
Journal of Systems Engineering and Electronics ›› 2023, Vol. 34 ›› Issue (5): 1211-1224.doi: 10.23919/JSEE.2023.000128
• Systems Engineering • Previous Articles Next Articles
Yaozhong ZHANG1,*( ), Zhuoran WU1(), Zhenkai XIONG2(), Long CHEN3()
), Zhuoran WU1(), Zhenkai XIONG2(), Long CHEN3()
Received:2021-11-12
Online:2023-10-18
Published:2023-10-30
Contact:
Yaozhong ZHANG
E-mail:zhang_y_z@nwpu.edu.cn;542391943@qq.com;1223959392@qq.com;dragon-cl@sohu.com
About author:Supported by:Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm[J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224.
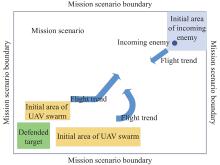
Fig 1
Schematic diagram of UAV swarm defensive mission"
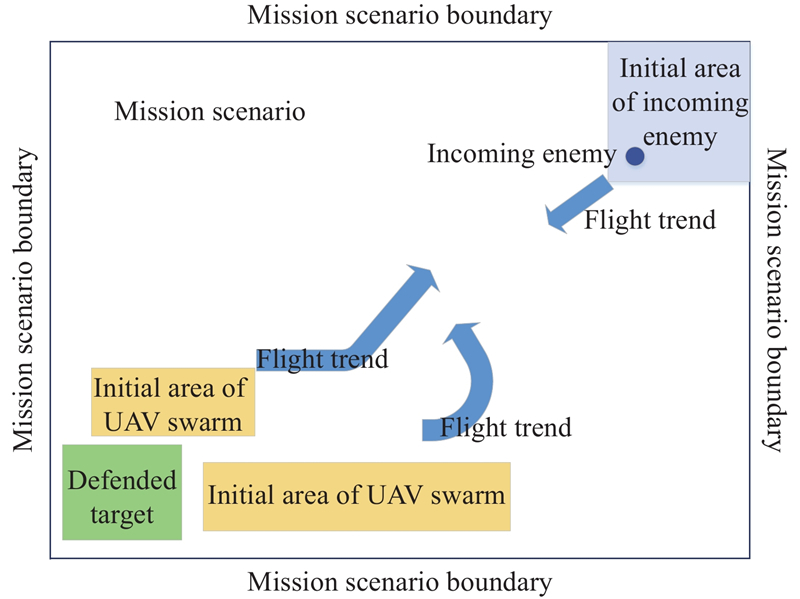
Fig 2
Schematic diagram of pure tracking attack"
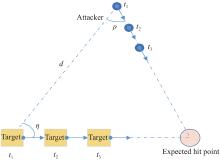
Fig 3
Schematic diagram of a pure collision attack"
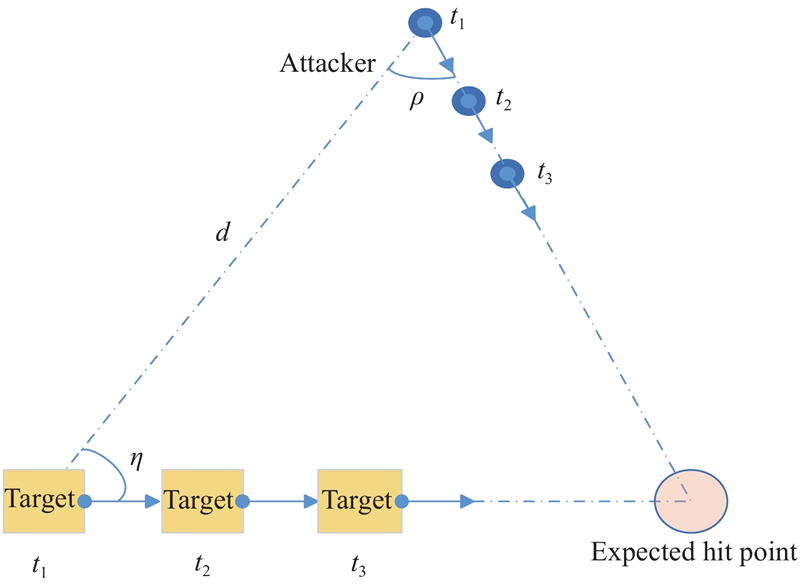
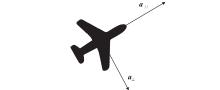
Fig 4
UAV acceleration model diagram"
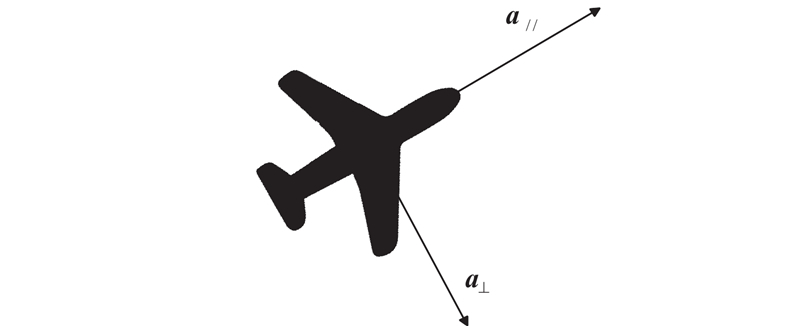

Fig 5
UAV kinematics model diagram"
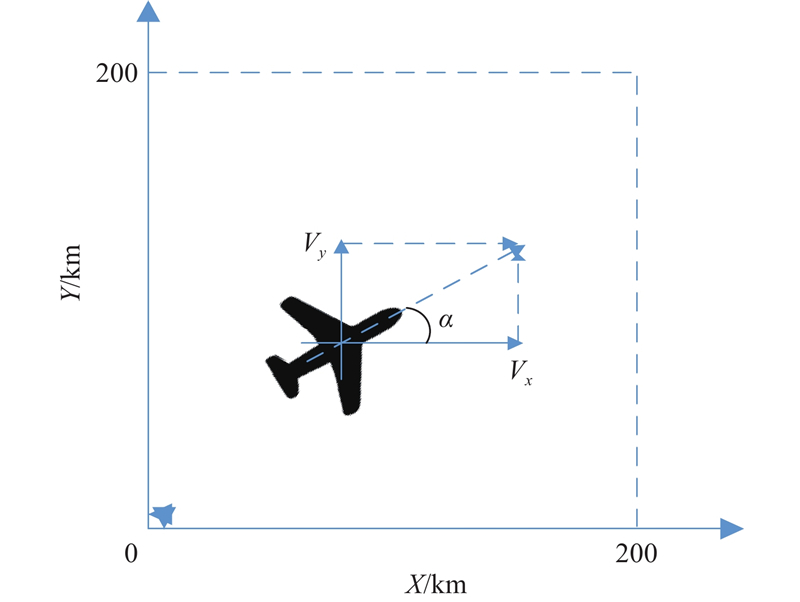
Fig 6
Schematic diagram of UAVs communication"
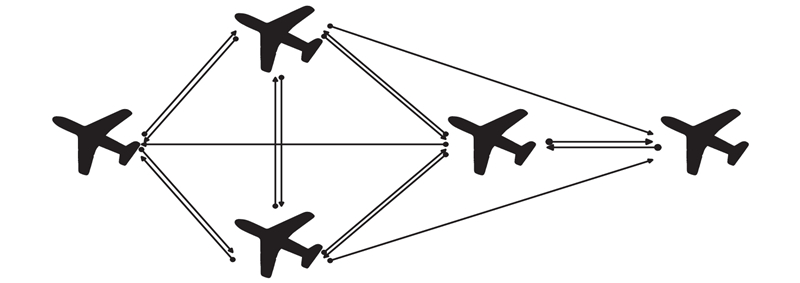
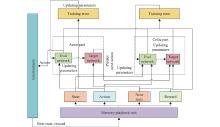
Fig 7
Structure of the DDPG algorithm"
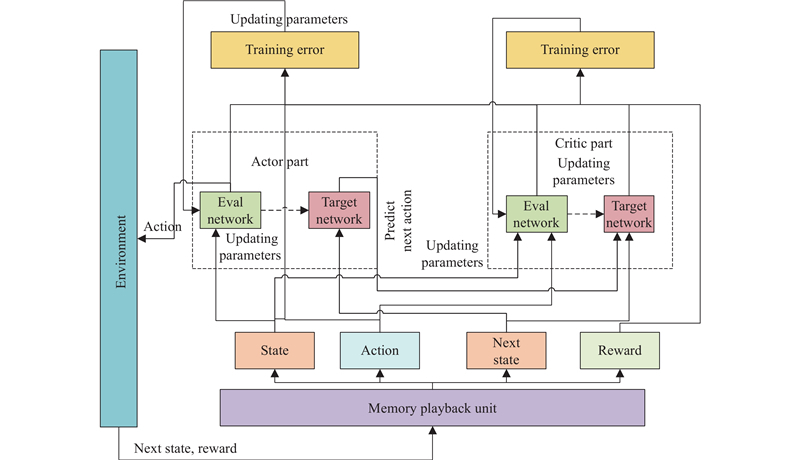

Fig 8
State space of UAV swarm"
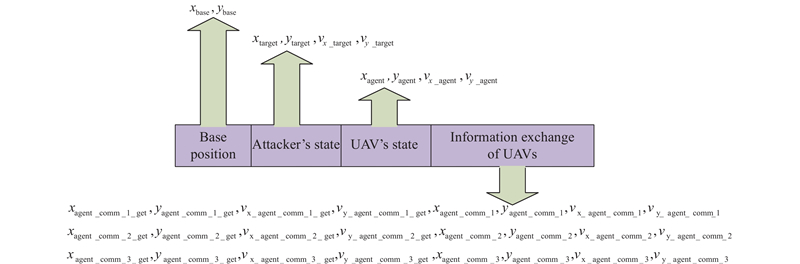
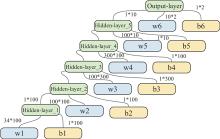
Fig 9
Artificial neural network structure of the “actor’s part”"
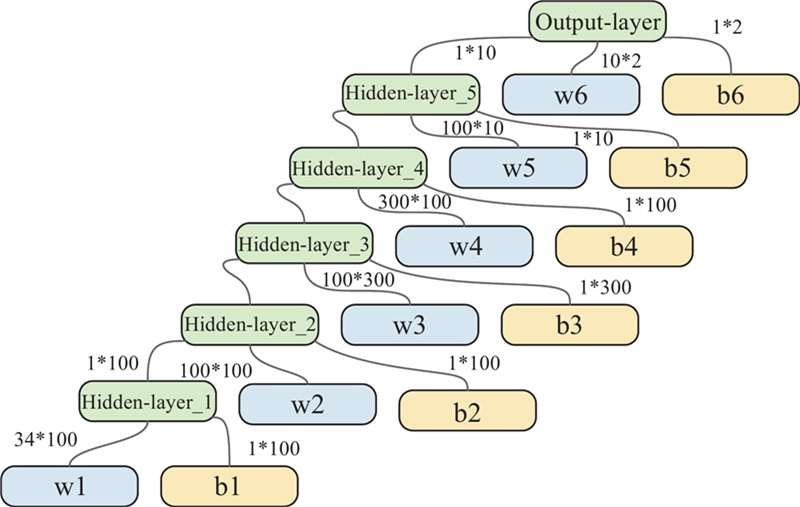
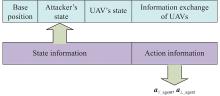
Fig 10
Input data structure of “critic section” neural network"
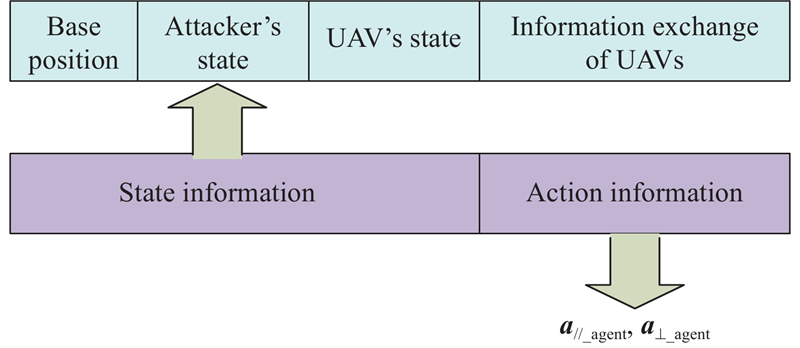
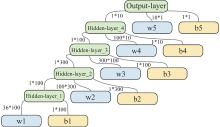
Fig 11
Artificial neural network structure of the “critic” part"
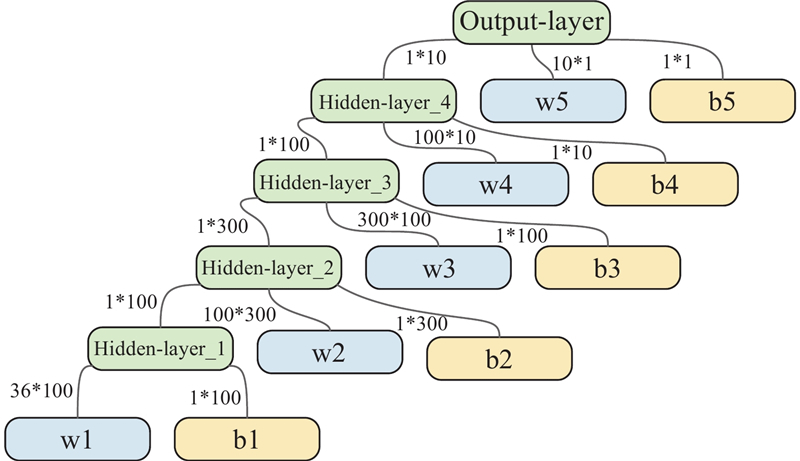
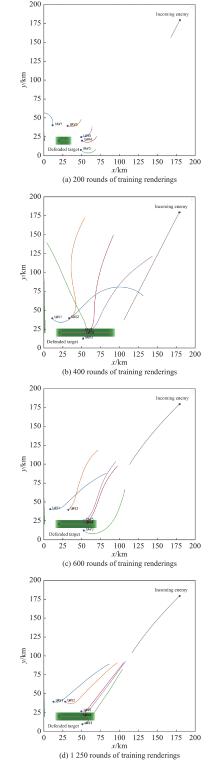
Fig 12
Snapshots of different training epochs"
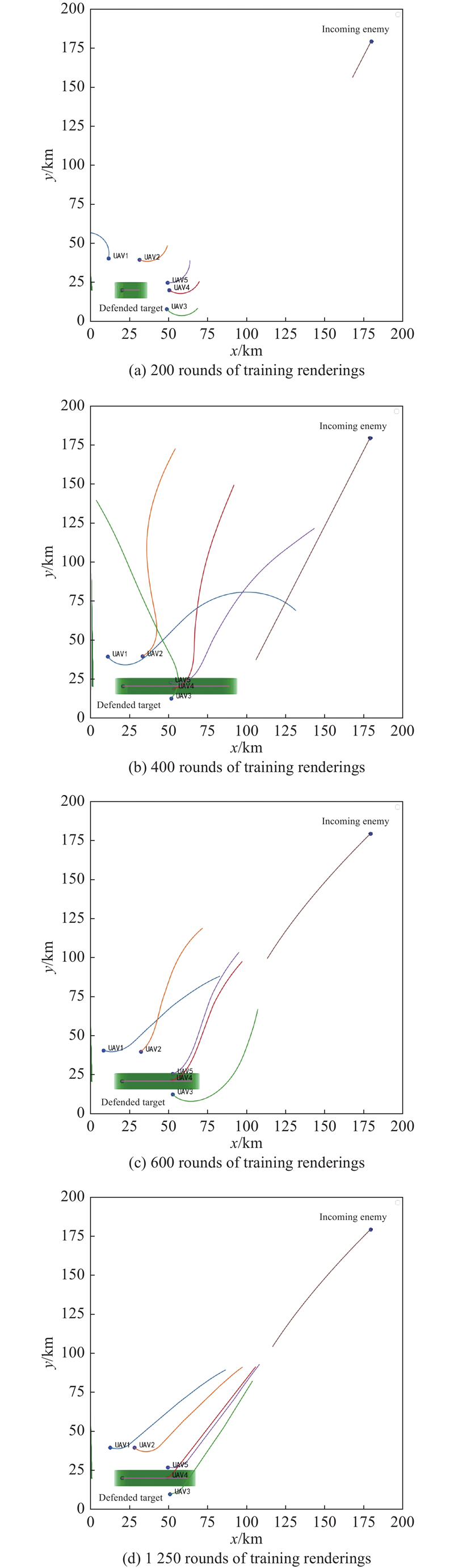
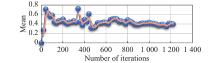
Fig 13
Mean changes of network parameters in “critic” section from Eval network"
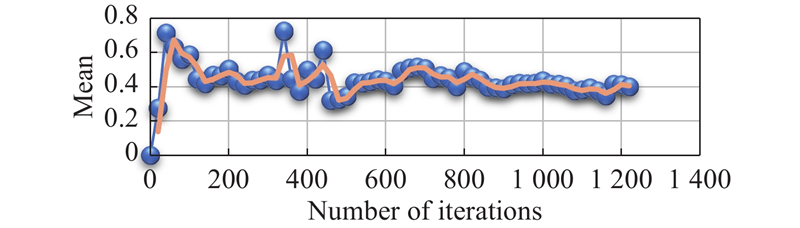
Fig 14
Variance changes of network parameters in “critic” section from Eval network"
Fig 15
Mean changes of network parameters in “actor” section from Eval network"
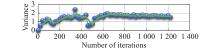
Fig 16
Variance changes of network parameters in “actor” section from Eval network"
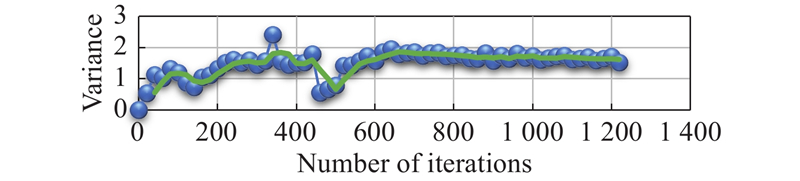
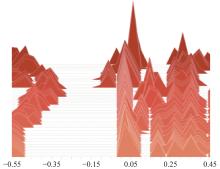
Fig 17
Changes of Target network parameters distribution in the “actor” section"
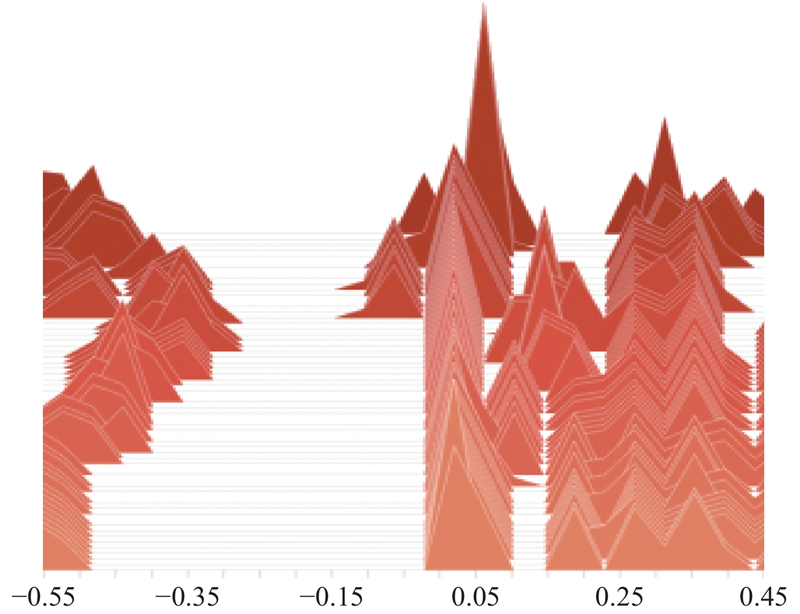
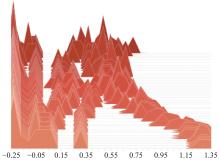
Fig 18
Changes of Target network parameters distribution in the “critic” section"
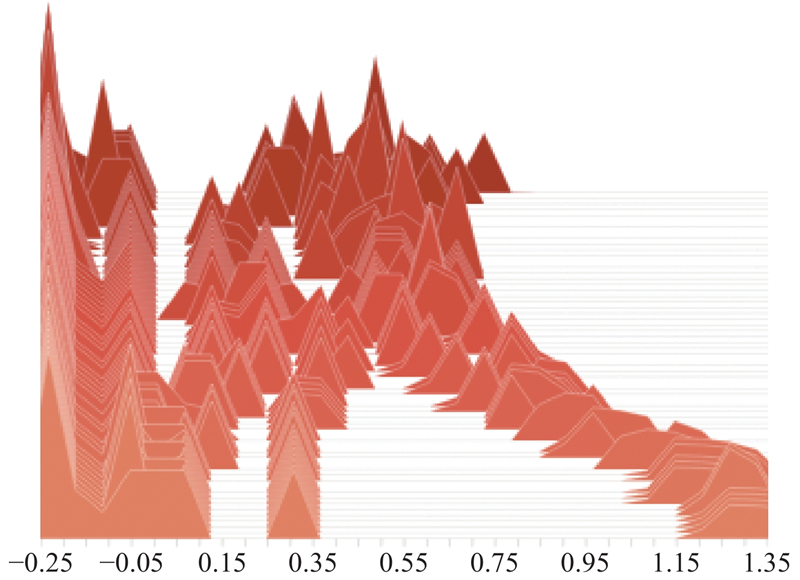
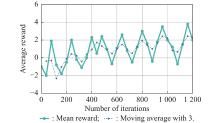
Fig 19
Mean reward of samples in different epochs"
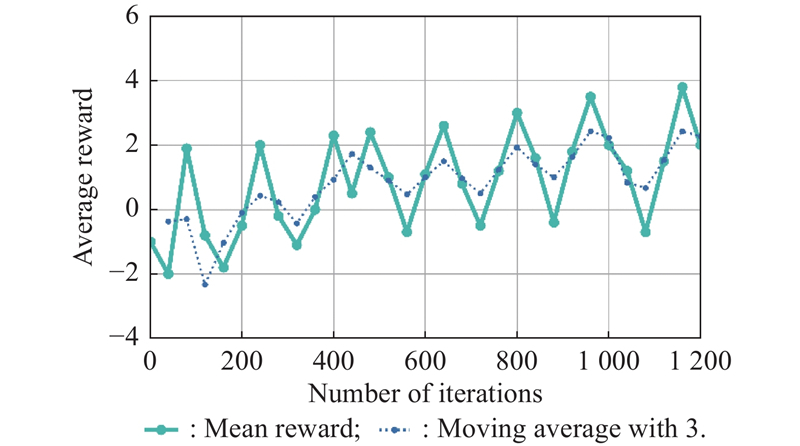
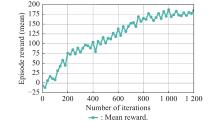
Fig 20
Mean episode reward under different training rounds"
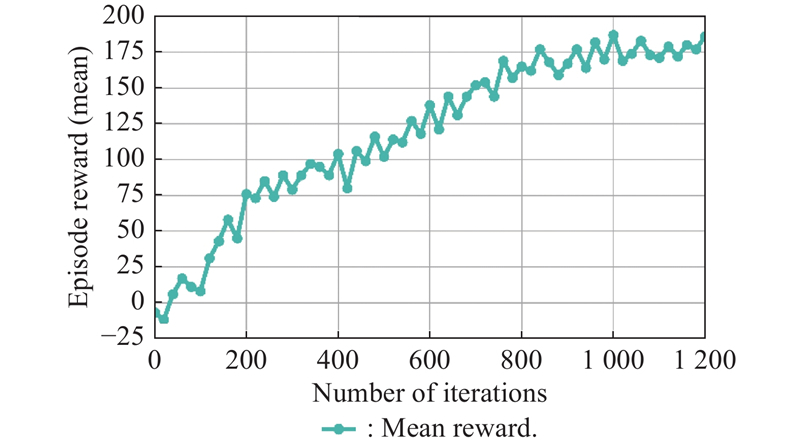
Fig 21
Task completion rate for UAV swarm"
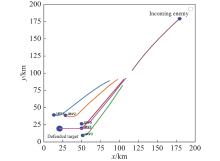
Fig 22
Trajectory of five UAVs in a defense mission"
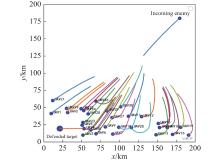
Fig 23
Trajectory of 30 UAVs in defense mission"
| 1 |
ZHANG Q X, JIANG M L, FENG Z Y IoT enabled UAV: network architecture and routing algorithm. IEEE Internet of Things Journal, 2019, 6 (2): 3727- 3742.
doi: 10.1109/JIOT.2018.2890428 |
| 2 |
LAN T, QIN D, SUN G Joint optimization on trajectory, cache placement, and transmission power for minimum mission time in UAV-aided wireless networks. International Journal of Geo-Information, 2021, 10 (7): 426.
doi: 10.3390/ijgi10070426 |
| 3 |
ARAFAT M Y, MOH S Localization and clustering based on swarm intelligence in UAV networks for emergency communications. IEEE Internet of Things Journal, 2019, 6 (5): 8958- 8976.
doi: 10.1109/JIOT.2019.2925567 |
| 4 |
MUKHERJEE A, MISRA S, CHANDRA V S P, et al Resource-optimized multiarmed bandit-based offload path selection in edge UAV swarms. IEEE Internet of Things Journal, 2019, 6 (3): 4889- 4896.
doi: 10.1109/JIOT.2018.2879459 |
| 5 |
CHANDARANA M, MESZAROS E L, TRUJILLO A, et al Natural language based multimodal interface for UAV mission planning. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 2017, 61 (1): 68- 72.
doi: 10.1177/1541931213601483 |
| 6 | CHANDARANA M, MESZAROS E L, TRUJILLO A, et al. “Fly like this”: natural language interface for UAV mission planning. Proc. of the International Conference on Advances in Computer-Human Interactions, 2017: 1−7. |
| 7 | XU G Q, JIANG W L, WANG Z L, et al Autonomous obstacle avoidance and target tracking of UAV based on deep reinforcement learning. Journal of Intelligent & Robotic Systems, 2022, 104 (4): 1- 13. |
| 8 |
HU Y, CHEN M Z, SAAD W, et al Distributed multi-agent meta learning for trajectory design in wireless drone networks. IEEE Journal on Selected Areas in Communications, 2021, 39 (10): 3177- 3192.
doi: 10.1109/JSAC.2021.3088689 |
| 9 |
WANG H, LI Y M, QIAN J B Self-adaptive resource allocation in underwater acoustic interference channel: a reinforcement learning approach. IEEE Internet of Things Journal, 2020, 7 (4): 2816- 2827.
doi: 10.1109/JIOT.2019.2962915 |
| 10 | LI G L, MA Y F Feature extraction algorithm of air combat situation based on deep neural networks. Journal of System Simulation, 2017, 29 (S1): 98- 105, 112. |
| 11 | HANG W. Research of UCAV air combat based on reinforcement learning. Harbin: Harbin Institute of Technology, 2015. (in Chinese) |
| 12 | XU Y H, XIE J W, ZHANG Y G, et al Reinforcement learning (RL)-based energy efficient resource allocation for energy harvesting-powered wireless body area network. Sensors, 2020, 20 (44): 1- 22. |
| 13 | LI Q Y, YAO H P, MAI T L, et al. Reinforcement and belief learning-based double auction mechanism for edge computing resource allocation. IEEE Internet of Things Journal. 2020, 7(7): 5976−5985. |
| 14 |
WANG S Y, DUAN J J, SHI D, et al A data-driven multi-agent autonomous voltage control framework using deep reinforcement learning. IEEE Trans. on Power Systems, 2020, 35 (6): 4644- 4654.
doi: 10.1109/TPWRS.2020.2990179 |
| 15 | LIU P, MA Y F. A deep reinforcement learning based intelligent decision method for UCAV air combat. Proc. of the Asian Simulation Conference, 2017: 274−286. |
| 16 | PRICE J K, PINON-FISCHER O J, MAVRIS D N. Definition of optimal agent behaviors using reinforcement learning. Proc. of the AIAA Scitech Forum, 2019. DOI: 10.2514/6.2019-2200. |
| 17 | LUO D L, YANG X, ZHANG J P, et al New progress on UAV swarm confrontation. Science & Technology Review, 2017, 35 (7): 26- 31. |
| 18 |
HU J W, WANG L H, HU T, et al Autonomous maneuver decision making of dual-UAV cooperative air combat based on deep reinforcement learning. Electronics, 2022, 11 (3): 467.
doi: 10.3390/electronics11030467 |
| 19 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al Human level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 20 | SILVER D, LEVER G, HEESS N. Deterministic policy gradient algorithms. Proc. of the 31st International Conference on International Conference on Machine Learning, 2014: 387−395. |
| 21 | SHI H B, SUN Y R, LI J. Dynamical motor control learned with deep deterministic policy gradient. Computational Intelligence and Neuroscience, 2018, 2018: 8535429 |
| 22 |
ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al A brief survey of deep reinforcement learning. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38.
doi: 10.1109/MSP.2017.2743240 |
| 23 | WANG G H, SHI J L. Actor-critic for multi-agent system with variable quantity of agents. Proc. of the International Conference on Internet of Things as a Service, 2018: 48−56. |
| 24 | HUANG W R, WANG Y Z, YI X D. A deep reinforcement learning approach to preserve connectivity for multi-robot systems. Proc. of the 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, 2017: 1−7. |
| 25 | YI H. Deep deterministic policy gradient for autonomous vehicle driving. Proc. of the International Conference on Artificial Intelligence, 2018: 191−194. |
| 26 | ANDERSEN P A, GOODWIN M, GRANMO O C. Deep RTS: a game environment for deep reinforcement learning in real-time strategy games. Proc. of the IEEE Conference on Computational Intelligence and Games, 2018: 1−8. |
| 27 | NIE H H, CHEN Y, SONG Y K, et al A general real-time OPF algorithm using DDPG with multiple simulation platforms. Proc. of the IEEE Innovative Smart Grid Technologies, 2019, 3713- 3718. |
| [1] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [2] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [3] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [4] | Ang GAO, Qisheng GUO, Zhiming DONG, Zaijiang TANG, Ziwei ZHANG, Qiqi FENG. Research on virtual entity decision model for LVC tactical confrontation of army units [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1249-1267. |
| [5] | Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||