
Journal of Systems Engineering and Electronics ›› 2025, Vol. 36 ›› Issue (1): 233-255.doi: 10.23919/JSEE.2025.000009
• CONTROL THEORY AND APPLICATION • Previous Articles
Yu BAI1( ), Di ZHOU1,*(), Bolun ZHANG2(), Zhen HE1(), Ping HE3()
), Di ZHOU1,*(), Bolun ZHANG2(), Zhen HE1(), Ping HE3()
Received:2023-11-22
Online:2025-02-18
Published:2025-03-18
Contact:
Di ZHOU
E-mail:1260787968@qq.com;zhoud@hit.edu.com;bolun1104@163.com;hezhen@hit.edu.cn;pinghecn@qq.com
About author:Supported by:Yu BAI, Di ZHOU, Bolun ZHANG, Zhen HE, Ping HE. Two-to-one differential game via improved MOGWO[J]. Journal of Systems Engineering and Electronics, 2025, 36(1): 233-255.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
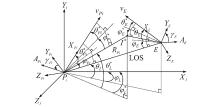
Fig 1
Model of movement in 3D space"
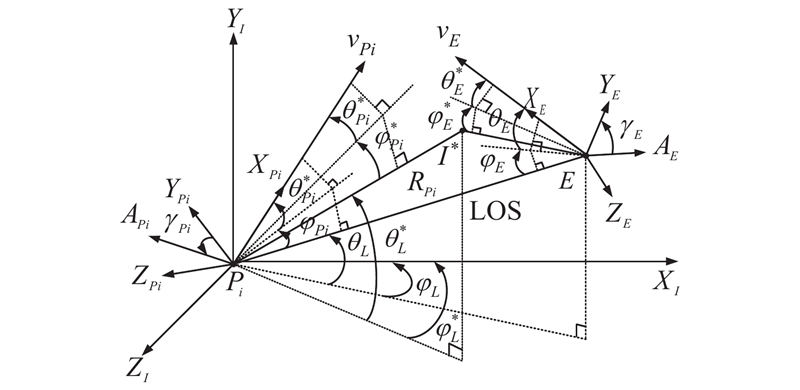
Fig 2
Illustrative diagram of the algorithm"
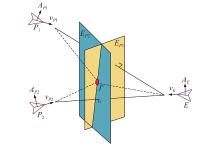
Fig 3
Schematic diagram of the optimal game point"
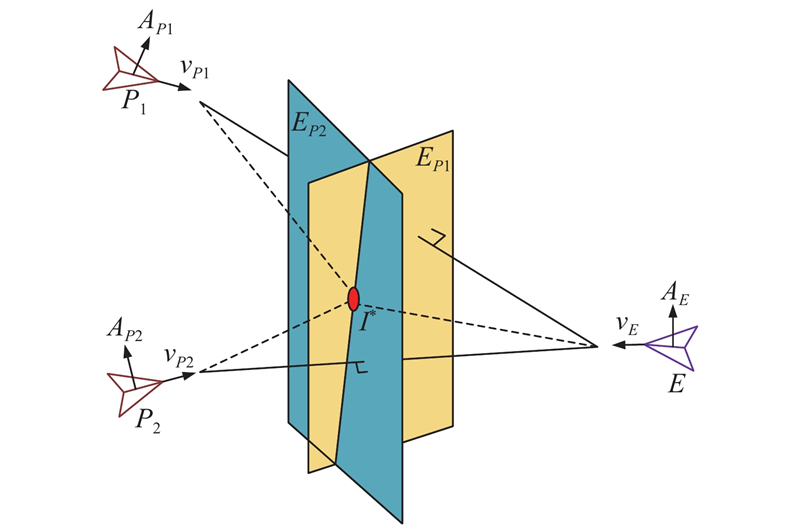
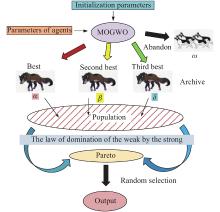
Fig 4
Schematic representation of MOGWO"
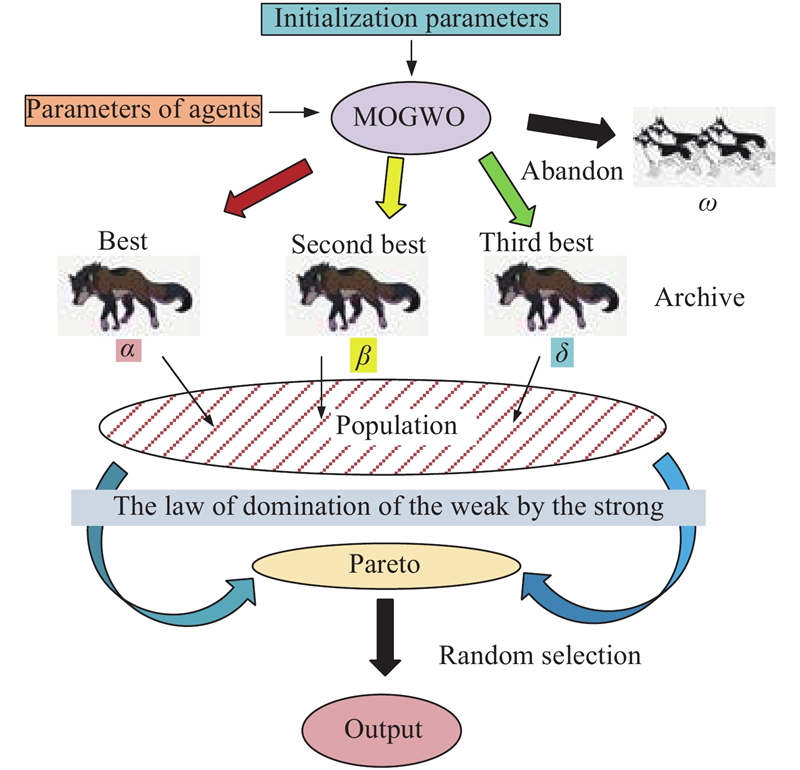
Table 1
Differences between the two algorithms"
| Item | IMOGWO | MOGWO |
| Iteration equation | Equation (35) | |
| Step | Equation (36) | |
| Non-dominated solution | Law of the jungle | Find the non-dominated solution |
| Add new solution | Maximin fitness function | Grid mechanism |
| If achieve full | No limit | Update the grids |
| Research objective | Cost function 1−4 | Function 1−10 |
| Number of objectives | 4 | 2 or 3 |
| Number of iteration | < | < |
| Step size | [0,10] | [0,1] |
| Iteration population | 50 | 100 |
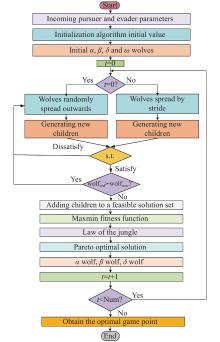
Fig 5
Flowchart of MOGWO"
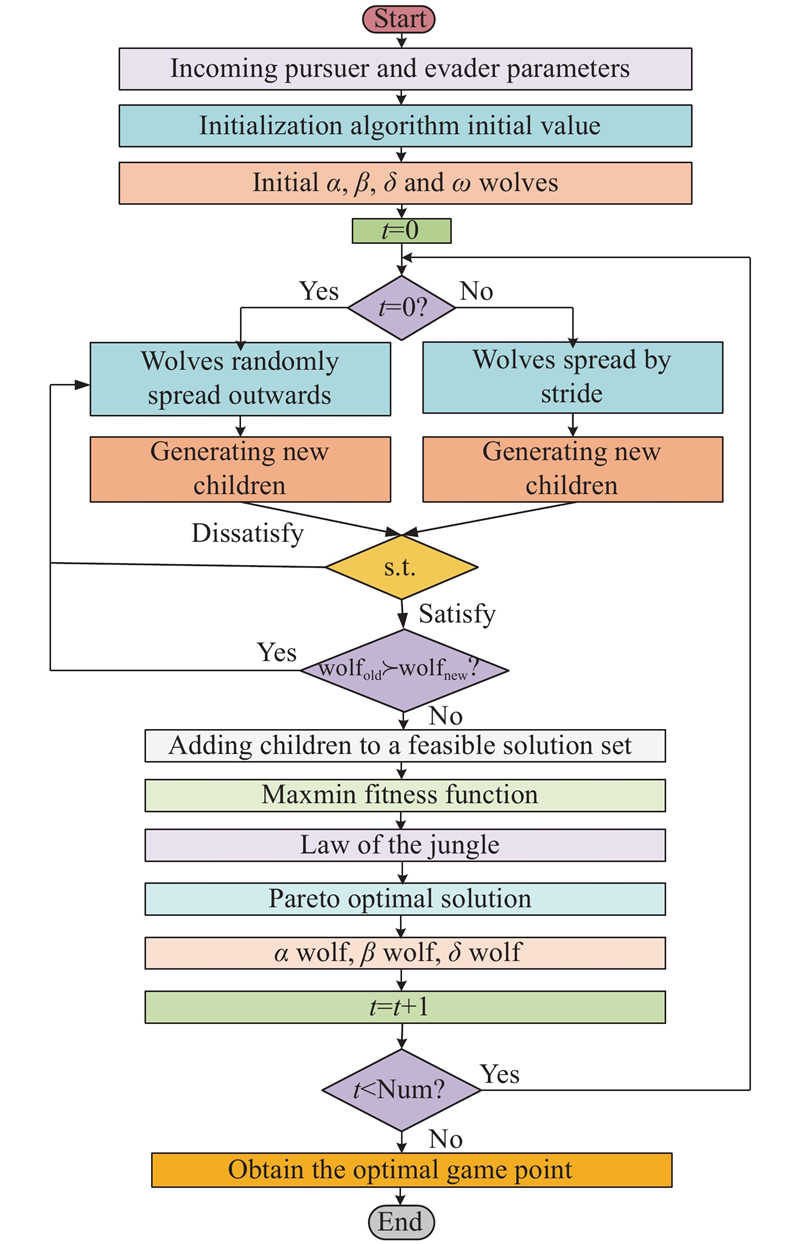
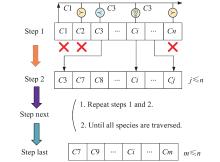
Fig 6
Diagram of the law of the jungle"
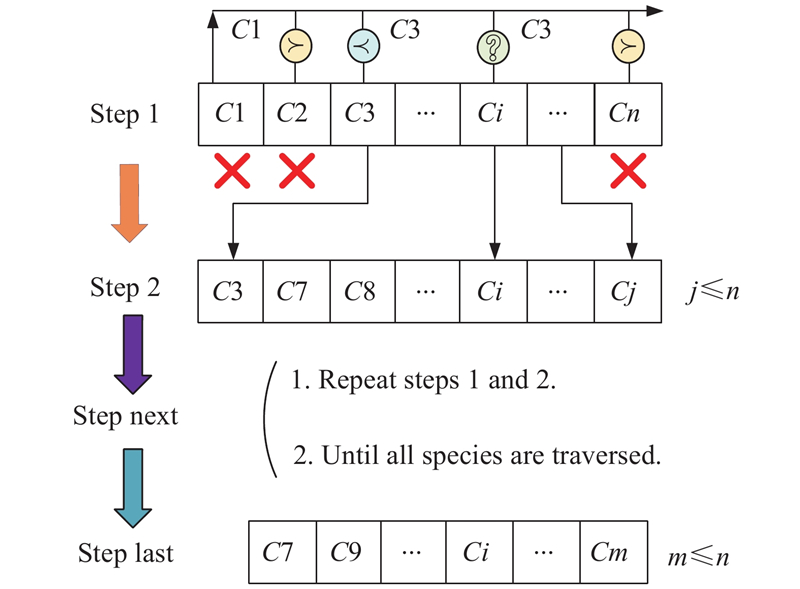
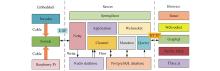
Fig 7
Design of technology stack"
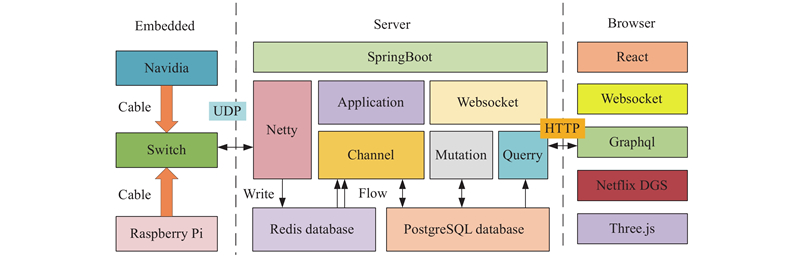
Table 2
Hardware parameters"
| Item | JetNano | Raspberry Pi |
| CPU | ARM CORTEX-A57 | ARM CORTEX-A72 |
| Storage | 16GB EMMC 5.1 | 16GB EMMC 5.1 |
| Memory/GB | 4 | 4 |
| Network | Gigabit Ethernet | Gigabit Ethernet |
Fig 8
Data transmission"
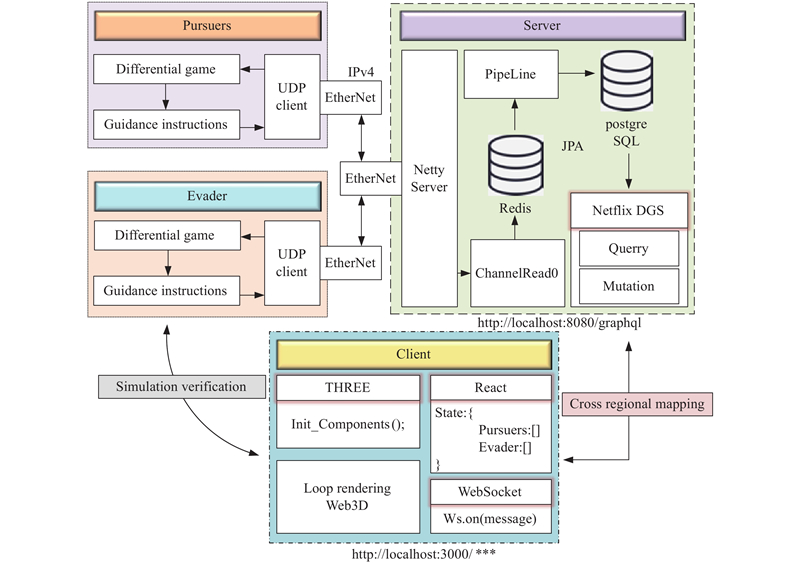

Fig 9
Hardware connection physical diagram"

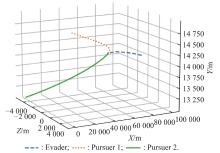
Fig 10
Optimal trajectory example 1"
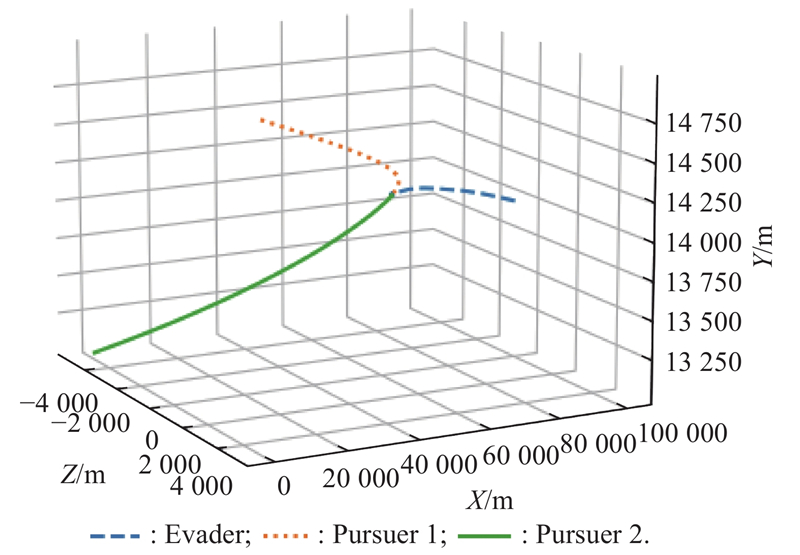
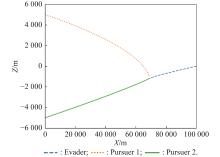
Fig 11
Two-dimensional plan view of X-Z (example 1)"

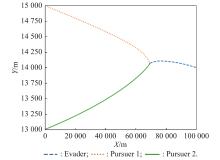
Fig 12
Two-dimensional plan view of X-Y (example 1)"
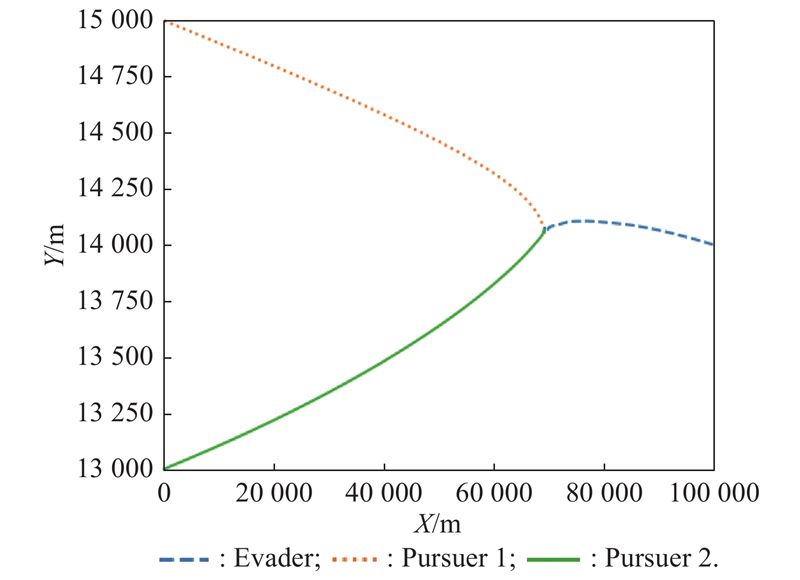
Fig 13
Distance between evader and pursuer (example 1)"
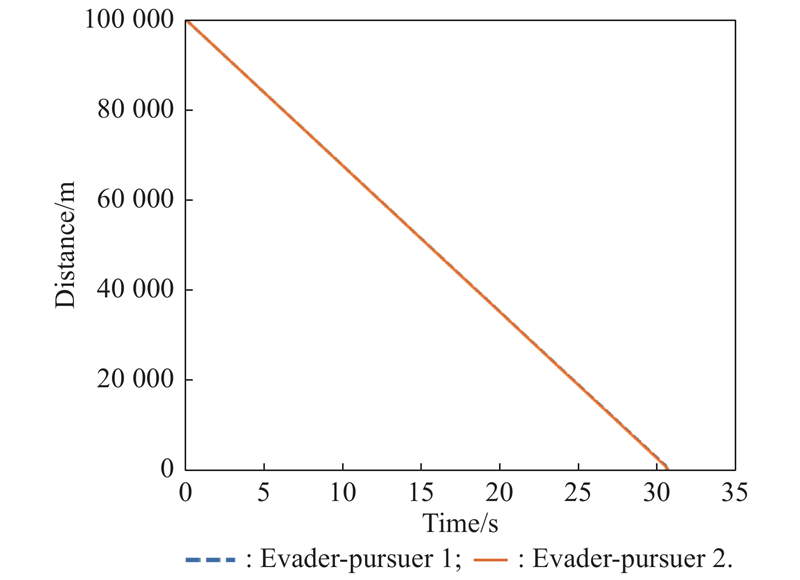
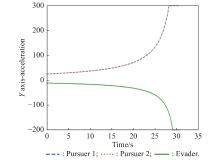
Fig 14
Y-axis acceleration (example 1)"
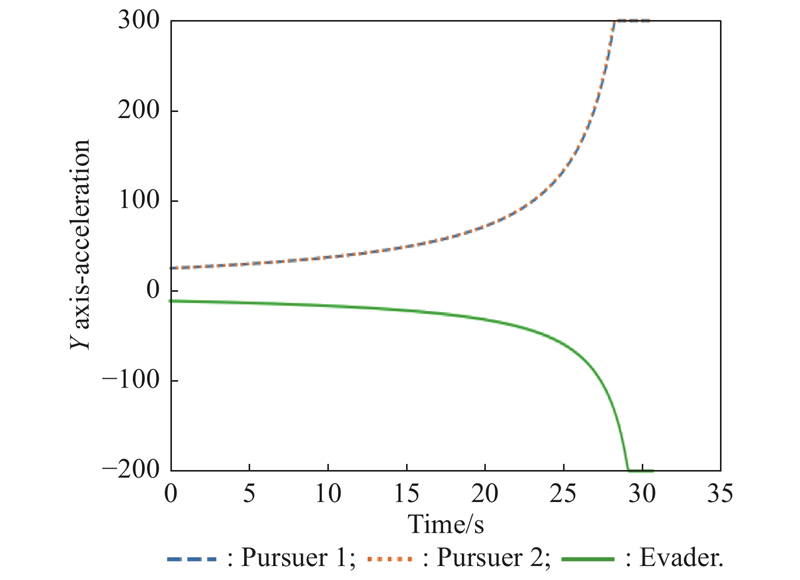

Fig 15
Z-axis acceleration (example 1)"
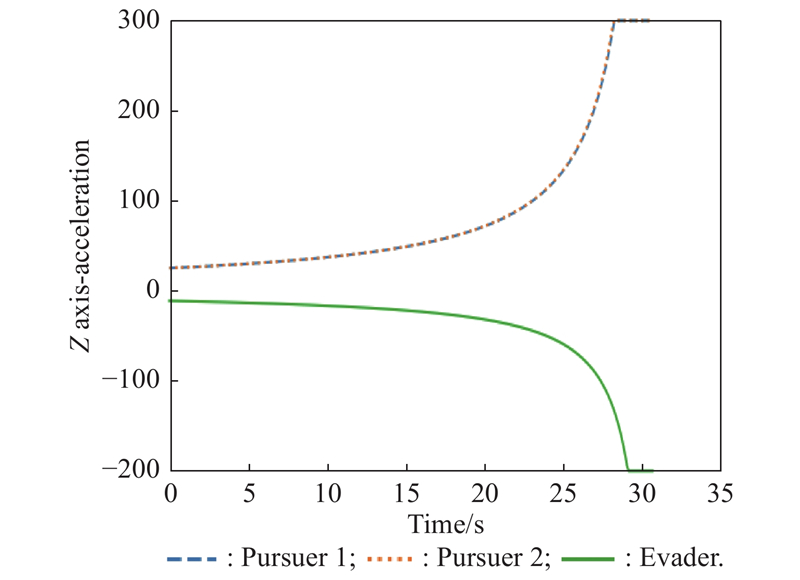
Table 3
Simulation environment"
| Project | Data |
| CPU | E5-2696V4 |
| Internal storage | 128g |
| Disk size | 1T |
| System | Win10 |
Fig 16
Optimal trajectory example 2"
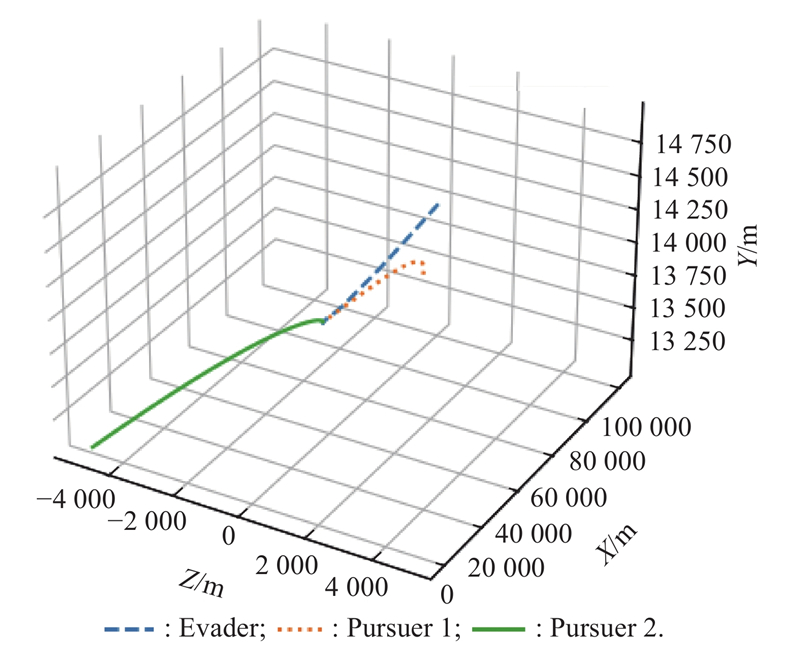
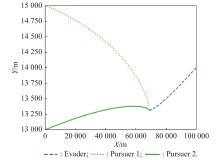
Fig 17
Plane projection of X-Y (example 2)"
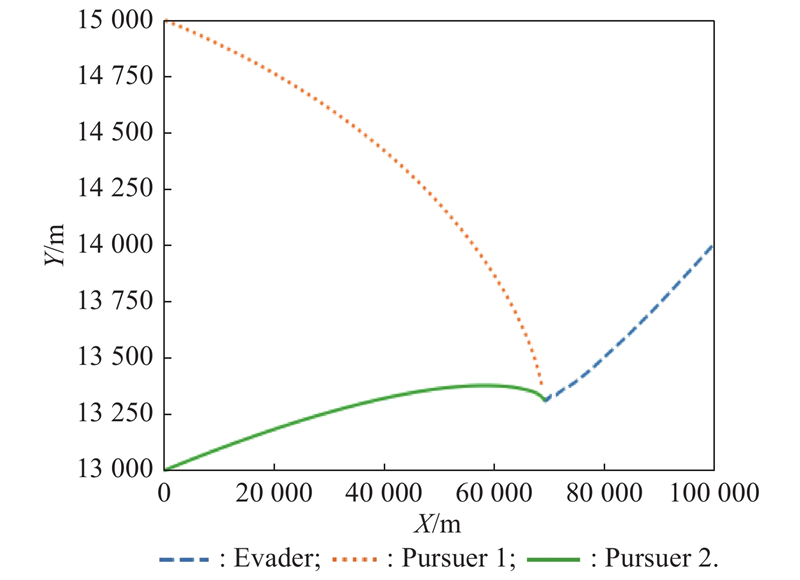
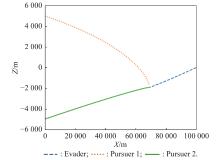
Fig 18
Plane projection of X-Z (example 2)"
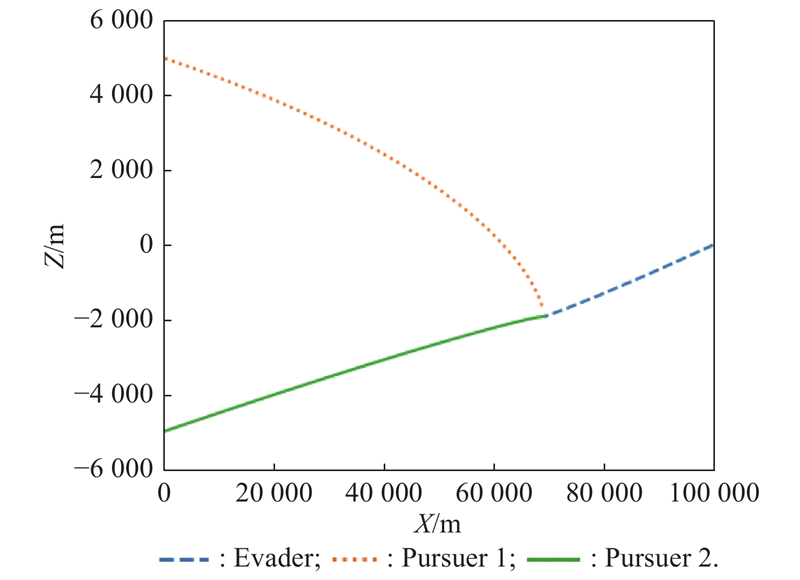
Fig 19
Distance between evader and pursuer (example 2)"
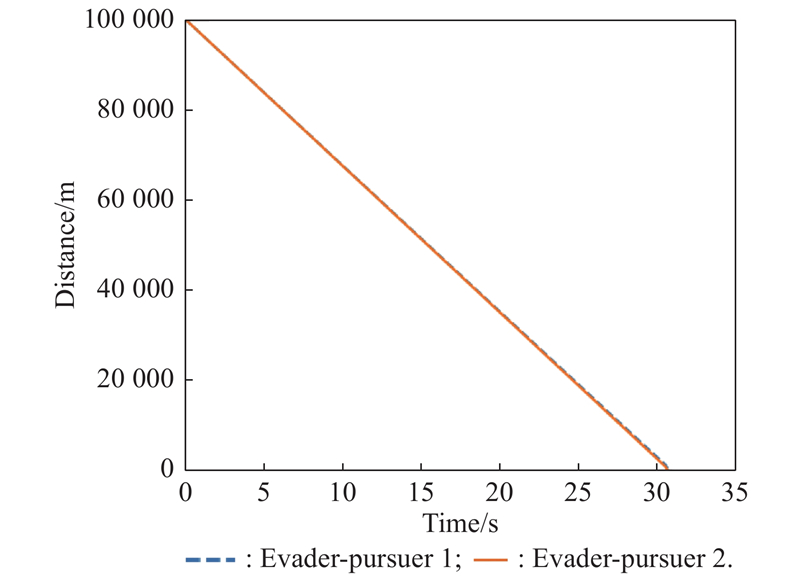
Fig 20
Y-axis acceleration (example 2)"
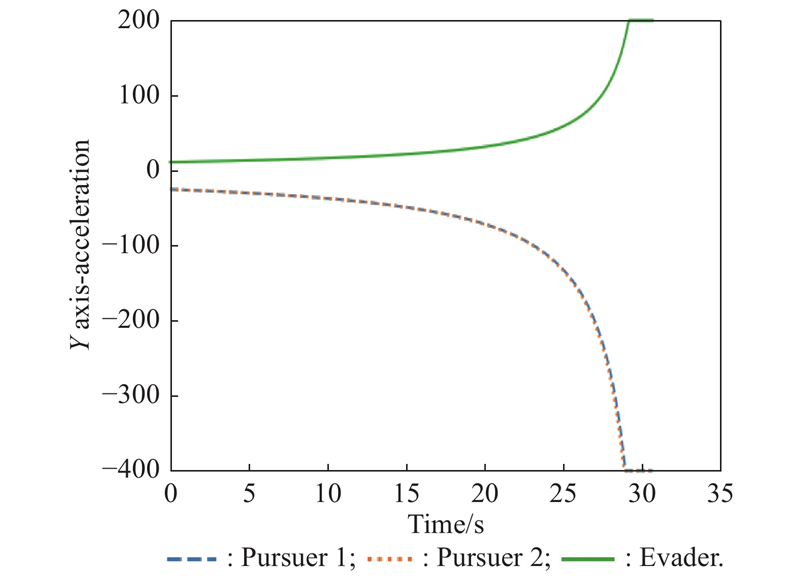
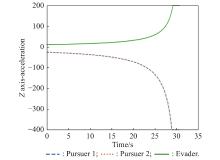
Fig 21
Z-axis acceleration (example 2)"
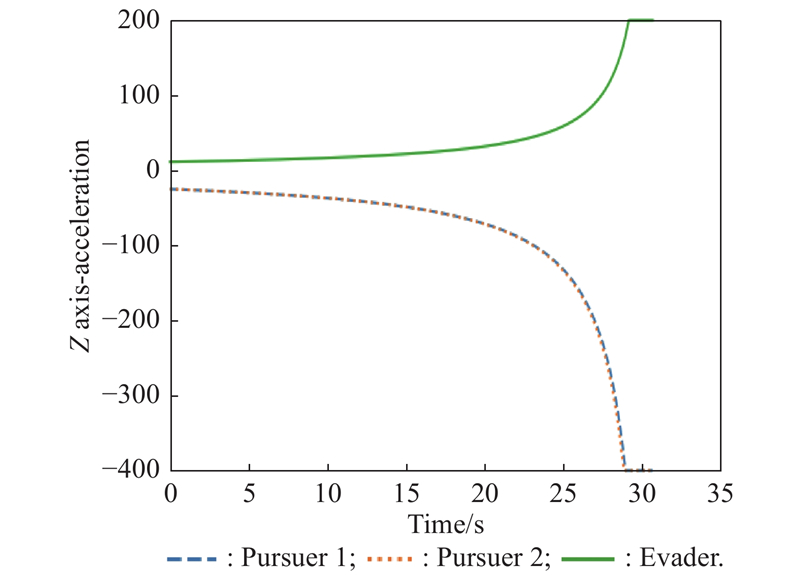
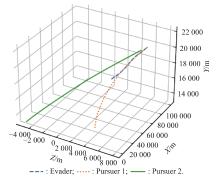
Fig 22
Optimal trajectory example 3"
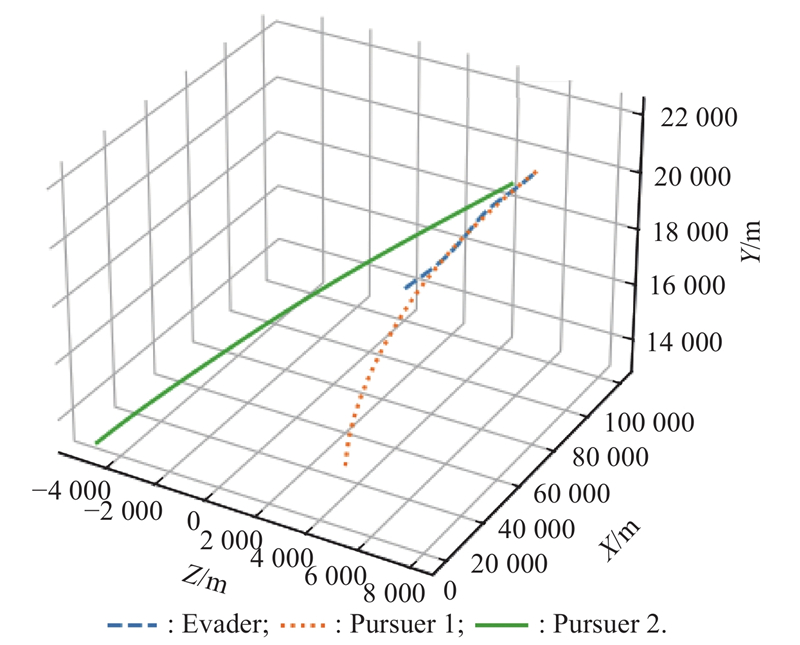
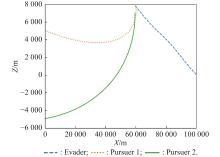
Fig 23
Projection in the X-Z direction (example 3)"
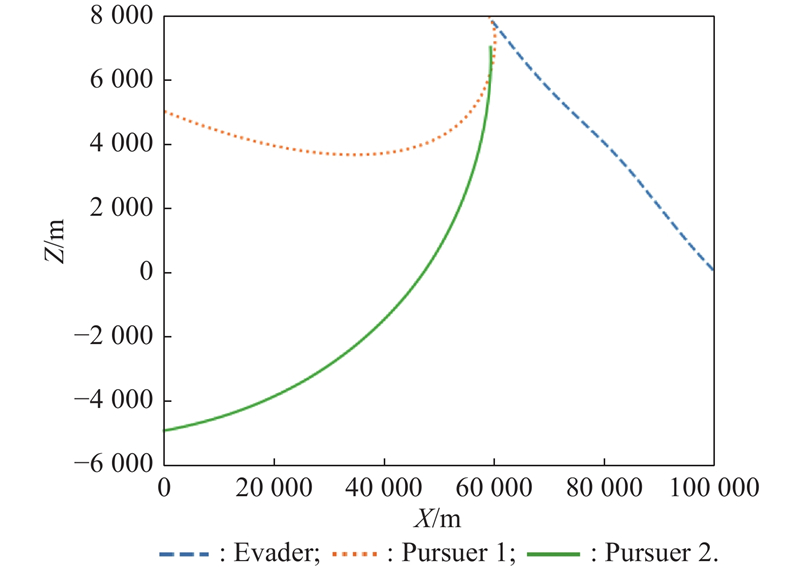
Fig 24
Projection in the X-Y direction (example 3)"
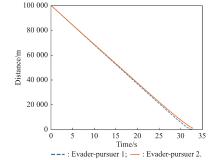
Fig 25
Distance between evader and pursuer (example 3)"
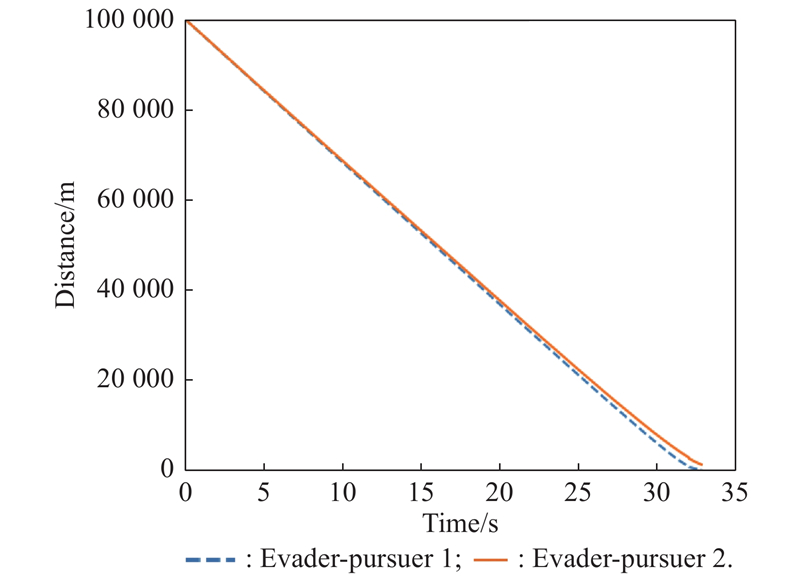
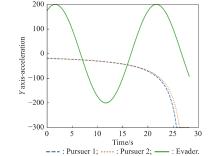
Fig 26
Y-axis acceleration (example 3)"
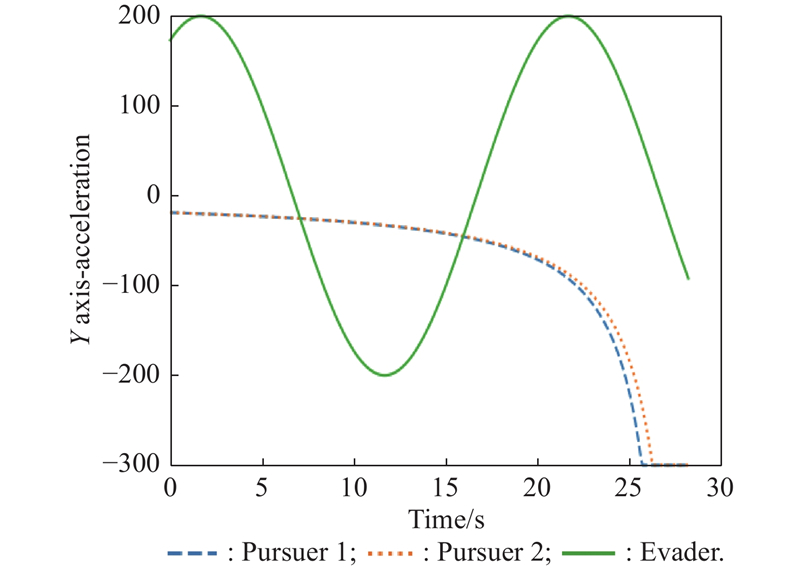

Fig 27
Z-axis acceleration (example 3)"
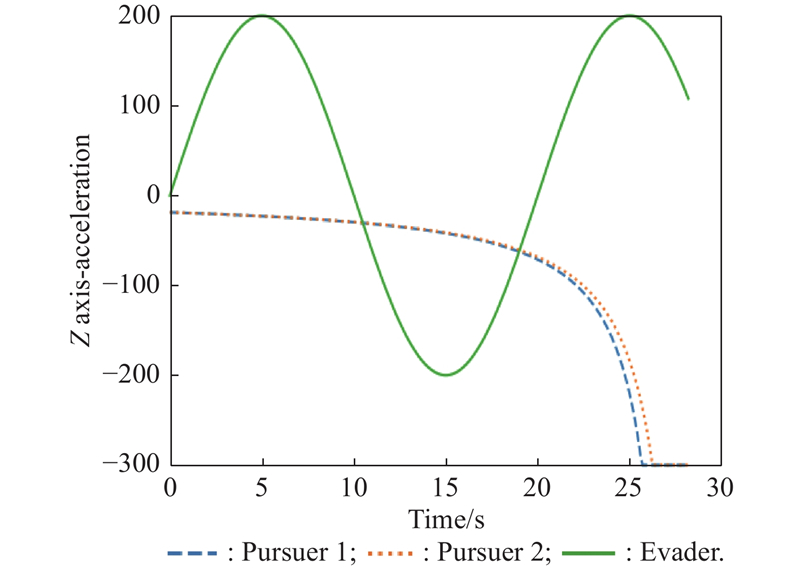
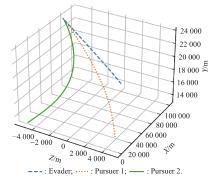
Fig 28
Optimal trajectory example 4"
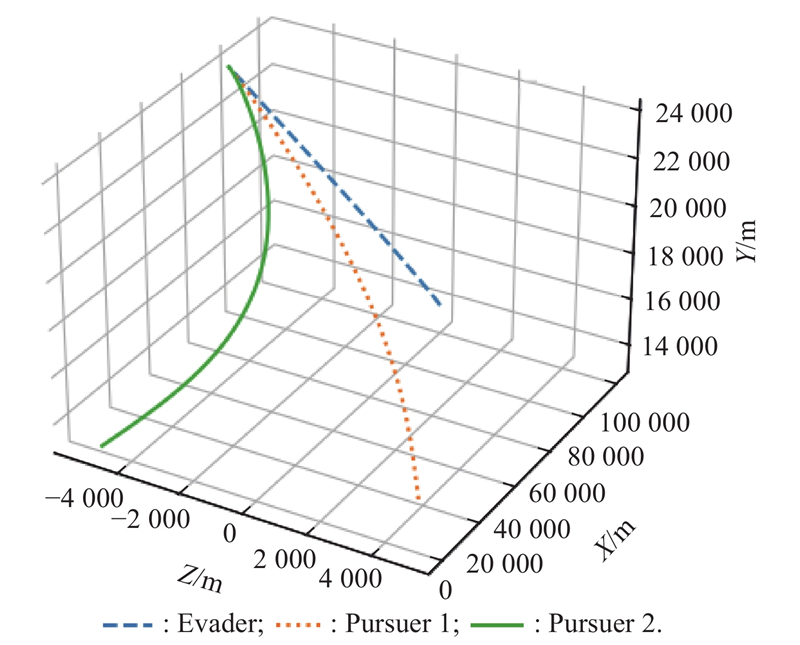
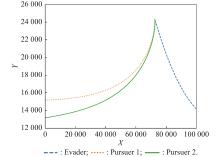
Fig 29
Plane projection of X-Y (example 4)"
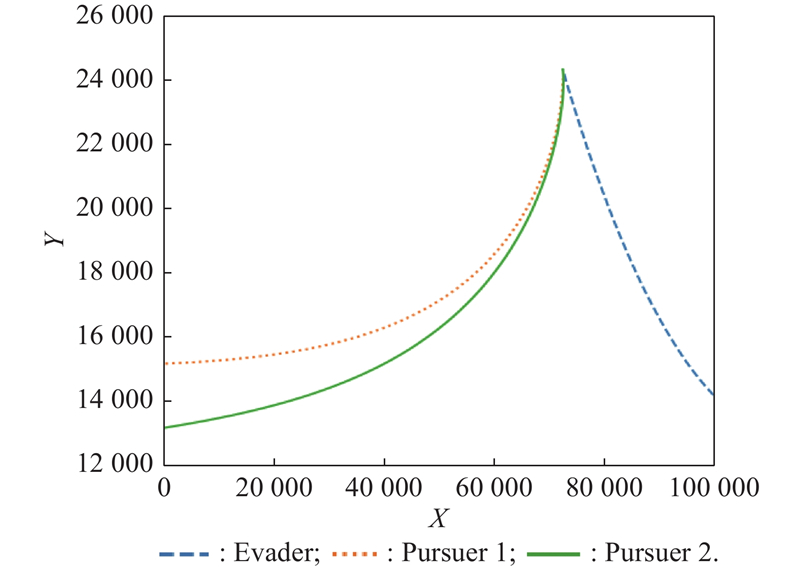
Fig 30
Planar projection of Z-X (example 4)"
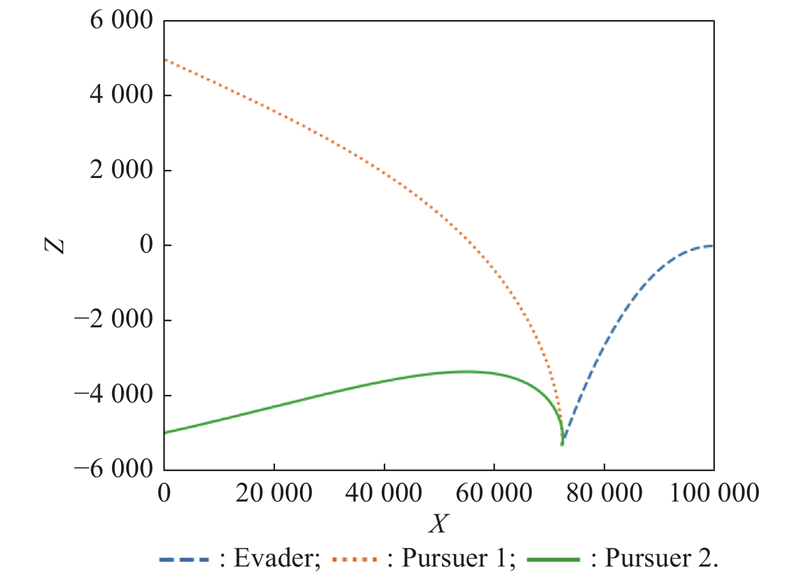
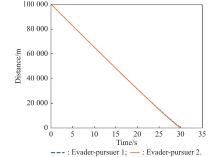
Fig 31
Distance between evader and pursuer (example 4)"
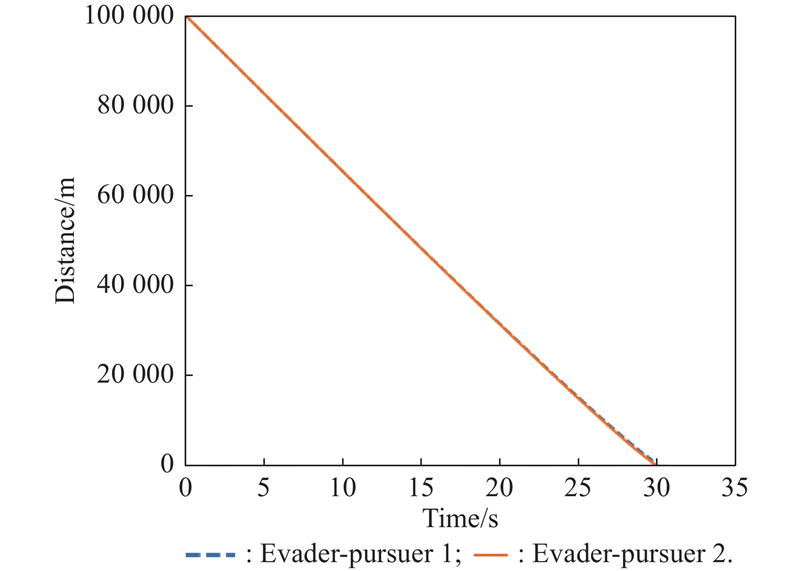
Fig 32
Y-axis acceleration (example 4)"
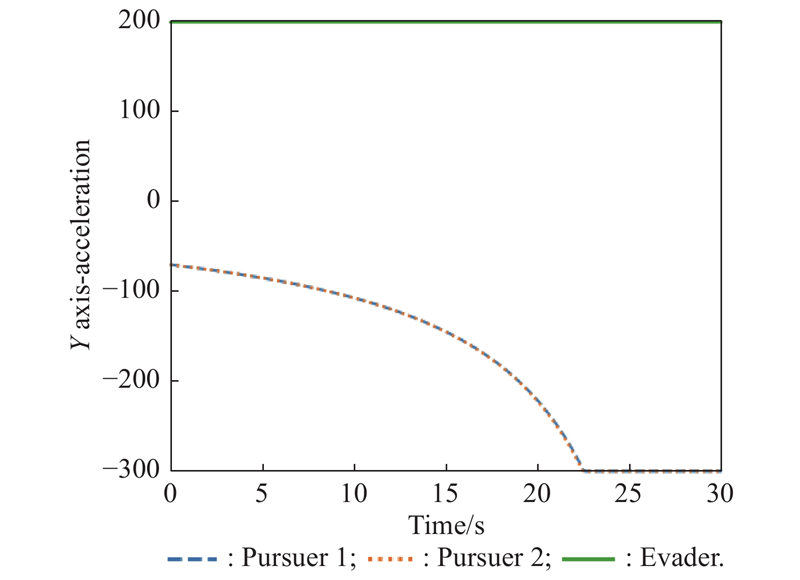
Fig 33
Z-axis acceleration (example 4)"
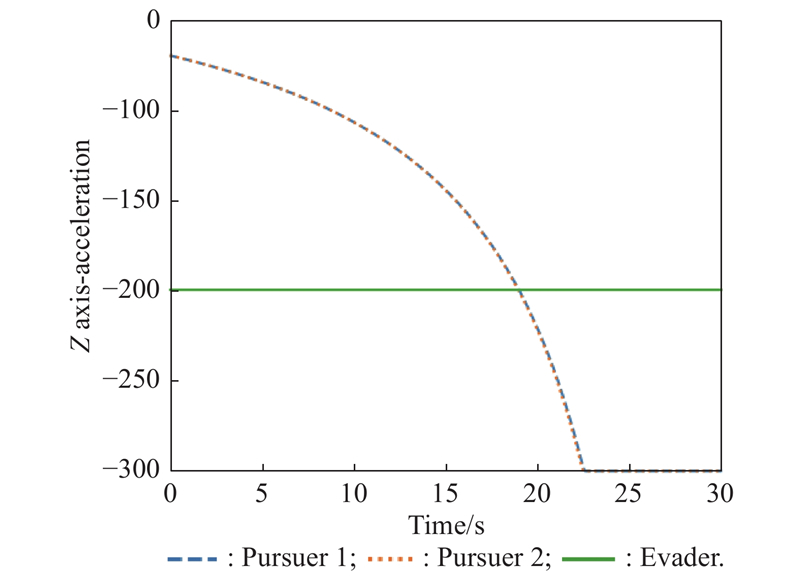

Fig 34
Running time comparison chart"
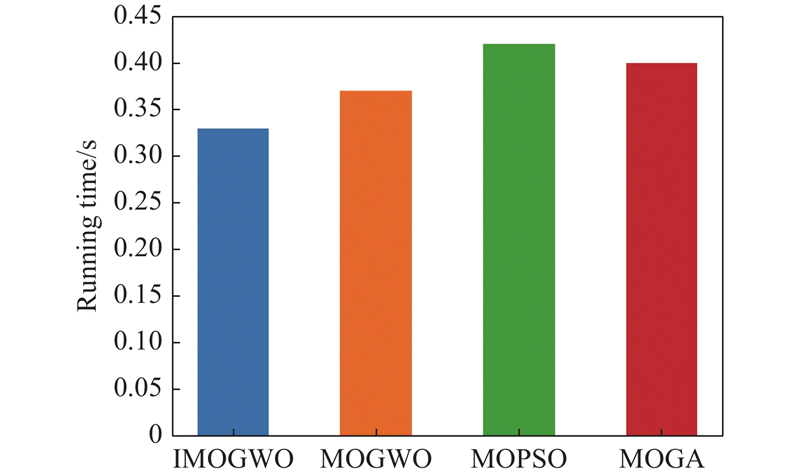
Fig 35
Memory usage comparison chart"
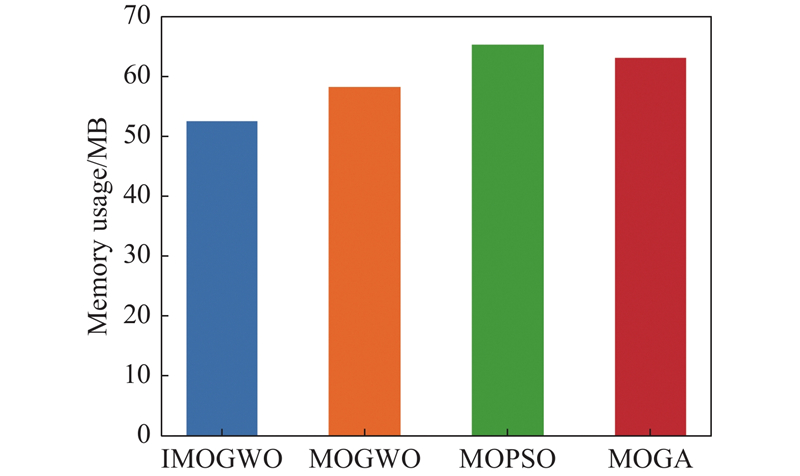
Table 4
Comparison results of the four algorithms"
| Item | Effect | IMOGWO | MOGWO | MOPSO | MOGA |
| Running time/s | Average | 0.33 | 0.37 | 0.42 | 0.40 |
| Midian | 0.32 | 0.43 | 0.46 | 0.45 | |
| Worst | 0.62 | 0.73 | 0.74 | 0.70 | |
| Best | 0.16 | 0.19 | 0.27 | 0.23 | |
| Memory usage/MB | Average | 52.7 | 58.3 | 65.4 | 63,2 |
| Midian | 54.8 | 59.3 | 64.7 | 60.5 | |
| Worst | 62.5 | 64.2 | 70.6 | 71.2 | |
| Best | 50.3 | 56.4 | 62.5 | 56.5 | |
| Mission distance/m | Average | 0.64 | 0.73 | 0.86 | 0.76 |
| Midian | 0.73 | 0.76 | 0.83 | 0.79 | |
| Worst | 0.98 | 0.95 | 0.99 | 0.94 | |
| Best | 0.49 | 0.52 | 0.66 | 0.50 | |
| Accuracy/% | Average | 95 | 88 | 76 | 89 |
Fig 36
Running process"
Fig 37
Final result"
| 1 |
CHEN M, ZHOU Z Y, TOMLIN C J Multiplayer reach-avoid games via pairwise outcomes. IEEE Trans. on Automatic Control, 2017, 62 (3): 1451- 1457.
doi: 10.1109/TAC.2016.2577619 |
| 2 |
SONG S H, HA I J A Lyapunov-like approach to performance analysis of 3-dimensional pure PNG laws. IEEE Trans. on Aerospace and Electronic Systems, 1994, 30 (1): 238- 248.
doi: 10.1109/7.250424 |
| 3 |
ZHAI C, HE F H, HONG Y G, et al Coverage-based interception algorithm of multiple interceptors against the target involving decoys. Journal of Guidance, Control, and Dynamics, 2016, 39 (7): 1647- 1653.
doi: 10.2514/1.G001535 |
| 4 |
OYLER D W, KABAMBA P T, GIRARD A R Pursuit-evasion games in the presence of obstacles. Automatica, 2016, 65, 1- 11.
doi: 10.1016/j.automatica.2015.11.018 |
| 5 |
MAKKAPATI V R, SUN W, TSIOTRAS P Optimal evading strategies for two-pursuer/one-evader problems. Journal of Guidance, Control, and Dynamics, 2018, 41 (4): 851- 862.
doi: 10.2514/1.G003070 |
| 6 | ISAACS R. Differential games. Hoboken: Wiley, 1965. |
| 7 |
MOON J Linear-quadratic stochastic leader-follower differential games for Markov jump-diffusion models. Automatica, 2023, 147, 110713.
doi: 10.1016/j.automatica.2022.110713 |
| 8 |
SUN J, WANG H, WEN J Q Zero-sum Stackelberg stochastic linear-quadratic differential games. SIAM Journal on Control and Optimization, 2023, 61 (1): 252- 284.
doi: 10.1137/21M1450458 |
| 9 |
GOLDYS B, YANG J, ZHOU Z Singular perturbation of zero-sum linear-quadratic stochastic differential games. SIAM Journal on Control and Optimization, 2022, 60 (1): 48- 80.
doi: 10.1137/21M1401802 |
| 10 |
FENG X W, HU Y, HUANG J H Backward Stackelberg differential game with constraints: a mixed terminal-perturbation and linear-quadratic approach. SIAM Journal on Control and Optimization, 2022, 60 (3): 1488- 1518.
doi: 10.1137/20M1340769 |
| 11 |
GARCIA E, CASBEER D W, PACHTER M Optimal strategies for a class of multi-player reach-avoid differential games in 3D space. IEEE Robotics and Automation Letters, 2020, 5 (3): 4257- 4264.
doi: 10.1109/LRA.2020.2994023 |
| 12 |
VON MOLL A, GARCIA E, CASBEER D, et al Multiple-pursuer, single-evader border defense differential game. Journal of Aerospace Information Systems, 2020, 17 (8): 407- 416.
doi: 10.2514/1.I010740 |
| 13 |
XU Y H, YANG H, JIANG B, et al Multiplayer pursuit-evasion differential games with malicious pursuers. IEEE Trans. on Automatic Control, 2022, 67 (9): 4939- 4946.
doi: 10.1109/TAC.2022.3168430 |
| 14 | GARCIA E, WEINTRAUB I, CASBEER D W, et al. Optimal strategies for the game of protecting a plane in 3D. Proc. of the American Control Conference, 2022: 102–107. |
| 15 |
GARCIA E, CASBEER D W, PACHTER M Active target defense using first-order missile models. Automatica, 2017, 78, 139- 143.
doi: 10.1016/j.automatica.2016.12.032 |
| 16 |
GARCIA E Cooperative target protection from a superior attacker. Automatica, 2021, 131, 109696.
doi: 10.1016/j.automatica.2021.109696 |
| 17 | CASBEER G E, CASBEER D W, PACHTER M The target differential game with two defenders. Journal of Intelligent & Robotic Systems, 2018, 89 (1): 87- 106. |
| 18 |
LIANG L, DENG F, PENG Z H, et al A differential game for cooperative target defense. Automatica, 2019, 102, 58- 71.
doi: 10.1016/j.automatica.2018.12.034 |
| 19 |
GARCIA E, CASBEER D W, PACHTER M Optimal strategies of the differential game in a circular region. IEEE Control Systems Letters, 2020, 4 (2): 492- 497.
doi: 10.1109/LCSYS.2019.2963173 |
| 20 |
AUSSEL D, BOUZA G, DEMPE S, et al Genericity analysis of multi-leader-disjoint-followers game. SIAM Journal on Optimization, 2021, 31 (3): 2055- 2079.
doi: 10.1137/20M1356476 |
| 21 |
SINGH S K, REDDY P V, VUNDURTHY B Study of multiple target defense differential games using receding horizon-based switching strategies. IEEE Trans. on Control Systems Technology, 2022, 30 (4): 1403- 1419.
doi: 10.1109/TCST.2021.3104857 |
| 22 |
SU C, HUANG K Design and pricing of maintenance service contract based on Nash non-cooperative game approach. Journal of Systems Engineering and Electronics, 2024, 35 (1): 118- 129.
doi: 10.23919/JSEE.2024.000010 |
| 23 |
ZHENG Y Y, SHI J T A linear-quadratic partially observed Stackelberg stochastic differential game with application. Applied Mathematics and Computation, 2022, 420, 126819.
doi: 10.1016/j.amc.2021.126819 |
| 24 | LO J K C, GARCIA E, MOU S S. Multi-player reach-avoid game in a dynamic environment. Proc. of the IEEE Conference on Control Technology and Applications , 2021: 380–385. |
| 25 |
BURACHIK R S, KAYA C Y, RIZVI M M A new scalarization technique and new algorithms to generate Pareto fronts. SIAM Journal on Optimization, 2017, 27 (2): 1010- 1034.
doi: 10.1137/16M1083967 |
| 26 |
MUELLER-GRITSCHNEDER D, GRAEB H, SCHLICHTMANN U A successive approach to compute the bounded Pareto front of practical multi-objective optimization problems. SIAM Journal on Optimization, 2009, 20 (2): 915- 934.
doi: 10.1137/080729013 |
| 27 |
MIRJALILI S, SAREMI S M, MIRJALILI S M, et al Multi-objective grey wolf optimizer: a novel algorithm for multi-criterion optimization. Expert Systems with Applications, 2016, 47, 106- 119.
doi: 10.1016/j.eswa.2015.10.039 |
| 28 | COELLO COELLO C A, LECHUGA M MOPSO: a proposal for multiple objective particle swarm optimization. Proc. of the Congress on Evolutionary Computation, 2002, 1051- 1056. |
| 29 |
DEB K, PRATAP A, AGARWAL S, et al A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. on Evolutionary Computation, 2002, 6 (2): 182- 197.
doi: 10.1109/4235.996017 |
| 30 |
MIRJALILI S, MIRJALILI S M, LEWIS A Grey wolf optimizer. Advances in Engineering Software, 2014, 69, 46- 61.
doi: 10.1016/j.advengsoft.2013.12.007 |
| 31 |
KUBYANA M S, LANDI P, HUI C Adaptive rock-paper-scissors game enhances eco-evolutionary performance at cost of dynamic stability. Applied Mathematics and Computation, 2024, 468, 128535.
doi: 10.1016/j.amc.2024.128535 |
| 32 |
SHUI Y, LI H, SUN J Y, et al Approximating robust Pareto fronts by the MEOF-based multiobjective evolutionary algorithm with two-level surrogate models. Information Sciences, 2024, 657, 119946.
doi: 10.1016/j.ins.2023.119946 |
| 33 |
DUAN H B, LEI Y Q, XIA J, et al Autonomous maneuver decision for unmanned aerial vehicles via improved pigeon-inspired optimization. IEEE Trans. on Aerospace and Electronic Systems, 2023, 59 (3): 3156- 3170.
doi: 10.1109/TAES.2022.3221691 |
| [1] | Qi WANG, Zhizhong LIAO. Computational intelligence interception guidance law using online off-policy integral reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(4): 1042-1052. |
| [2] | Chengming ZHANG, Yanwei ZHU, Leping YANG, Xin ZENG. An optimal guidance method for free-time orbital pursuit-evasion game [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1294-1308. |
| [3] | Fuyunxiang YANG, Leping YANG, Yanwei ZHU, Xin ZENG. A DNN based trajectory optimization method for intercepting non-cooperative maneuvering spacecraft [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 438-446. |
| [4] | Qilong SUN, Naiming QI, Longxu XIAO, Haiqi LIN. Differential game strategy in three-player evasion and pursuit scenarios [J]. Journal of Systems Engineering and Electronics, 2018, 29(2): 352-366. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||