
Journal of Systems Engineering and Electronics ›› 2023, Vol. 34 ›› Issue (2): 360-373.doi: 10.23919/JSEE.2023.000056
• SYSTEMS ENGINEERING • Previous Articles
Yaozhong ZHANG( ), Yike LI(), Zhuoran WU, Jialin XU
), Yike LI(), Zhuoran WU, Jialin XU
Received:2021-01-08
Online:2023-04-18
Published:2023-04-18
Contact:
Yaozhong ZHANG
E-mail:zhang_y_z@nwpu.edu.cn;liyike@mail.nwpu.edu.cn
About author:Supported by:Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior[J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
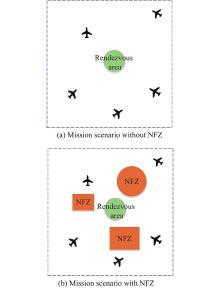
Fig 1
Mission scenario of UAV swarm rendezvous task"
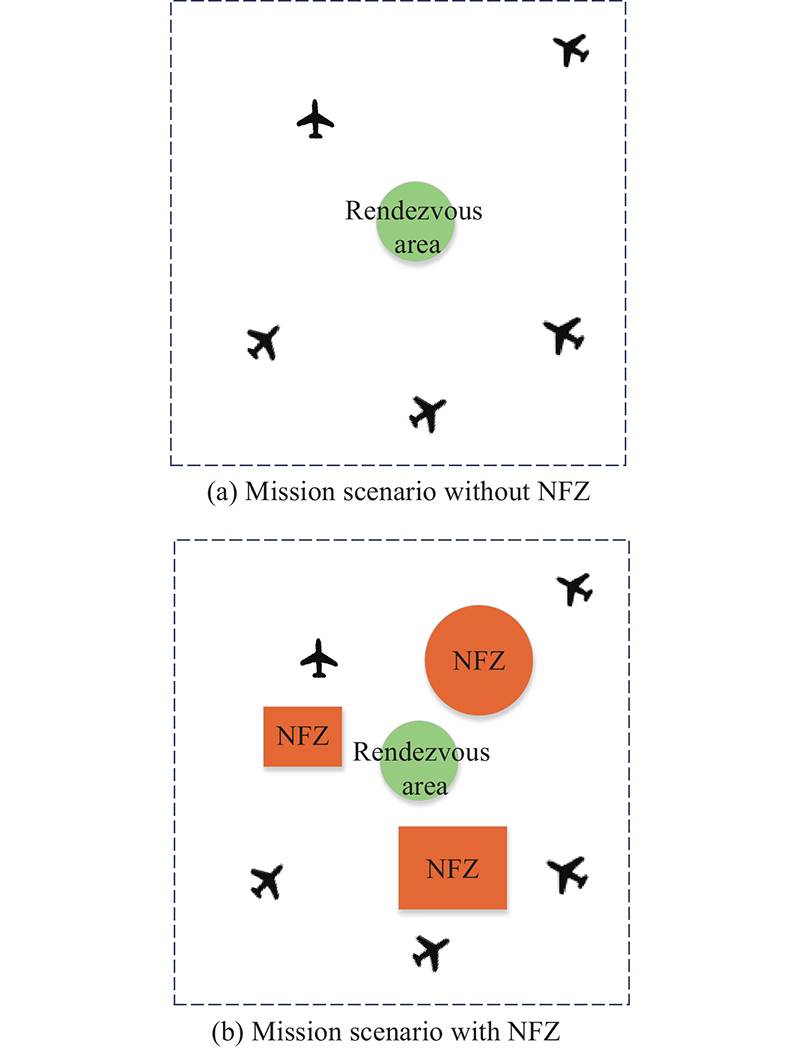
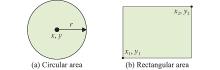
Fig 2
Unified simplified model of NFZ with circular or rectangular shape"
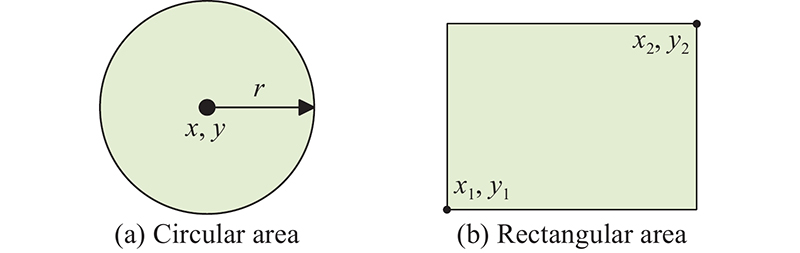
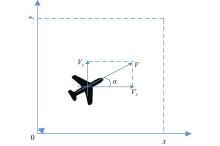
Fig 3
Motion control model of the UAV"
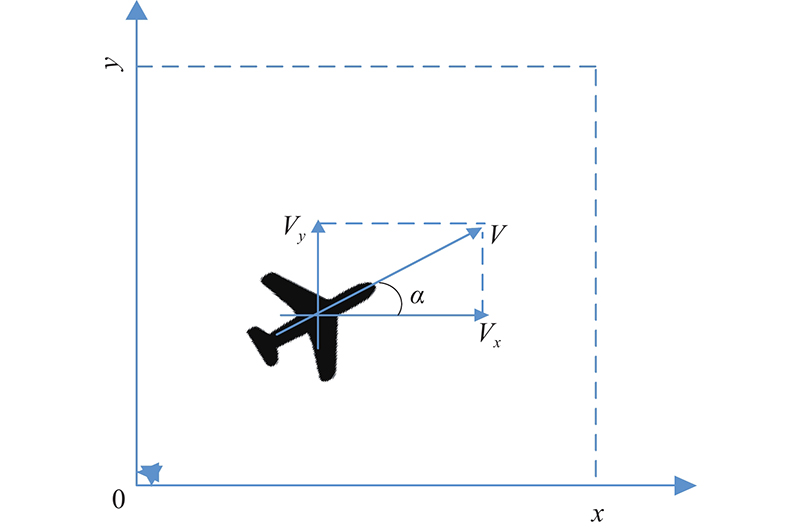
Fig 4
Acceleration control model of the UAV"
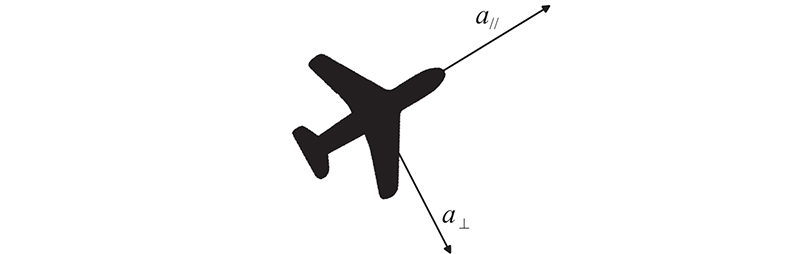
Table 1
Control variables of UAV"
| ID | Control variable | Value size |
| 1 | | +2 |
| 2 | | +1 |
| 3 | | 0 |
| 4 | | −1 |
| 5 | | −2 |
| 6 | | +2 |
| 7 | | +1 |
| 8 | | 0 |
| 9 | | −1 |
| 10 | | −2 |
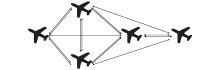
Fig 5
Information interaction diagram of UAVs"
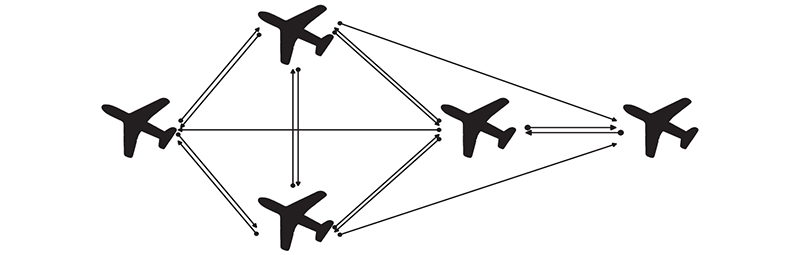
Fig 6
Framework of DDQN algorithm"
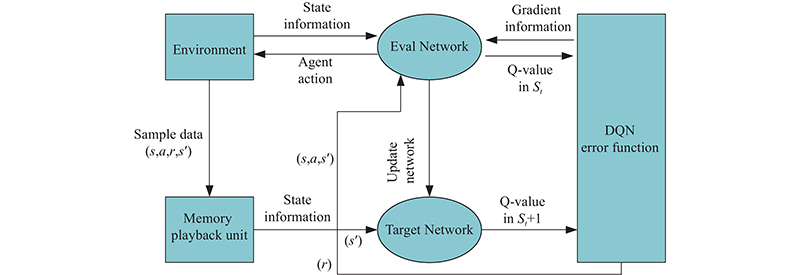
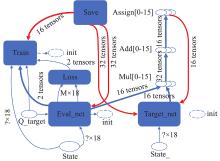
Fig 7
Networks model diagram of the DDQN algorithm (from tensorboard)"
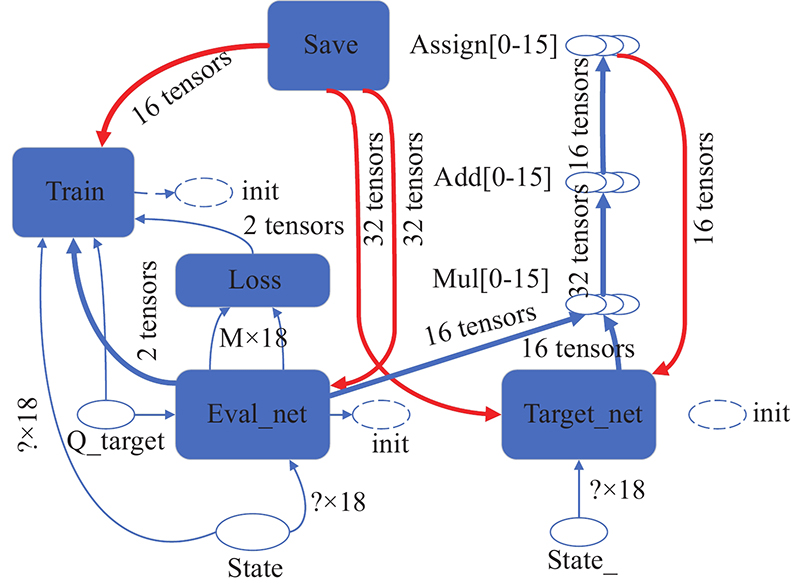
Fig 8
Information structure of UAV state space"
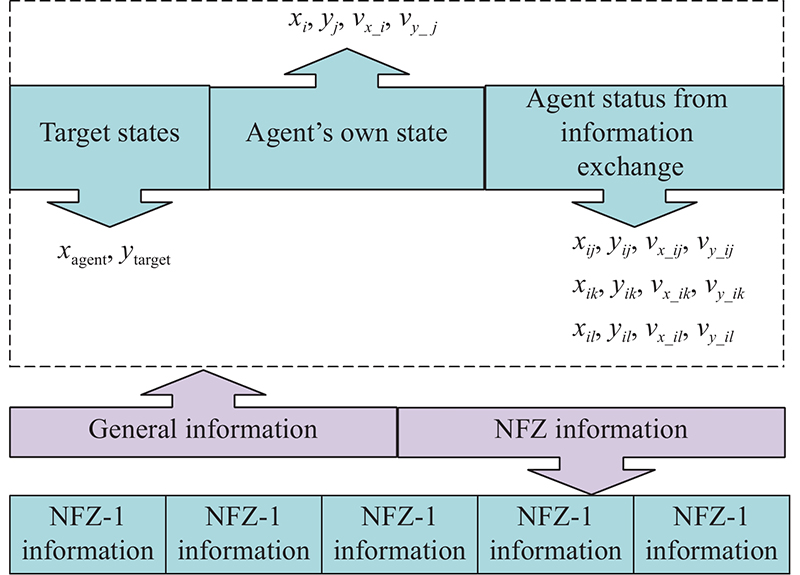

Fig 9
Network structure in DDQN"
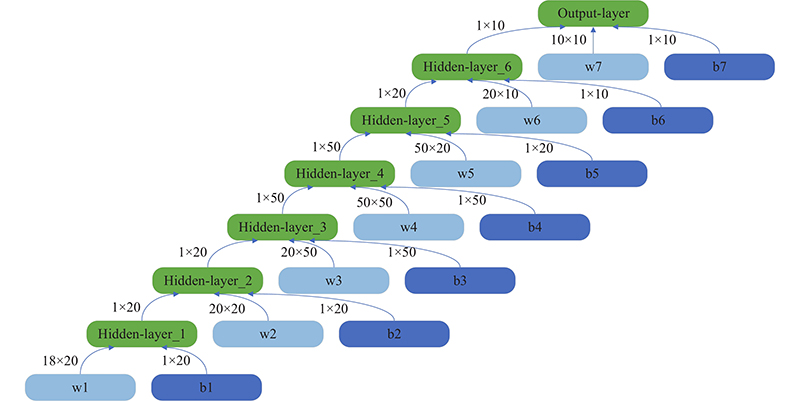
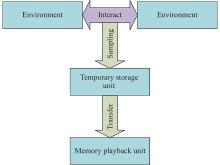
Fig 10
Structure of memory playback unit in DDQN"
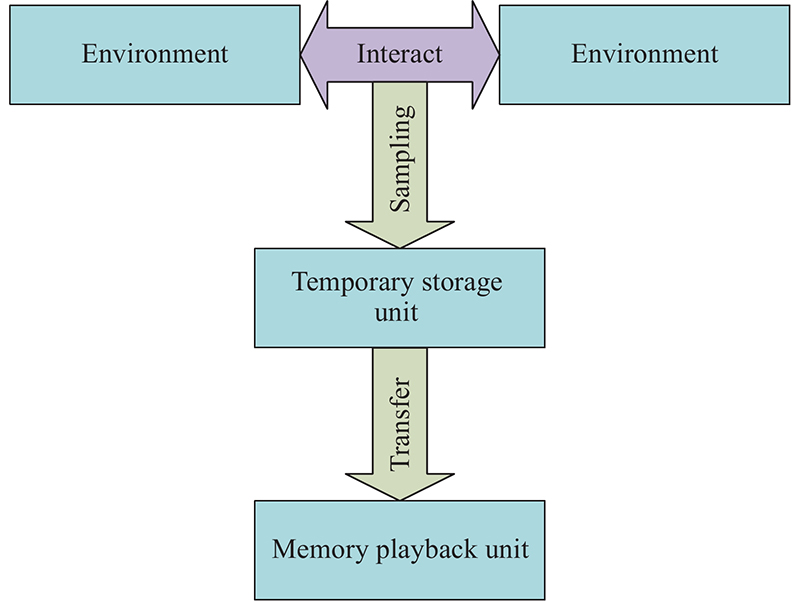

Fig 11
Rectangular NFZ"
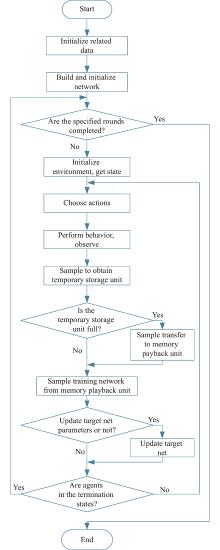
Fig 12
Flowchart of DDQN algorithm"
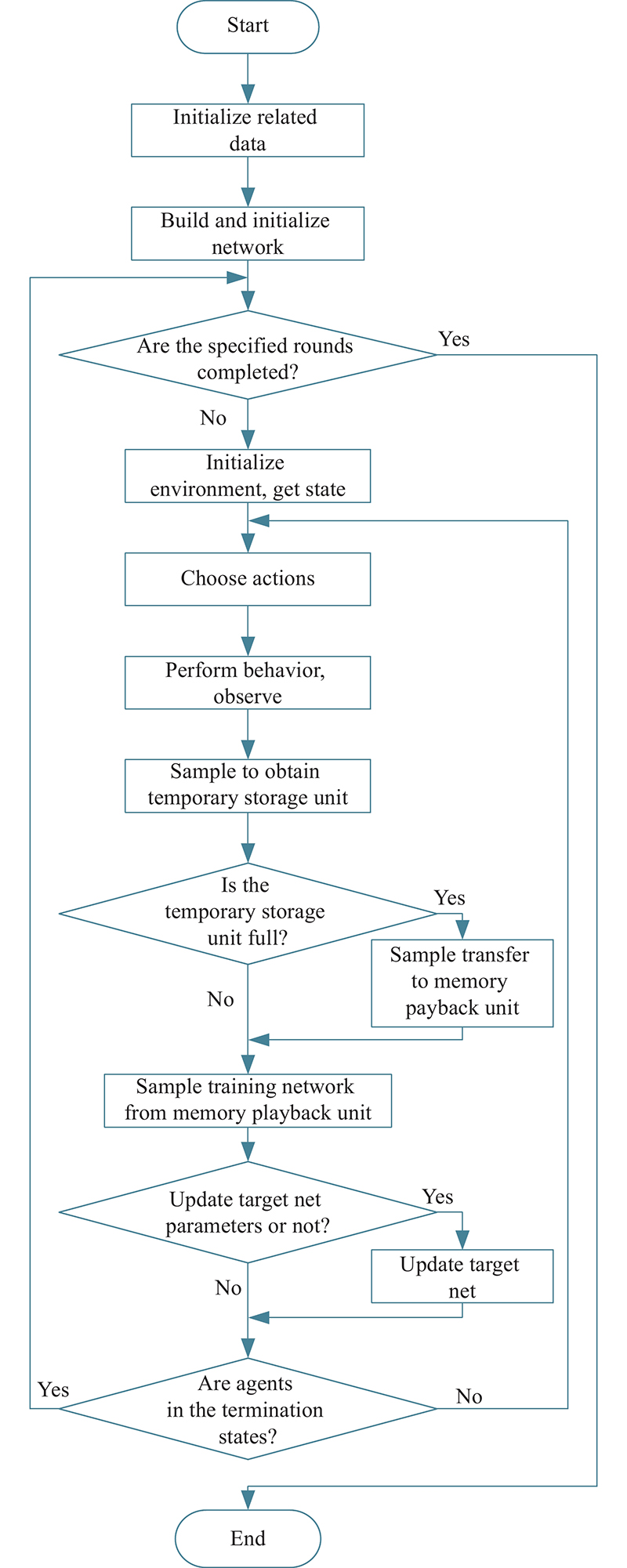
Fig 13
Mean changes of network parameters in “Eval network”"
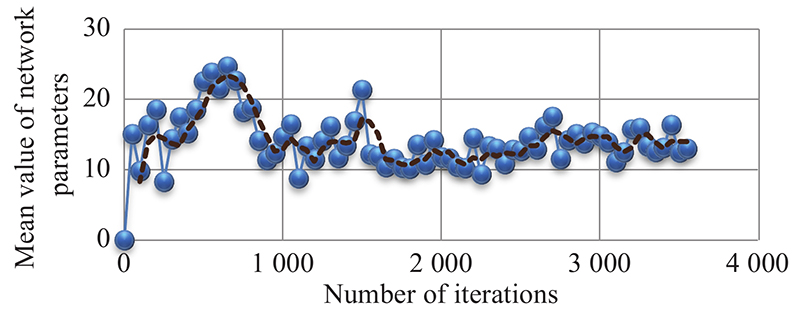
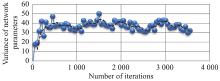
Fig 14
Variance changes of network parameters in “Eval network”"
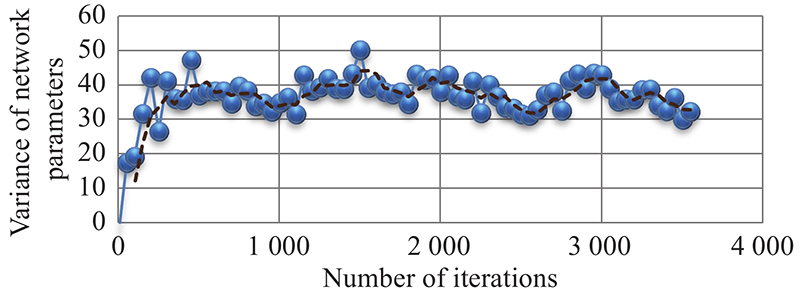
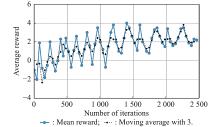
Fig 15
Mean reward value of training samples in different training rounds"
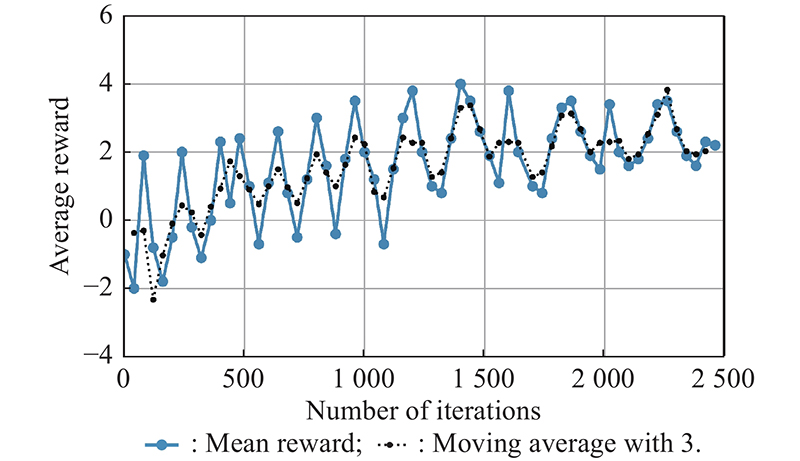
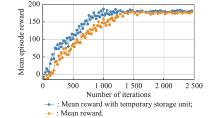
Fig 16
Mean episode reward under different training rounds"
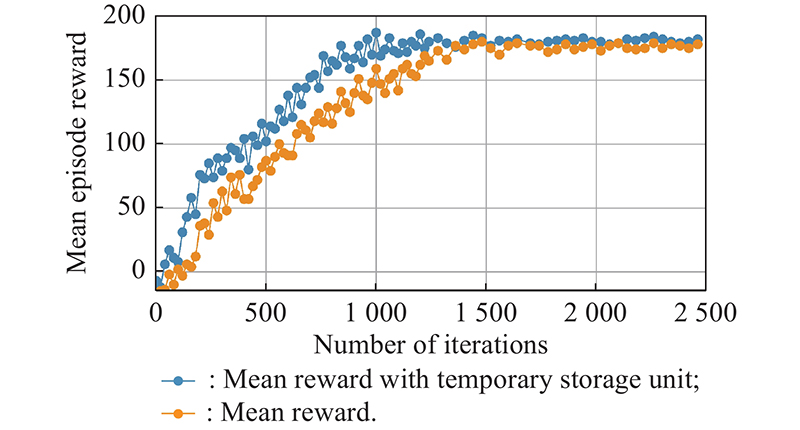
Fig 17
Task completion rate for UAV swarm without NFZ"
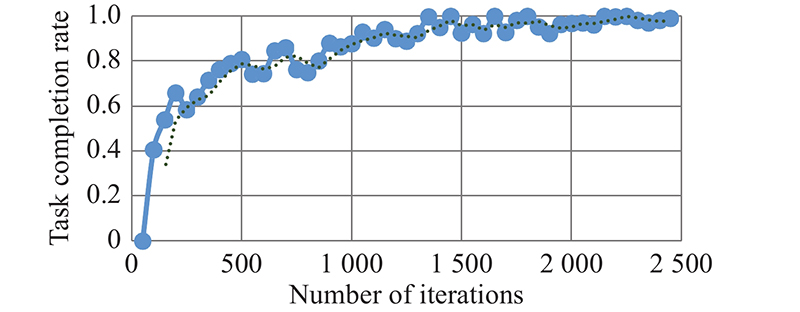
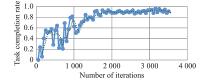
Fig 18
Task completion rate for UAV swarm with NFZ"
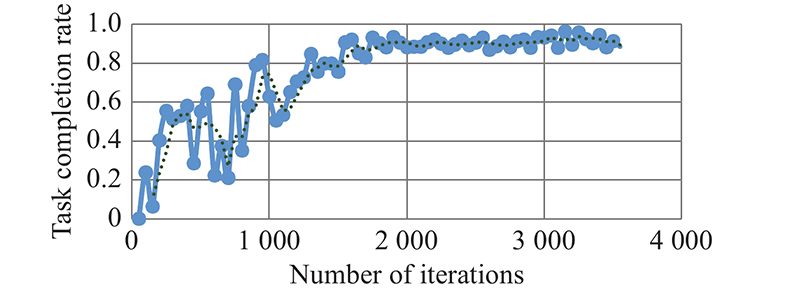
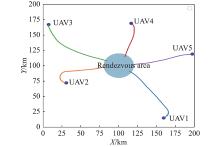
Fig 19
Trajectory of five UAVs on rendezvous task without NFZ"
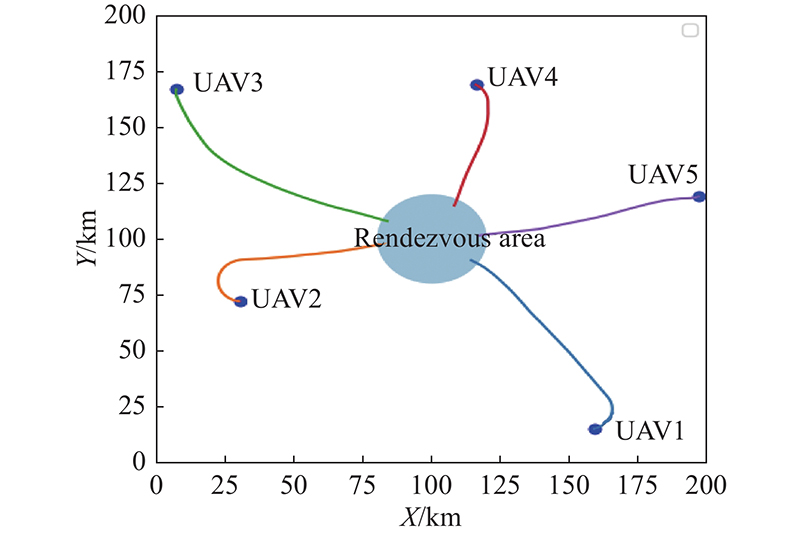
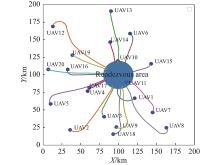
Fig 20
Trajectory of 20 UAVs on rendezvous task without NFZ"
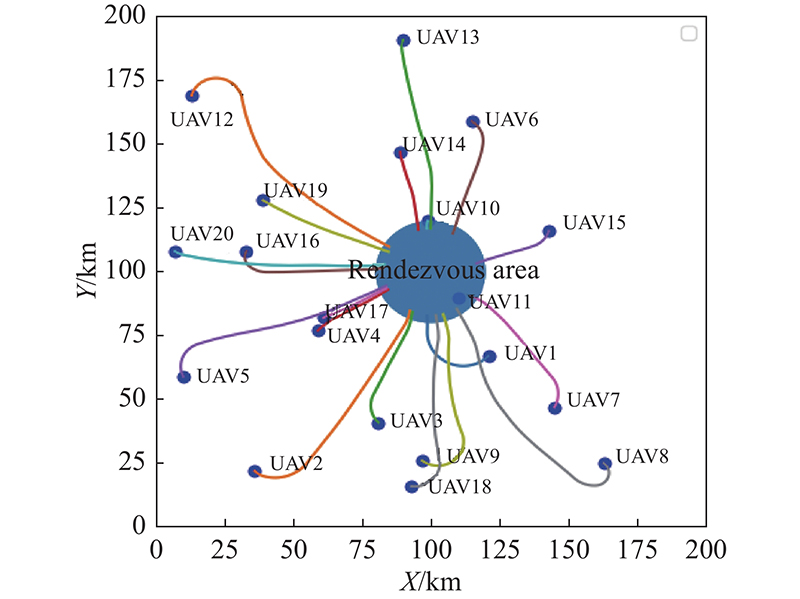
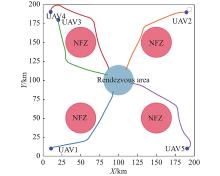
Fig 21
Trajectory of five UAVs on rendezvous task with circular NFZs"
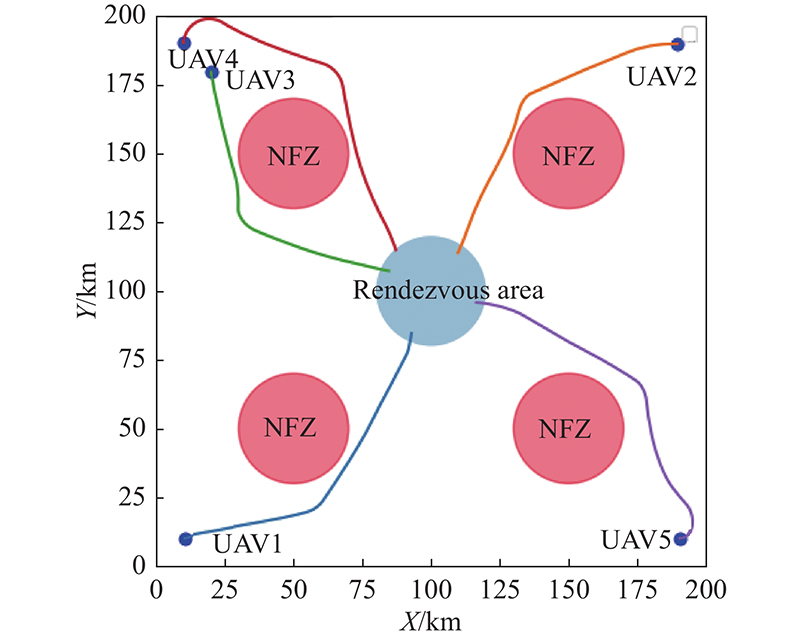
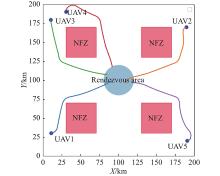
Fig 22
Trajectory of five UAVs on rendezvous task with rectangular NFZs"
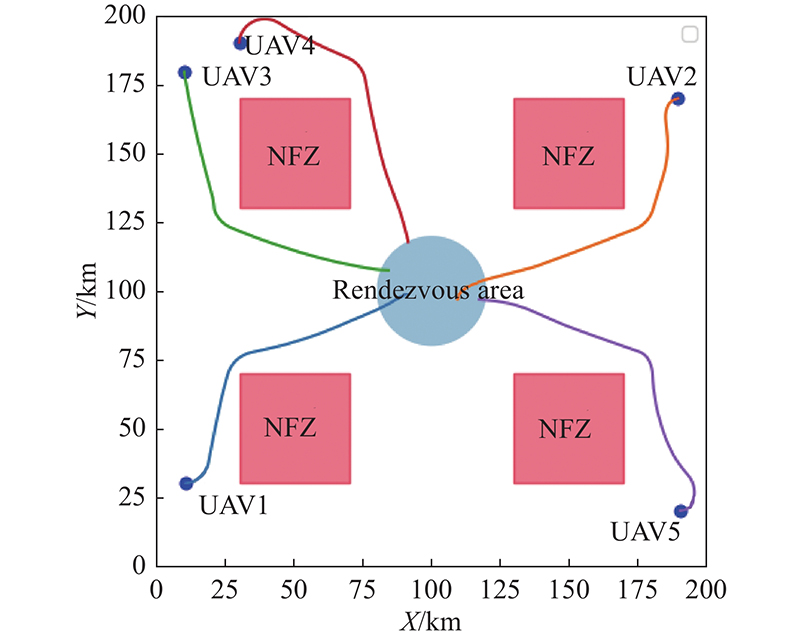
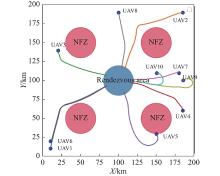
Fig 23
Trajectory of 10 UAVs on rendezvous task with circular NFZs"
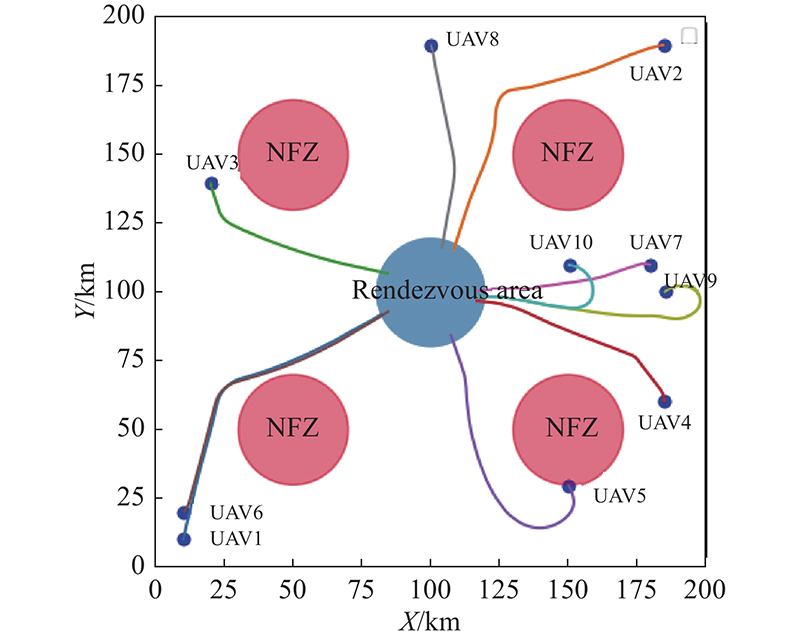
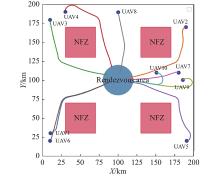
Fig 24
Trajectory of 10 UAVs on rendezvous task with rectangular NFZs"
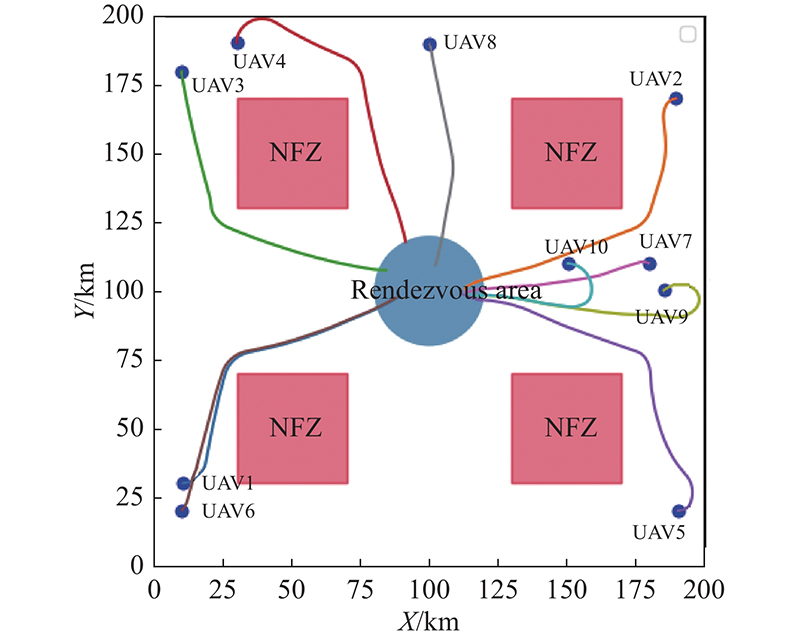
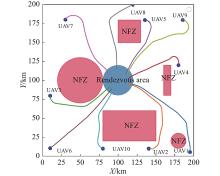
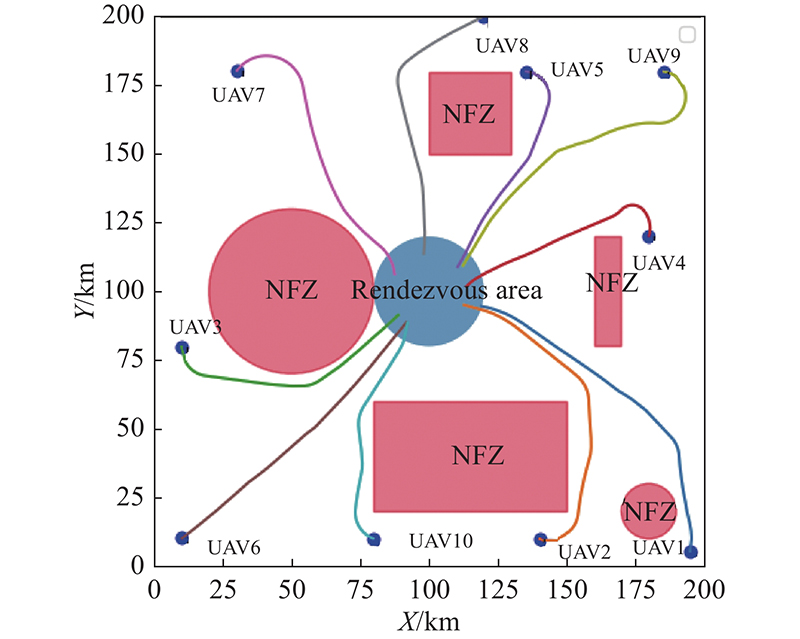
Fig 25
Trajectory of 10 UAVs on rendezvous task with rectangular and circular NFZs"
| 12 | SOUZA LEITE C F. A deep reinforcement learning algorithm for swarm robotics. Warsaw, Poland: Institute of Aeronautics and Applied Mechanics, 2018. |
| 13 | HUTTENRAUCH M, SOSIC A, NEUMANN G. Guided deep reinforcement learning for swarm systems. https://doi.org/10.48550/arXiv.1709.06011. |
| 14 | KERSANDT K. Deep reinforcement learning as control method for autonomous UAVs. Barcelona: Polytechnic University of Catalonia, 2018. |
| 15 | XUE X D, LI Z, ZHANG D S, et al A deep reinforcement learning method for mobile robot collision avoidance based on double DQN. Proc. of the IEEE 28th International Symposium on Industrial Electronics, 2019, 2131- 2136. |
| 16 | AN W, PARK C, HAN X, et al Hidden Markov model and auction-based formulations of sensor coordination mechanisms in dynamic task environments. IEEE Trans. on Systems, Man & Cybernetics: Part A, 2011, 41 (6): 1092- 1106. |
| 17 | TSITSIKLIS J N Asynchronous stochastic approximation and Q-learning. Machine Learning, 1994, 16 (3): 185- 202. |
| 18 | VINCENT F, RAPHAEL F, DAMIEN E. Playing Atari with deep reinforcement learning. https://doi.org/10.48550/arXiv.1312.5602. |
| 19 |
HIKARU S, TADASHI H, SATORU K Experimental study on behavior acquisition of mobile robot by deep Q-network. Journal of Advanced Computational Intelligence and Intelligent Informatics, 2017, 21 (5): 840- 848.
doi: 10.20965/jaciii.2017.p0840 |
| 1 | SKJERVOLD E, HOELSRETER O T Autonomous, cooperative UAV operations using COTS consumer drones and custom ground control station. Proc. of the IEEE Military Communications Conference, 2019, 486- 492. |
| 2 | BARTON S L, WAYTOWICH N R, ZAROUKIAN E, et al Measuring collaborative emergent behavior in multi-agent reinforcement learning. Advances in Intelligent Systems and Computing, 2019, 876, 422- 427. |
| 3 | PHAM H, LA H, FEIL-SEIFER D, et al. Autonomous UAV navigation using reinforcement learning. https://doi.org/10.48550/arXiv.1801.05086. |
| 4 | PHAM H, FEIL-SEIFER D, FEIL-SEIFER D, et al. Cooperative and distributed reinforcement learning of drones for field coverage. https://doi.org/10.48550/arXiv.1803.07250. |
| 5 | PRICE J K, PINON-FISCHER O J, MAVRIS D N. Definition of optimal agent behaviors using reinforcement learning. Proc. of the AIAA SciTech Forum, 2019. DOI: 10.2514/6.2019-2200. |
| 6 | QI S Y, ZHU S C Intent-aware multi-agent reinforcement learning. Proc. of the IEEE International Conference on Robotics and Automation, 2018, 7533- 7540. |
| 7 | ZHANG W X, MA L, LI X N Multi-agent reinforcement learning based on local communication. Cluster Computing, 2019, 22 (6): 1- 10. |
| 8 | LIU Y X, HU L, TIAN Y L, et al Reinforcement learning based two-level control framework of UAV swarm for cooperative persistent surveillance in an unknown urban area. Aerospace Science and Technology, 2019, 98, 105671. |
| 9 | LUO D, YANG X U, ZHANG J New progresses on UAV swarm confrontation. Science & Technology Review, 2017, 35 (7): 26- 31. |
| 10 | OZSOYELLER D, TOKEKAR P Multi-robot symmetric rendezvous search on the line. IEEE Robotics and Automation Letters, 2021, 7 (1): 334- 341. |
| 11 | LI Q Y, DU X T, HUANG Y Z, et al. Learning of coordination policies for robotic swarms. https://doi.org/10.48550/arXiv.1709.06620. |
| [1] | Jie LI, Xiaoyu DANG, Sai LI. DQN-based decentralized multi-agent JSAP resource allocation for UAV swarm communication [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 289-298. |
| [2] | Hao LI, Hemin SUN, Ronghua ZHOU, Huainian ZHANG. Hybrid TDOA/FDOA and track optimization of UAV swarm based on A-optimality [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 149-159. |
| [3] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [4] | Yangyang JIANG, Yan GAO, Wenqi SONG, Yue LI, Quan QUAN. Bibliometric analysis of UAV swarms [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 406-425. |
| [5] | Jinqiang HU, Husheng WU, Renjun ZHAN, Rafik MENASSEL, Xuanwu ZHOU. Self-organized search-attack mission planning for UAV swarm based on wolf pack hunting behavior [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1463-1476. |
| [6] | Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||