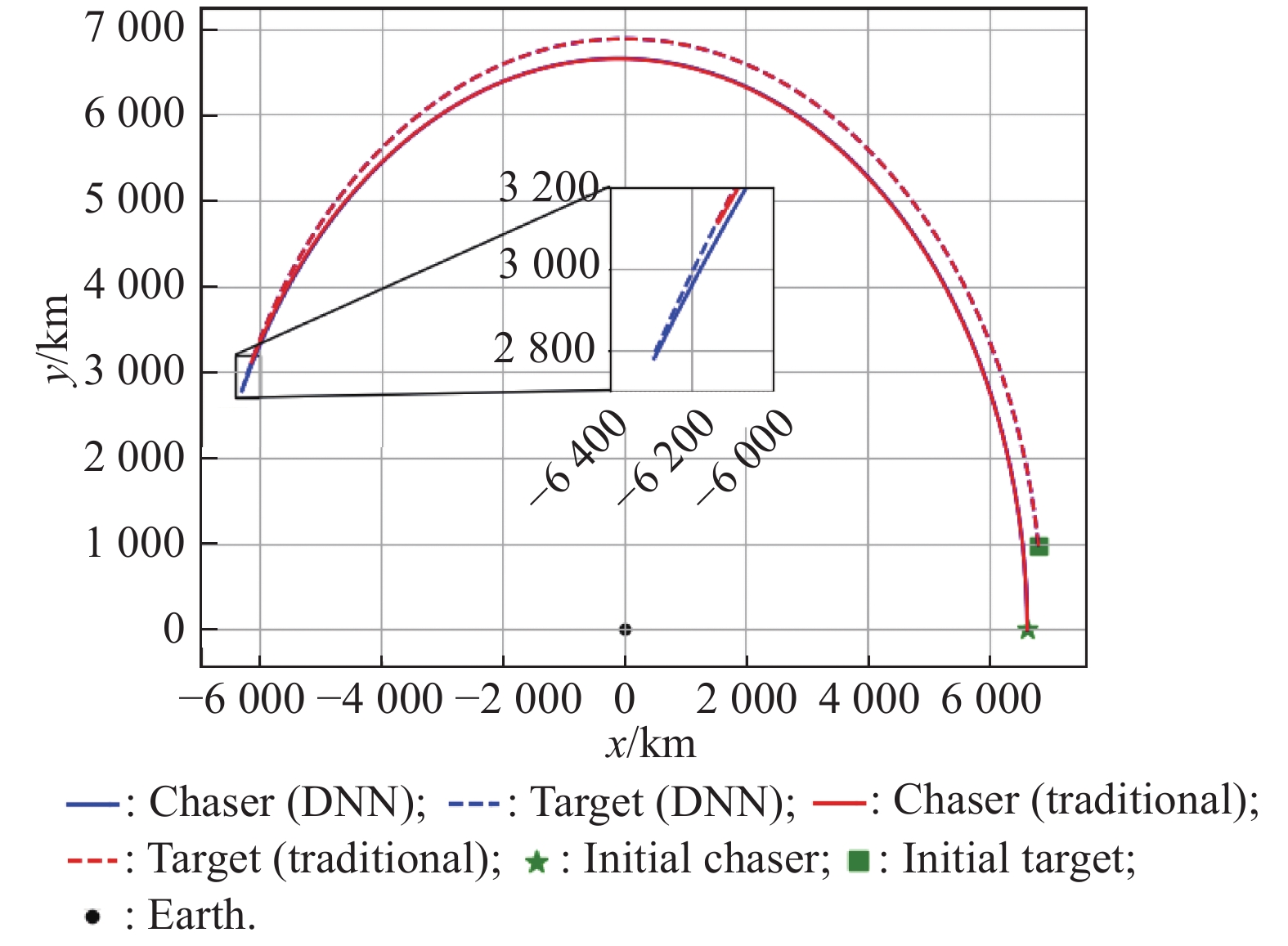
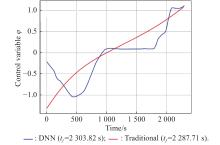
Fig 11
Control variable vs. time"
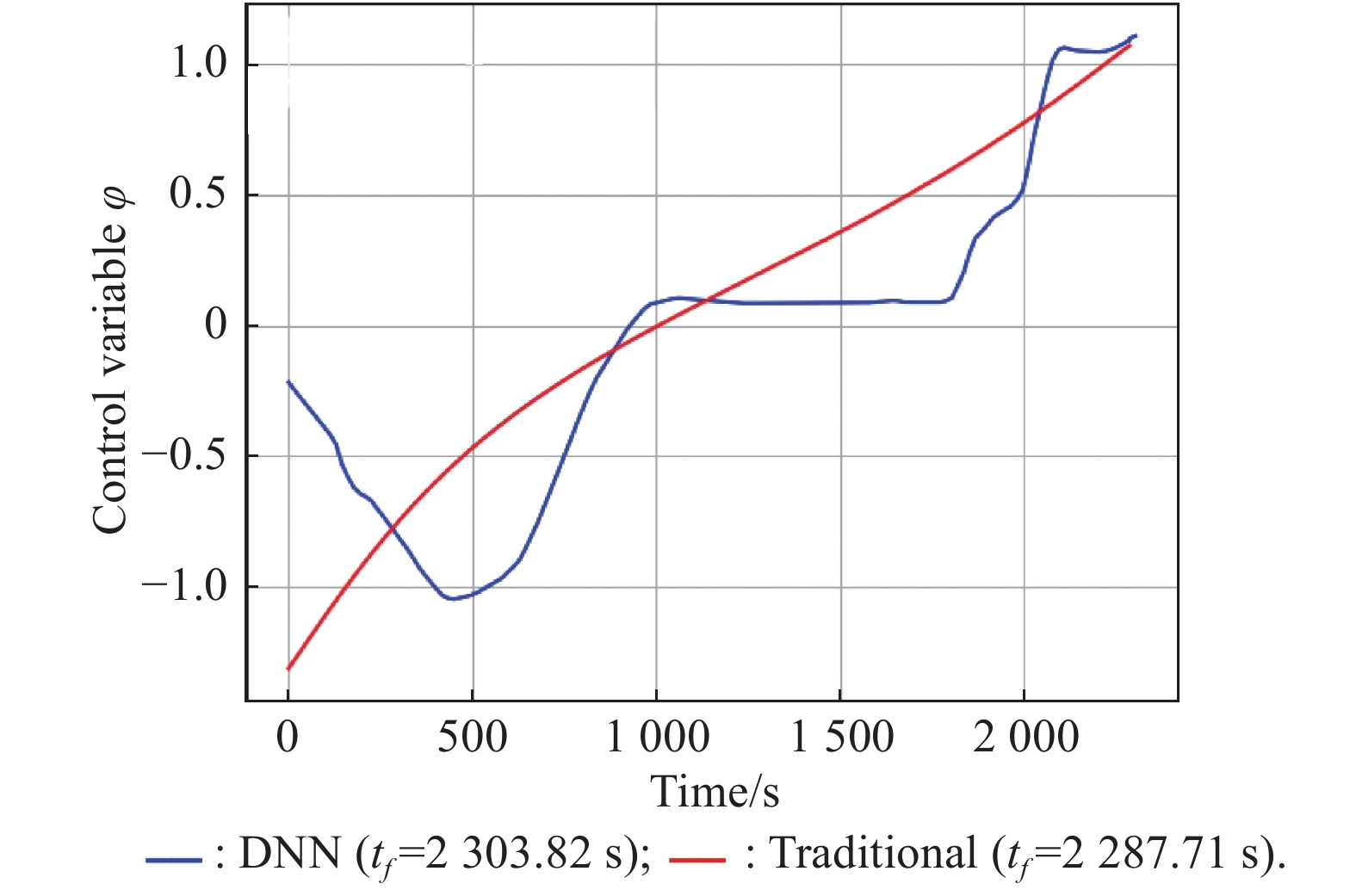
Fig 12
Success rate vs. episode"
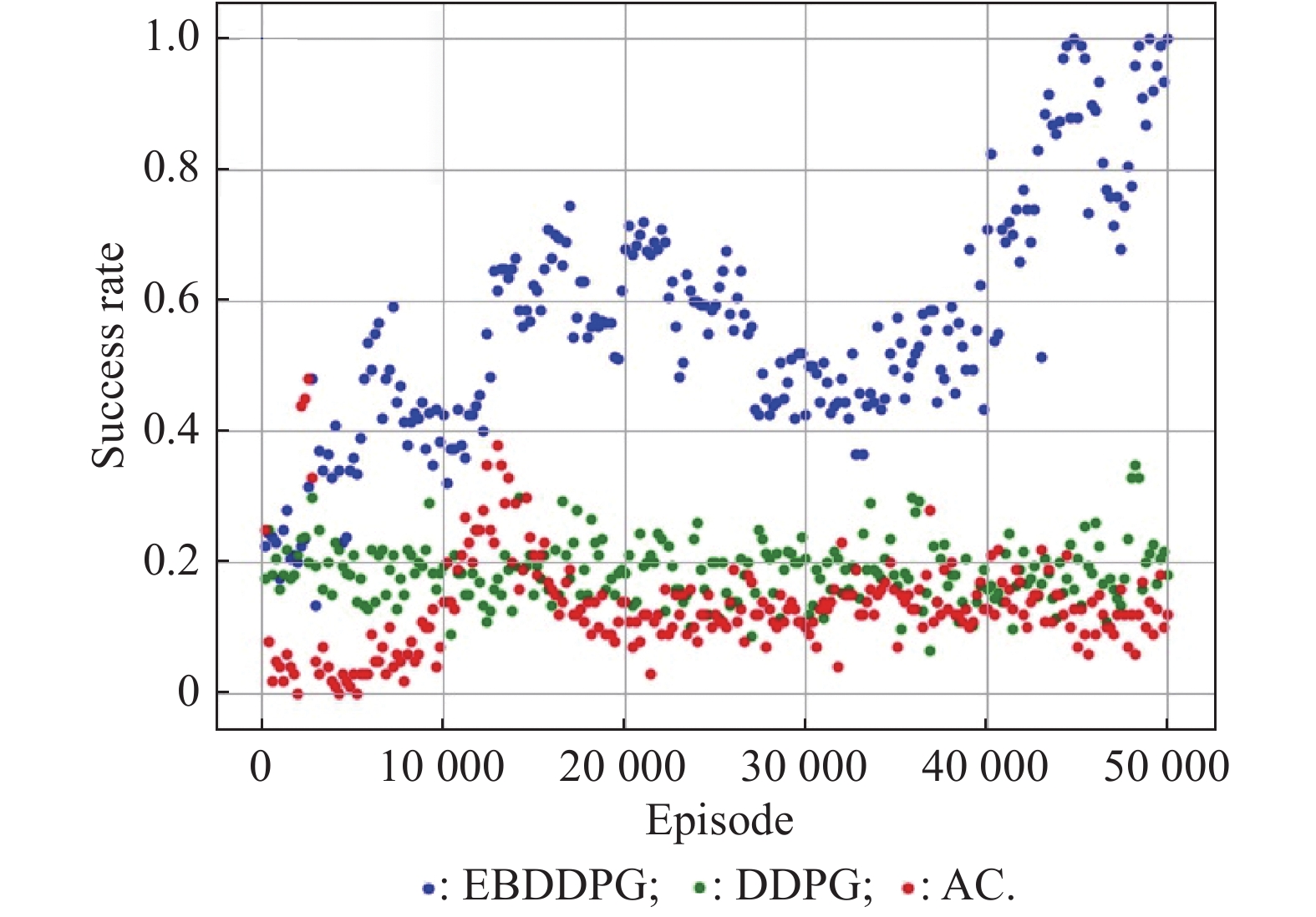
Table 2
Dispersion used in Monte Carlo simulation"
| Deviation | r/km | v/(m/s) | | |
| | ±1 | ±10 | ±0.5 | ±0.5 |
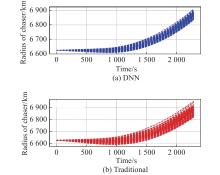
Fig 13
Radius of chaser vs. time t "
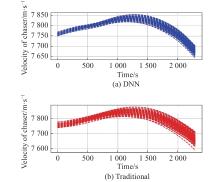
Fig 14
Velocity of chaser vs. time t "
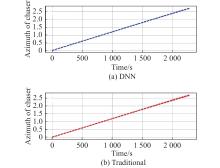
Fig 15
Azimuth of chaser vs. time t "
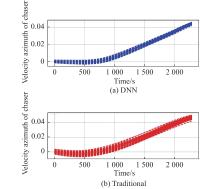
Fig 16
Velocity azimuth of chaser vs. time t "
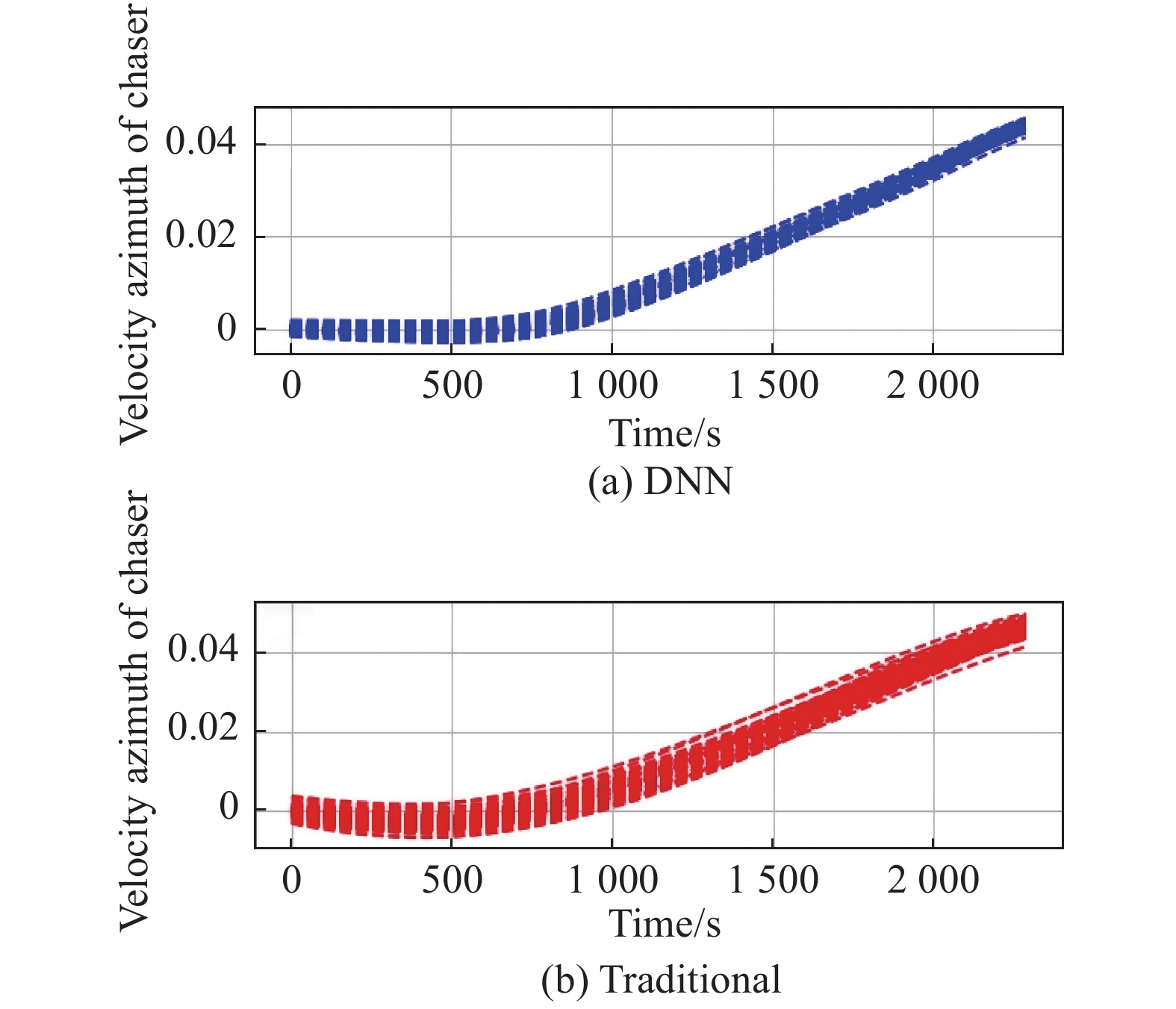
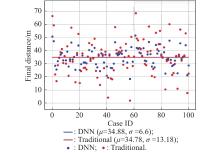
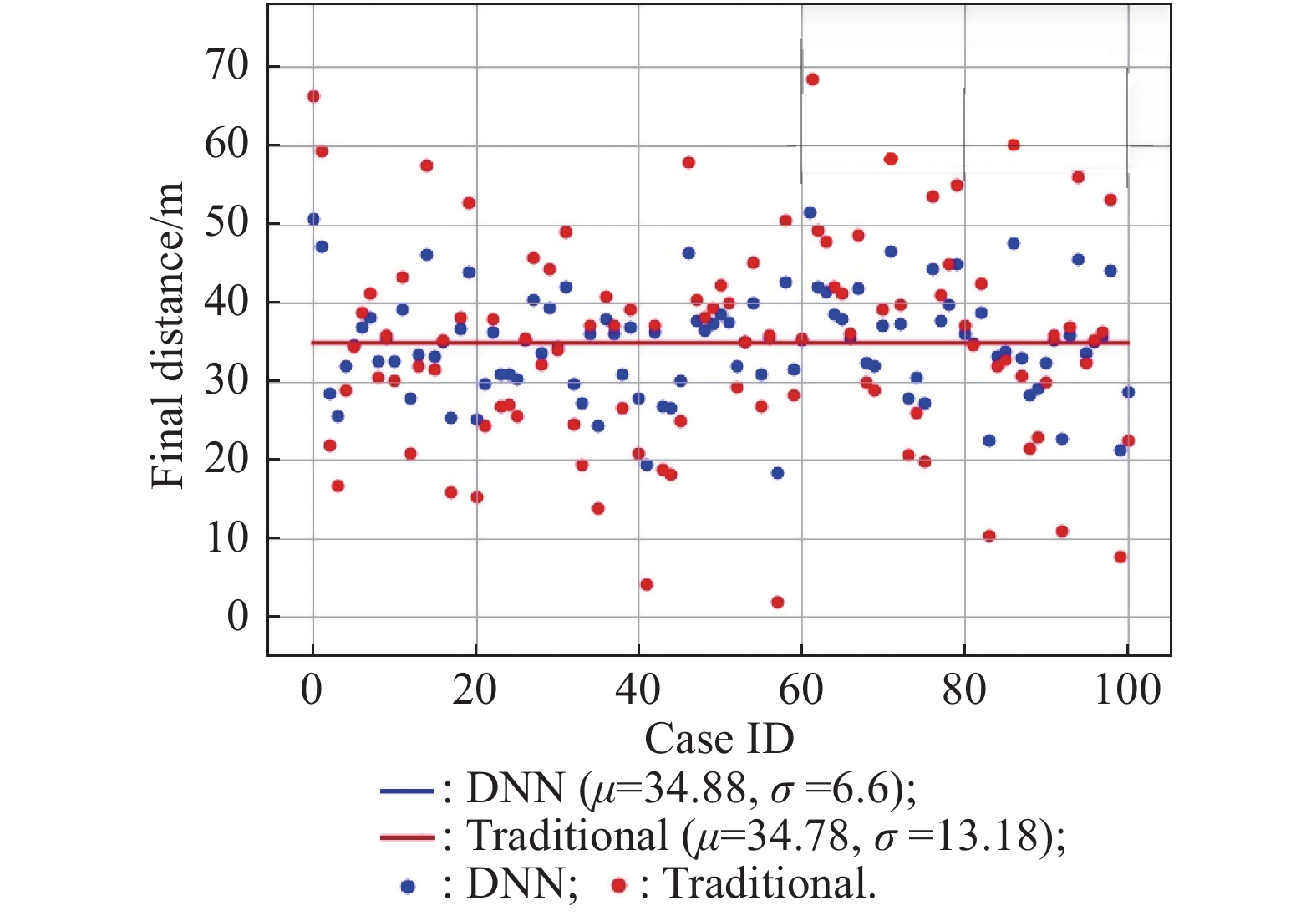
Fig 17
Dispersion of the final distance"
| 1 | GARCIA E, CASBEER D W, PACHTER M Design and analysis of state-feedback optimal strategies for the differential game of active defense. IEEE Trans. on Automatic Control, 2019, 64 (2): 553- 568. |
| 2 |
JIANG J X, ZENG X Y, GUZZETTI D, et al Path planning for asteroid hopping rovers with pre-trained deep reinforcement learning architectures. Acta Astronautica, 2020, 171, 265- 279.
doi: 10.1016/j.actaastro.2020.03.007 |
| 3 |
FENG Y T, WANG C Q, LI A J Optimal trajectory tracking control based on reinforcement learning for the deployment process of space tether system. IFAC-PapersOnLine, 2020, 53 (1): 679- 684.
doi: 10.1016/j.ifacol.2020.06.113 |
| 4 |
WANG X, SHI P, WEN C X, et al Design of parameter-self-tuning controller based on reinforcement learning for tracking noncooperative targets in space. IEEE Trans. on Aerospace and Electronic Systems, 2020, 56 (6): 4192- 4208.
doi: 10.1109/TAES.2020.2988170 |
| 5 | ZAVOLI A, FEDERICI L. Reinforcement learning for low-thrust trajectory design of interplanetary missions. arXiv: 2008.08501, 2020. https://arxiv.org/abs/2008.08501. |
| 6 |
GAUDET B, FURFARO R, LINARES R Reinforcement learning for angle-only intercept guidance of maneuvering targets. Aerospace Science and Technology, 2020, 99, 105746.
doi: 10.1016/j.ast.2020.105746 |
| 7 |
LIU P F, LIU Y M, HUANG T Y, et al Decentralized automotive radar spectrum allocation to avoid mutual interference using reinforcement learning. IEEE Trans. on Aerospace and Electronic Systems, 2021, 57 (1): 190- 205.
doi: 10.1109/TAES.2020.3011869 |
| 8 |
SELVI E, BUEHRER R M, MARTONE A, et al Reinforcement learning for adaptable bandwidth tracking radars. IEEE Trans. on Aerospace and Electronic Systems, 2020, 56 (5): 3904- 3921.
doi: 10.1109/TAES.2020.2987443 |
| 9 |
XIE Z C, SUN T, KWAN T, et al Motion control of a space manipulator using fuzzy sliding mode control with reinforcement learning. Acta Astronautica, 2020, 176, 156- 172.
doi: 10.1016/j.actaastro.2020.06.028 |
| 10 | XU K, WU F G, ZHAO J S. Model-based deep reinforcement learning with heuristic search for satellite attitude control. Industrial Robot, 2019, 46(3): 415−420. |
| 11 | SHARMA S, CUTLER J W. Robust orbit determination and classification: a learning theoretic approach. Interplanetary Network Progress Report, 2015, 42-203(Nov.): 1−20. DOI: 10.1620/tjem.201.127. |
| 12 |
SANCHEZ C, IZZO D Real-time optimal control via deep neural networks: study on landing problems. Journal of Guidance, Control, and Dynamics, 2018, 41 (5): 1122- 1135.
doi: 10.2514/1.G002357 |
| 13 |
SHEN H X, CASALINO L Revisit of the three-dimensional orbital pursuit-evasion game. Journal of Guidance, Control, and Dynamics, 2018, 41 (8): 1823- 1831.
doi: 10.2514/1.G003127 |
| 14 |
GONG H R, GONG S P, LI J F Pursuit-evasion game for satellites based on continuous thrust reachable domain. IEEE Trans. on Aerospace and Electronic Systems, 2020, 56 (6): 4626- 4637.
doi: 10.1109/TAES.2020.2998197 |
| 15 |
LI Z Y, ZHU H, YANG Z, et al A dimension-reduction solution of free-time differential games for spacecraft pursuit-evasion. Acta Astronautica, 2019, 163, 201- 210.
doi: 10.1016/j.actaastro.2019.01.011 |
| 16 |
YE D, SHI M M, SUN Z W Satellite proximate interception vector guidance based on differential games. Chinese Journal of Aeronautics, 2018, 31 (6): 1352- 1361.
doi: 10.1016/j.cja.2018.03.012 |
| 17 |
ZENG X, YANG L P, ZHU Y W, et al Comparison of two optimal guidance methods for the long-distance orbital pursuit-evasion game. IEEE Trans. on Aerospace and Electronic Systems, 2021, 57 (1): 521- 539.
doi: 10.1109/TAES.2020.3024423 |
| 18 |
YE D, SHI M M, SUN Z W Satellite proximate pursuit-evasion game with different thrust configurations. Aerospace Science and Technology, 2020, 99, 105715.
doi: 10.1016/j.ast.2020.105715 |
| 19 |
LI Z Y, ZHU H, LUO Y Z An escape strategy in orbital pursuit-evasion games with incomplete information. Science China Technological Sciences, 2021, 64, 559- 570.
doi: 10.1007/s11431-020-1662-0 |
| 20 |
PRINCE E R, HESS J A, COBB R G, et al Elliptical orbit proximity operations differential games. Journal of Guidance, Control, and Dynamics, 2019, 42 (7): 1458- 1472.
doi: 10.2514/1.G004031 |
| 21 |
SHE H, HETTEL W, LUBIN P Directed energy interception of satellites. Advances in Space Research, 2019, 63 (12): 3795- 3815.
doi: 10.1016/j.asr.2019.02.013 |
| 22 | MENG E T, BU X Y, WANG C H A novel anti-interception waveform in LEO satellite system. Proc. of the IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference, 2020, 1183- 1187. |
| 23 | GUO Y J, KANG G H, JIN C D, et al A cooperative interception strategy of small satellite swarm based on bifurcation potential field. Proc. of the IEEE CSAA Guidance, Navigation and Control Conference, 2018, 1- 6. |
| 24 |
HAN H W, QIAO D, CHEN H B Optimization of aeroassisted rendezvous and interception trajectories between non-coplanar elliptical orbits. Acta Astronautica, 2019, 163 (Part B): 190- 200.
doi: 10.1016/j.actaastro.2018.11.028 |
| 25 | LI Y F, ZHANG Y S A method of determining multiple-targets interception based on traversing points. Applied Mechanics & Materials, 2013, 437, 1081- 1084. |
| 26 |
HAFER W, REED H L, TURNER J, et al Sensitivity methods applied to orbital pursuit evasion. Journal of Guidance, Control, and Dynamics, 2015, 38 (6): 1- 9.
doi: 10.2514/1.G000832 |
| 27 |
CARR R W, COBB R G, PACHTER M, et al Solution of a pursuit-evasion game using a near-optimal strategy. Journal of Guidance, Control, and Dynamics, 2018, 41 (4): 841- 850.
doi: 10.2514/1.G002911 |
| 28 | SUTTON R, BARTO A. Reinforcement learning: an introduction. Massachusetts: MIT Press, 1998. |
| 29 |
CHU W M, WU S N, HE X, et al Deep learning-based inertia tensor identification of the combined spacecraft. Proc. of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2020, 234 (7): 1356- 1366.
doi: 10.1177/0954410020904555 |
| 30 |
FURFARO R, SCORSOGLIO A, LINARES R, et al Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach. Acta Astronautica, 2020, 171, 156- 171.
doi: 10.1016/j.actaastro.2020.02.051 |
| 31 |
GAUDET B, LINARES R, FURFARO R Deep reinforcement learning for six degree-of-freedom planetary landing. Advances in Space Research, 2020, 65 (7): 1723- 1741.
doi: 10.1016/j.asr.2019.12.030 |
| 32 |
JIANG X Q, LI S, FURFARO R Integrated guidance for Mars entry and powered descent using reinforcement learning and pseudospectral method. Acta Astronautica, 2019, 163, 114- 129.
doi: 10.1016/j.actaastro.2018.12.033 |
| 33 |
DAS-STUART A, HOWELL K, FOLTA D Rapid trajectory design in complex environments enabled by reinforcement learning and graph search strategies. Acta Astronautica, 2020, 171, 172- 195.
doi: 10.1016/j.actaastro.2019.04.037 |
| 34 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning. arXiv: 1509.02971, 2019. https://arxiv.org/abs/1509.02971v2. |
| 35 | MNIH V, BADIA A P, MIRZA M, et al Asynchronous methods for deep reinforcement learning. Proc. of the 33rd International Conference on Machine Learning, 2016, 48, 1928- 1937. |
| 36 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization. arXiv: 1502.05477v5. https://arxiv.org/pdf/1502.05477.pdf. |
| 37 |
RUNARSSON T P, YAO X Search biases in constrained evolutionary optimization. IEEE Trans. on Systems, Man and Cybernetics, Part C (Applications and Reviews), 2005, 35 (2): 233- 243.
doi: 10.1109/TSMCC.2004.841906 |
| 38 |
ANDERSON D Algorithms for minimization without derivatives. IEEE Trans. on Automatic Control, 1974, 19 (5): 632- 633.
doi: 10.1109/TAC.1974.1100629 |
| 39 | AWHEDA M D, SCHWARTZ H M A residual gradient fuzzy reinforcement learning algorithm for differential games. International Journal of Fuzzy Systems, 2017, 19 (4): 1- 19. |
| 40 | KINGMA D, BA J. Adam: a method for stochastic optimization. Computer Science, 2014. https://arxiv.org/abs/1412.6980v8. |
| [1] | Xiangyang LIN, Qinghua XING, Fuxian LIU. Choice of discount rate in reinforcement learning with long-delay rewards [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 381-392. |
| [2] | Bing LIN, Yuchen LIN, Rohit BHATNAGAR. Optimal policy for controlling two-server queueing systems with jockeying [J]. Journal of Systems Engineering and Electronics, 2022, 33(1): 144-155. |
| [3] | Wanping SONG, Zengqiang CHEN, Mingwei SUN, Qinglin SUN. Reinforcement learning based parameter optimization of active disturbance rejection control for autonomous underwater vehicle [J]. Journal of Systems Engineering and Electronics, 2022, 33(1): 170-179. |
| [4] | Xiang Gao, Yangwang Fang, and Youli Wu. Fuzzy Q learning algorithm for dual-aircraft path planning to cooperatively detect targets by passive radars [J]. Journal of Systems Engineering and Electronics, 2013, 24(5): 800-810. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||