
Journal of Systems Engineering and Electronics ›› 2026, Vol. 37 ›› Issue (1): 242-256.doi: 10.23919/JSEE.2023.000165
• SYSTEMS ENGINEERING • Previous Articles Next Articles
Weilin YUAN( ), Shaofei CHEN(), Zhenzhen HU(), Xiang JI(), Lina LU(), Xiaolong SU(), Jing CHEN()
), Shaofei CHEN(), Zhenzhen HU(), Xiang JI(), Lina LU(), Xiaolong SU(), Jing CHEN()
Received:2022-12-12
Online:2026-02-18
Published:2026-03-11
Contact:
Shaofei CHEN
E-mail:yuanweilin12@nudt.edu.cn;chensf005@163.com;hzzmail@163.com;jixiang14@nudt.edu.cn;lulina16@nudt.edu.cn;xiaolongsu@nudt.edu.cn;Chenjing001@vip.sina.com
About author:Supported by:Weilin YUAN, Shaofei CHEN, Zhenzhen HU, Xiang JI, Lina LU, Xiaolong SU, Jing CHEN. Optimal competitive resource assignment in two-stage Colonel Blotto game with Lanchester-type attrition[J]. Journal of Systems Engineering and Electronics, 2026, 37(1): 242-256.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
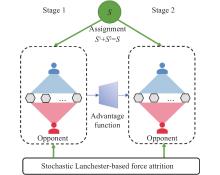
Fig 1
Overview framework"
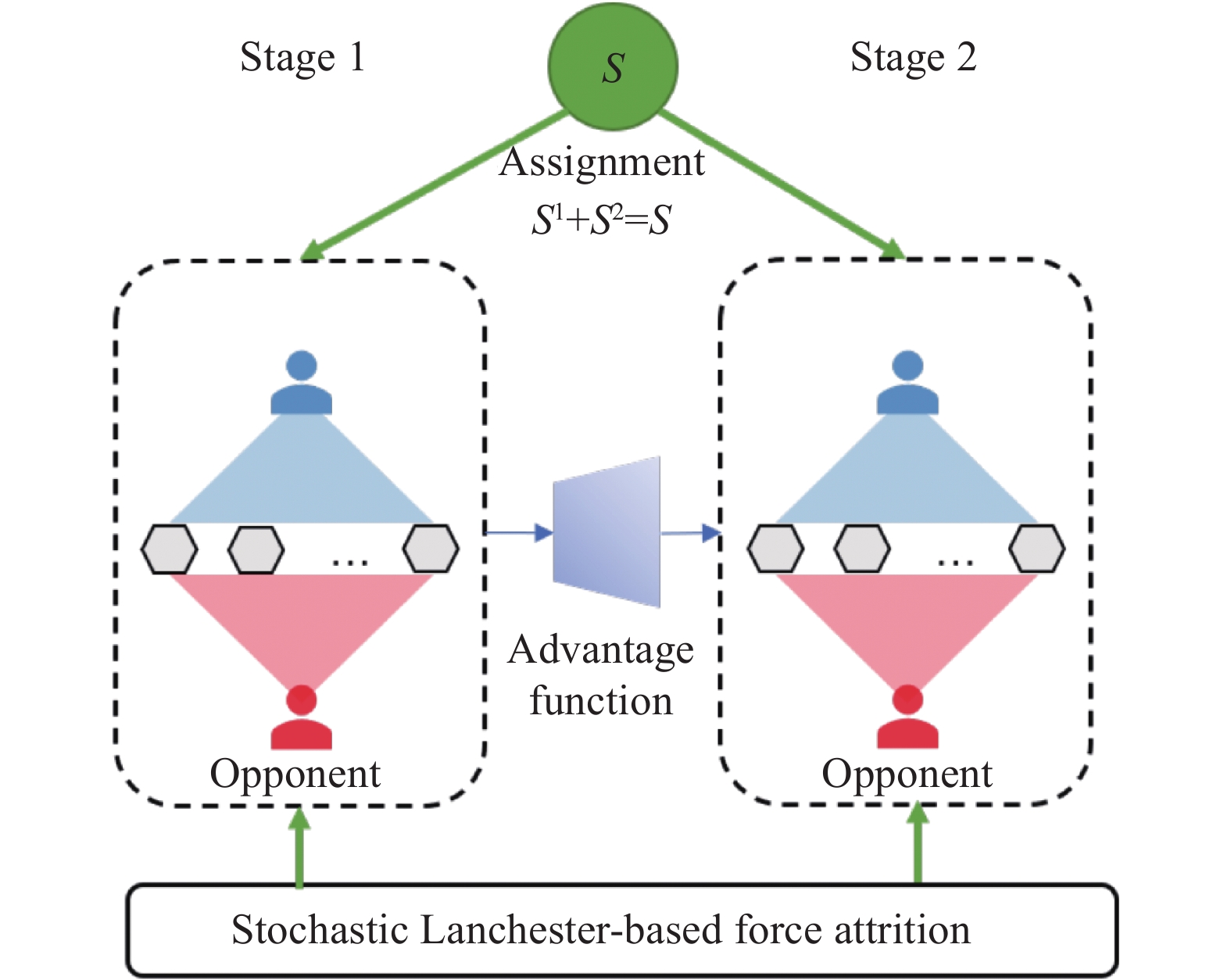
Fig 2
Visualization of stochastic Lanchester-based force attrition ($ {\boldsymbol{n}} \leqslant {\boldsymbol{10}} $)"
Table 1
Time optimal assignment resource strategies in GB-2T with base case parameters ($ {{\boldsymbol{S}}_{\boldsymbol{x}}} {\boldsymbol{=}} {{\boldsymbol{S}}_{\boldsymbol{y}}} {\boldsymbol{= s}} $)"
| Condition | Parameter | Result in CB-2T | |||
| c1 | c2 | κ(x) | x(1) | x(2) | |
| (0,0) | (2,3) | ||||
| (0,1) | (4,0) | ||||
| (1,1) | (3,0) | ||||
| (1,1) | (2,1) | ||||
| (1,1) | (3,0) | ||||
| (0,0,0) | (5,4,1) | ||||
| (0,1,1) | (8,0,0) | ||||
| (1,2,2) | (5,0,0) | ||||
| (2,0,2) | (0,6,0) | ||||
| (2,2,2) | (4,0,0) | ||||
Table 2
Performance of RM-2T against two-stage visible baselines by playing 10 000 CB-2T game under the uncertainty from SLE"
| Algorithm | RM-2T | DQN-2T | Rand-2T | |||||
| WP/% | AWR | WP/% | AWR | WP/% | AWR | |||
| RM-2T | — | — | 51.5 | −0.110 | 78.0 | 0.361 | ||
| DQN-2T | 48.5 | −0.181 | — | — | 89.4 | 0.588 | ||
| Rand-2T | 22.0 | −0.711 | 10.6 | -0.928 | — | — | ||
Table 3
Performance of RM-2T against one-stage visible baselines by playing 10 000 CB-2T game under the uncertainty from SLE"
| Algorithm | RM-2T | Rand-T1 | Rand-T2 | |||||
| WP/% | AWR | WP/% | AWR | WP/% | AWR | |||
| RM-2T | — | — | 54.0 | −0.120 | 76.1 | 0.382 | ||
| Rand-T1 | 46.0 | −0.280 | — | — | 83.4 | 0.468 | ||
| Rand-T2 | 23.9 | −0.622 | 16.6 | −0.768 | — | — | ||
Table 4
Results of pre-allocated resource assignment with total resource $ {{\boldsymbol{S}}_{\boldsymbol{x}}} {\boldsymbol{= 10}} $ and the number of battlefields $ {\boldsymbol{n}} {\boldsymbol{= 3}} $, $ {{\boldsymbol{c}}_{\boldsymbol{1}}} {\boldsymbol{=}} {\boldsymbol{0.2}} $, $ {{\boldsymbol{c}}_{\boldsymbol{2}}} {\boldsymbol{= 0.1}} $"
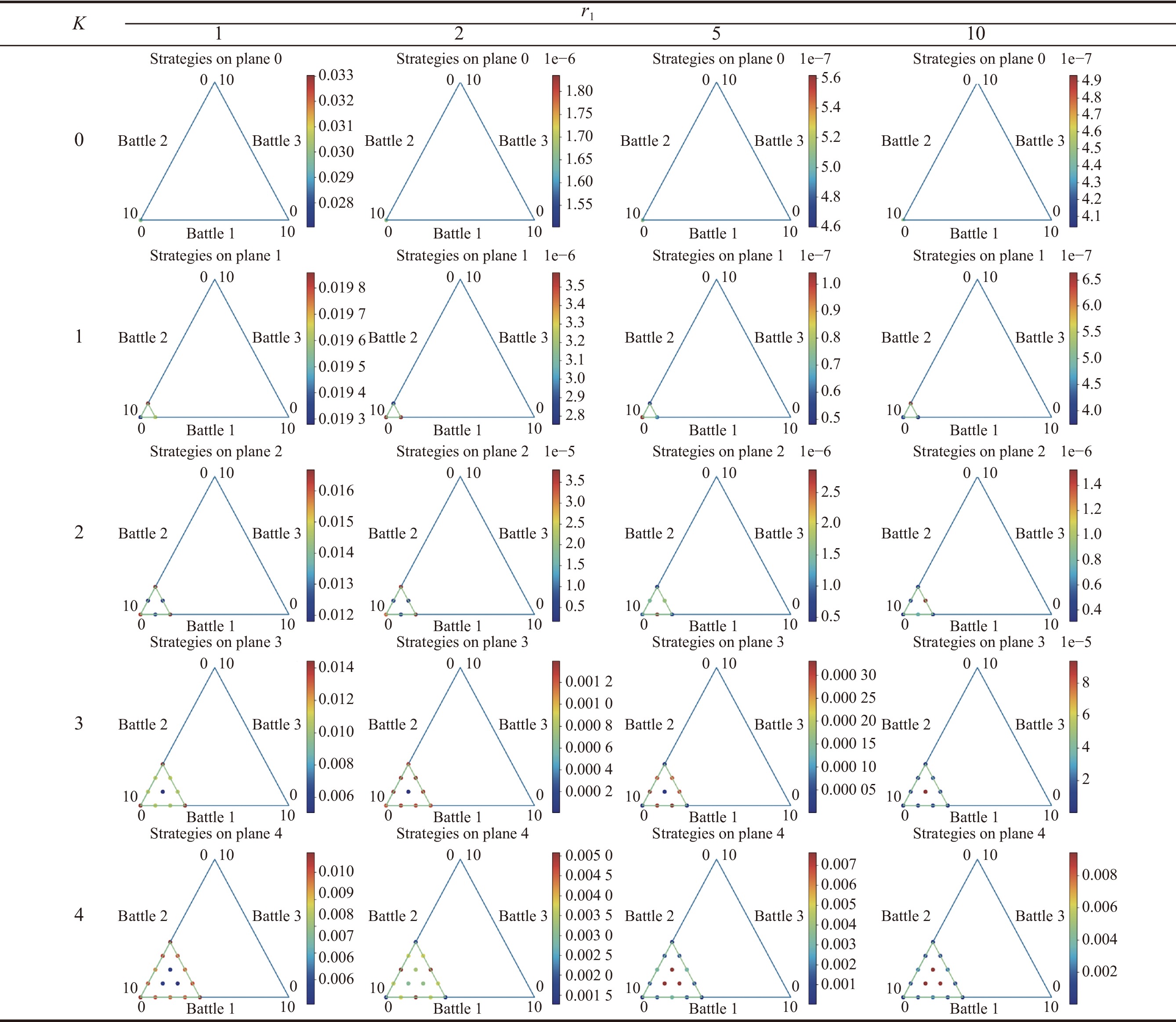 |
Table 5
Results of pre-allocated resource assignment with total resource $ {{\boldsymbol{S}}_{\boldsymbol{x}}} {\boldsymbol{= 10}} $ and the number of battlefields $ {\boldsymbol{n}} {\boldsymbol{= 3}} $, $ {{\boldsymbol{c}}_{\boldsymbol{1}}} {\boldsymbol{=}} {\boldsymbol{0.2}} $, $ {{\boldsymbol{c}}_{\boldsymbol{2}}} {\boldsymbol{= 0.1}} $"
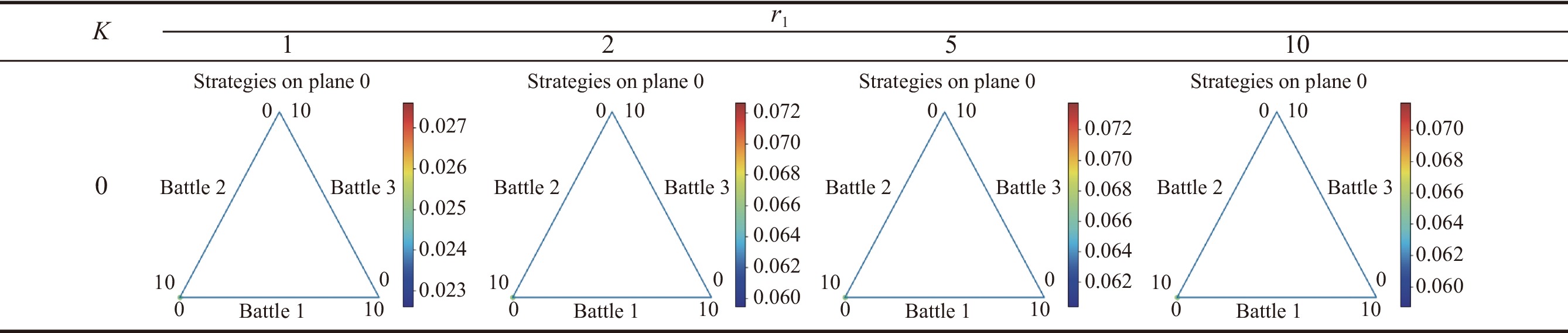 |

Fig 6
Results of pre-allocated resource assignment with total resource $ {{\boldsymbol{S}}_{\boldsymbol{x}}} {\boldsymbol{= 10}} $ and the number of battlefields $ {\boldsymbol{n = 3}} $, $ {{\boldsymbol{r}}_{\boldsymbol{1}}} {\boldsymbol{= 2}} $"
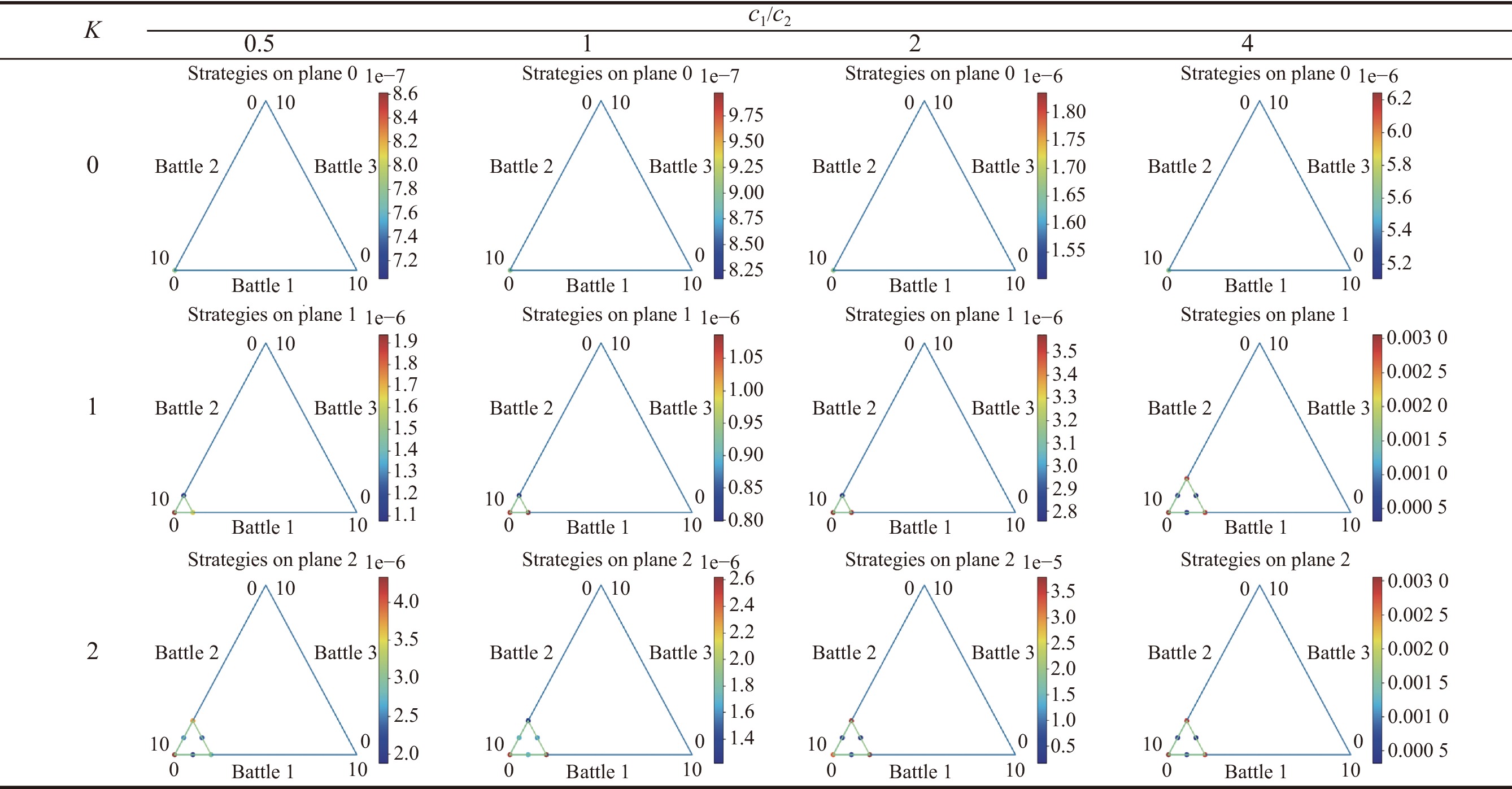

Fig 7
Results of support resource assignment with total resource $ {{\boldsymbol{S}}_{\boldsymbol{x}}} {\boldsymbol{= 10}} $ and the number of battlefields $ {\boldsymbol{n = 3}} $, $ {{\boldsymbol{r}}_{\boldsymbol{1}}} {\boldsymbol{= 2}} $"
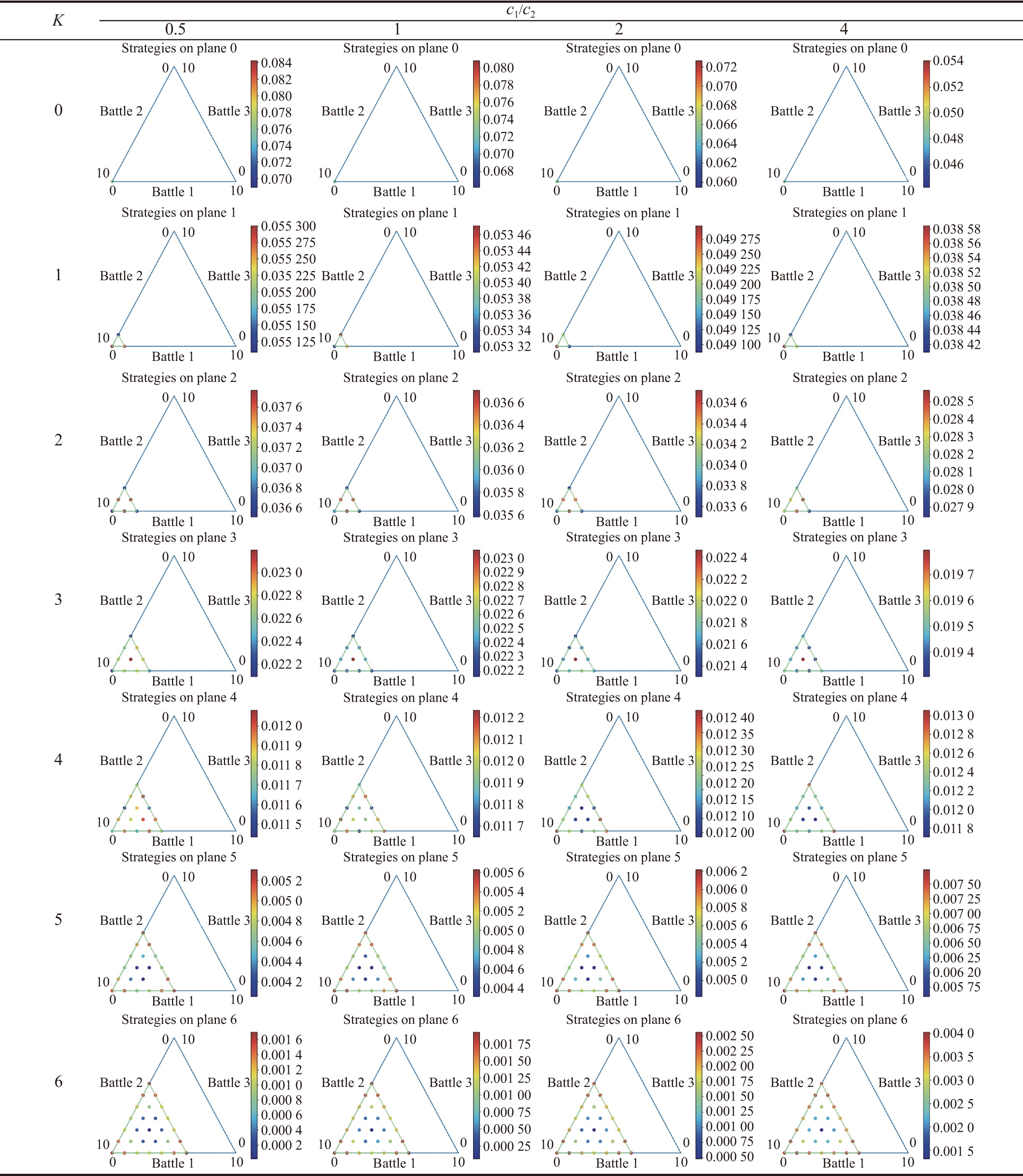
| 1 |
ROBERSON B The Colonel Blotto game. Economic Theory, 2006, 29 (1): 1- 24.
doi: 10.1007/s00199-005-0071-5 |
| 2 |
DAN K, ROBERSON B Coalitional Colonel Blotto games with application to the economics of alliances. Journal of Public Economic Theory, 2012, 14 (4): 653- 676.
doi: 10.1111/j.1467-9779.2012.01556.x |
| 3 | MASUCCI A M, SILVA A. Strategic resource allocation for competitive influence in social networks. https://doi.org/10.48550/arXiv.1402.5388. |
| 4 | KUMAR D, SINGH A S. A survey on resource allocation techniques in cloud computing. Proc. of the International Conference on Computing, Communication & Automation, 2015: 655−660. |
| 5 | SCHWARTZ G, LOISEAU P, SASTRY S S. The heterogeneous Colonel Blotto game. Proc. of the International Conference on Network Games, 2017: 232−238. |
| 6 | ADAM L, HORCIK R, KASL T, et al. Double oracle algorithm for computing equilibria in continuous games. Proc. of the National Conference on Artificial Intelligence, 2021, 35(6): 5070−5077. |
| 7 | GUPTA A, BASAR T, SCHWARTZ G A. A three-stage Colonel Blotto game: when to provide more information to an adversary. Proc. of the International Conference on Decision and Game Theory for Security, 2014: 216−233. |
| 8 | KOVENOCK D, MAUBOUSSIN M J, ROBERSON B Asymmetric conflicts with endogenous dimensionality. Korean Economic Review, 2010, 26 (1): 287- 305. |
| 9 |
AYTON A, PRESTON P, AUTRAND F, et al The battle of crecy. The Journal of Military History, 2005, 69 (4): 1198- 1199.
doi: 10.1353/jmh.2005.0214 |
| 10 | LI X M, ZHENG J. Pure strategy Nash equilibrium in 2-contestant generalized lottery Colonel Blotto games. Social Science Electronic Publishing, 2022, 103: 102771. |
| 11 |
HAN Q, LI W M, XU Q L, et al Lanchester equation for cognitive domain using hesitant fuzzy linguistic terms sets. Journal of Systems Engineering and Electronics, 2022, 33 (3): 674- 682.
doi: 10.23919/JSEE.2022.000062 |
| 12 |
CANGIOTTI N, CAPOLLI M, MATTIA S A generalization of unaimed fire Lanchester’s model in multi-battle warfare. Operational Research, 2023, 23 (2): 38- 57.
doi: 10.1007/s12351-023-00776-8 |
| 13 | FENG B S, ZHOU X G, LIN Y J Study of air combat efficiency of carrier-borne fighter based on stochastic Lanchester battle theory. Computer Technology and Development, 2013, 23 (5): 199- 201. |
| 14 |
DEITCHMANS J A Lanchester model of guerrilla warfare. Operations Research, 1962, 10 (6): 818- 827.
doi: 10.1287/opre.10.6.818 |
| 15 |
TAYLOR J G, BROWN G G Further canonical methods in the solution of variable-coefficient Lanchester-type equations of modern warfare. Operations Research, 1976, 24 (1): 44- 69.
doi: 10.1287/opre.24.1.44 |
| 16 | MACKAY N J. Lanchester combat models. https://arxiv.org/abs/math/0606300. |
| 17 |
KRESS M, LIN K Y, MACKAY N J The attrition dynamics of multilateral war. Operation Research, 2018, 66 (4): 950- 956.
doi: 10.1287/opre.2018.1718 |
| 18 |
KALLONIATIS A C, HOEK K, ZUPARIC M, et al Optimising structure in a networked Lanchester model for fires and manoeuvre in warfare. Journal of the Operational Research Society, 2021, 72 (8): 1863- 1878.
doi: 10.1080/01605682.2020.1745701 |
| 19 |
ZUPARIC M, SHELYAG S, ANGELOVA M, et al Modelling host population support for combat adversaries. Journal of the Operational Research Society, 2023, 74 (3): 928- 943.
doi: 10.1080/01605682.2022.2122736 |
| 20 | CHEN X Y, JING Y W, LI C J, et al Analysis of optimum strategy using Lanchester equation for naval battles like Trafalgar. Journal of Northeastern University, 2009, 30 (4): 535- 538. |
| 21 |
JI X, ZHANG W P, XIANG F T, et al A swarm confrontation method based on Lanchester law and Nash equilibrium. Electronics, 2022, 11 (6): 896- 911.
doi: 10.3390/electronics11060896 |
| 22 | CHE Y K, GALE I Difference-form contests and the robustness of all-pay auctions. Games & Economic Behavior, 2000, 30 (1): 22- 43. |
| 23 | ALCALDE J, DAHM M Tullock and Hirshleifer: a meeting of the minds. Review of Economic Design, 2007, 11 (1): 101- 124. |
| 24 |
DAHM L C Foundations for contest success functions. Economic Theory, 2010, 43 (1): 81- 98.
doi: 10.1007/s00199-008-0425-x |
| 25 | DONG Q V. Models and solutions of strategic resource allocation problems: approximate equilibrium and online learning in Blotto games. Paris: Sorbonne University, 2020. |
| 26 | DONG Q V, LOISEAU P, SILVA A. Approximate equilibria in non-constant-sum Colonel Blotto and lottery Blotto games with large numbers of battlefields. https://arxiv.org/abs/1910.06559v1. |
| 27 | TODD W N, MARC L An introduction to counterfactual regret minimization. Proc. of the 4th Symposium on Educational Advances in Artificial Intelligence, 2013, 11, 1- 38. |
| 28 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning. https://arxiv.org/pdf/1312.5602.pdf. |
| 29 | ZHA D C, XIE J R, MA W Y, et al. DouZero: mastering DouDizhu with self-play deep reinforcement learning. https://arxiv.org/pdf/2106.06135.pdf. |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||