
Journal of Systems Engineering and Electronics ›› 2021, Vol. 32 ›› Issue (6): 1421-1438.doi: 10.23919/JSEE.2021.000121
• SYSTEMS ENGINEERING • Previous Articles Next Articles
Jiandong ZHANG1( ), Qiming YANG1,*(), Guoqing SHI1(), Yi LU2(), Yong WU1()
), Qiming YANG1,*(), Guoqing SHI1(), Yi LU2(), Yong WU1()
Received:2020-12-22
Online:2022-01-05
Published:2022-01-05
Contact:
Qiming YANG
E-mail:jdzhang@nwpu.edu.cn;yangqm@nwpu.edu.cn;shiguoqing@nwpu.edu.cn;yiluemail@126.com;yongwu@nwpu.edu.cn
About author:Supported by:Jiandong ZHANG, Qiming YANG, Guoqing SHI, Yi LU, Yong WU. UAV cooperative air combat maneuver decision based on multi-agent reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1421-1438.
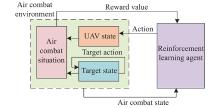
Fig 1
UAV short-range air combat maneuver decision model framework based on reinforcement learning[17] "
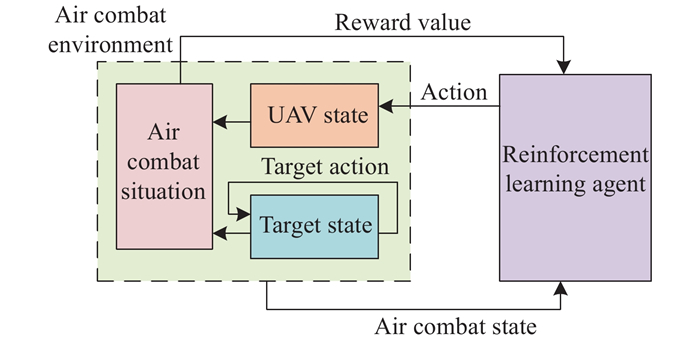
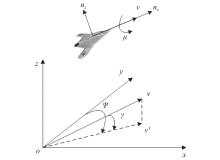
Fig 2
Aircraft three-degree-of-freedom particle model"
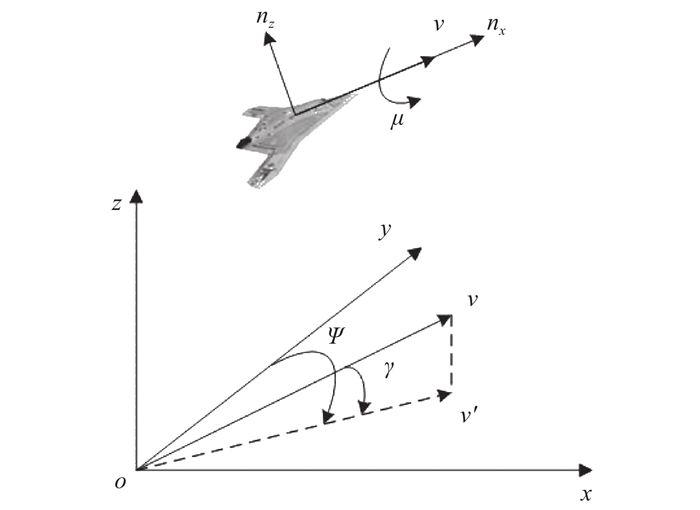
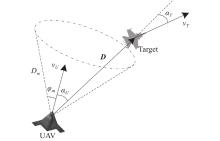
Fig 3
One-to-one short-range air combat situation"
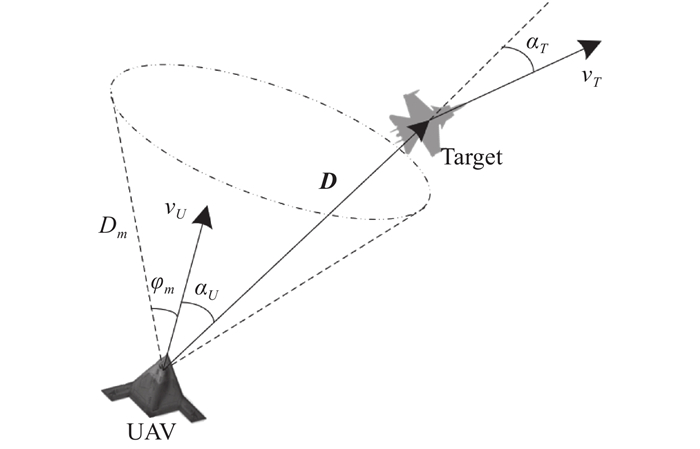
Fig 4
Multi-UAV air combat state variables"
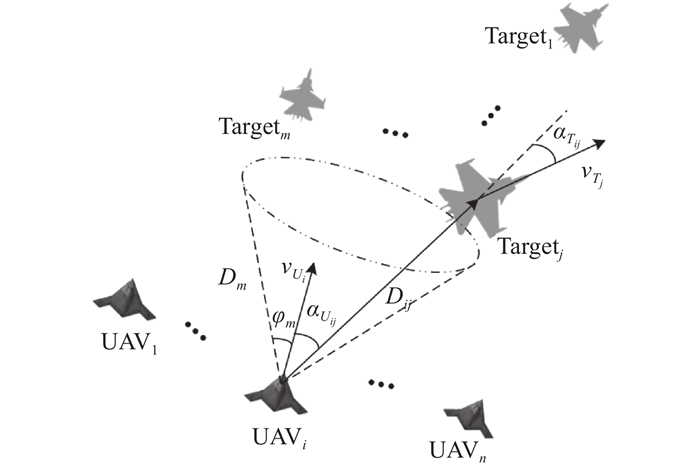
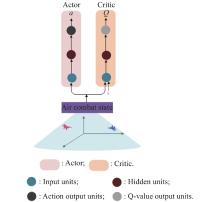
Fig 5
Actor-Critic model framework for single UAV air combat maneuver decision"
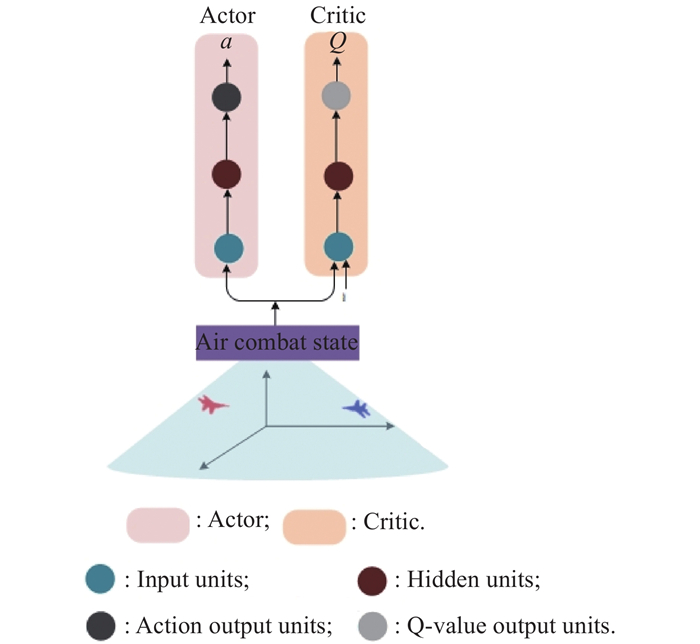
Fig 6
Model structure of BRNN-based multi-UAV air combat maneuver decision"
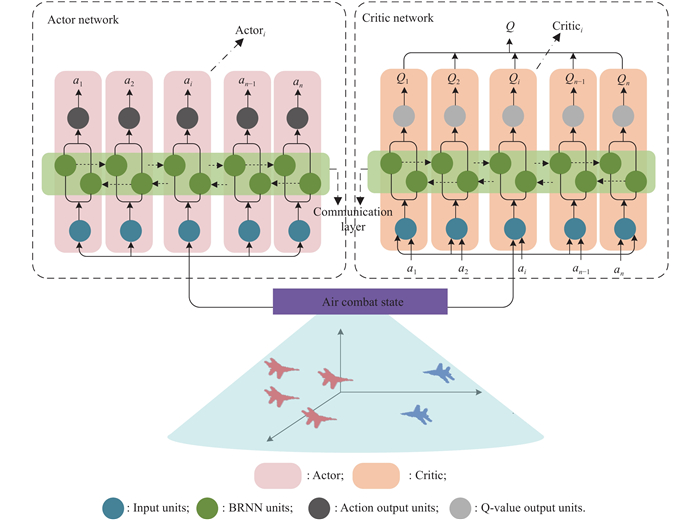
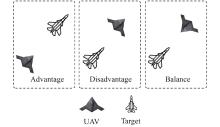
Fig 7
Advantage, balance, and disadvantage situation of UAV"
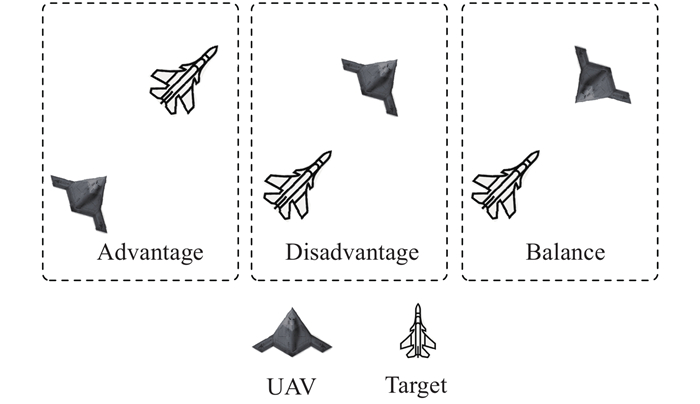
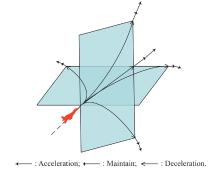
Fig 8
Maneuver library of target"
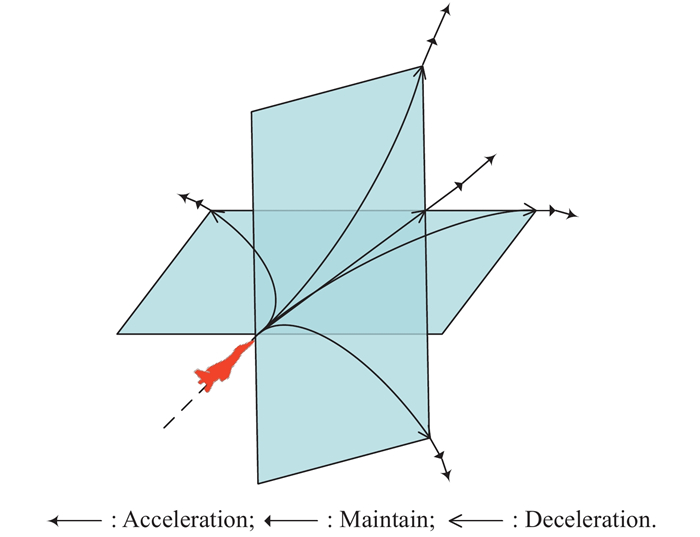
Table 1
Maneuver library of target"
| Number | Maneuver | Control value | ||
| | | | ||
| 1 | Forward maintain | 0 | 1 | 0 |
| 2 | Forward accelerate | 2 | 1 | 0 |
| 3 | Forward decelerate | ?1 | 0 | 0 |
| 4 | Left turn maintain | 0 | 8 | ?arc cos (1/8) |
| 5 | Left turn accelerate | 2 | 8 | ?arc cos (1/8) |
| 6 | Left turn decelerate | ?1 | 8 | ?arc cos (1/8) |
| 7 | Right turn maintain | 0 | 8 | arc cos (1/8) |
| 8 | Right turn accelerate | 2 | 8 | arc cos (1/8) |
| 9 | Right turn decelerate | ?1 | 8 | arc cos (1/8) |
| 10 | Upward maintain | 0 | 8 | 0 |
| 11 | Upward accelerate | 2 | 8 | 0 |
| 12 | Upward decelerate | ?1 | 8 | 0 |
| 13 | Downward maintain | 0 | 8 | |
| 14 | Downward accelerate | 2 | 8 | |
| 15 | Downward decelerate | ?1 | 8 | |
Table 2
Advantage initial state setting for 2v1 basic training"
| Initial state | x/m | y/m | z/m | v/(m/s) | | | |
| Training episode | UAV1 | [?200, 200] | [?300, 300] | 3000 | 200 | 0 | [?60, 60] |
| UAV2 | [2500, 3500] | [?500, 500] | 3500 | 200 | 0 | [?60, 60] | |
| Target | [2500, 3500] | [2500, 3500] | [2800, 3800] | [150, 300] | 0 | [?60, 60] | |
| Evaluation episode | UAV1 | 0 | 0 | 3000 | 200 | 0 | 40 |
| UAV2 | 3000 | 0 | 3500 | 200 | 0 | 40 | |
| Target | 3000 | 3000 | 3000 | 220 | 0 | 45 | |
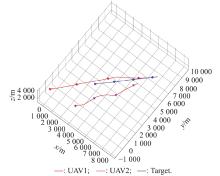
Fig 9
2v1 maneuver trajectory after basic training of advantage initial state"
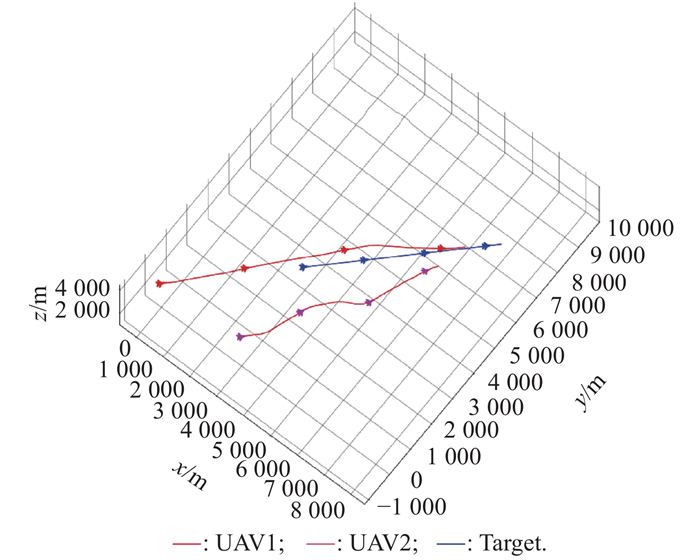
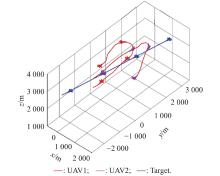
Fig 10
2v1 maneuver trajectory after basic training of balance initial state"
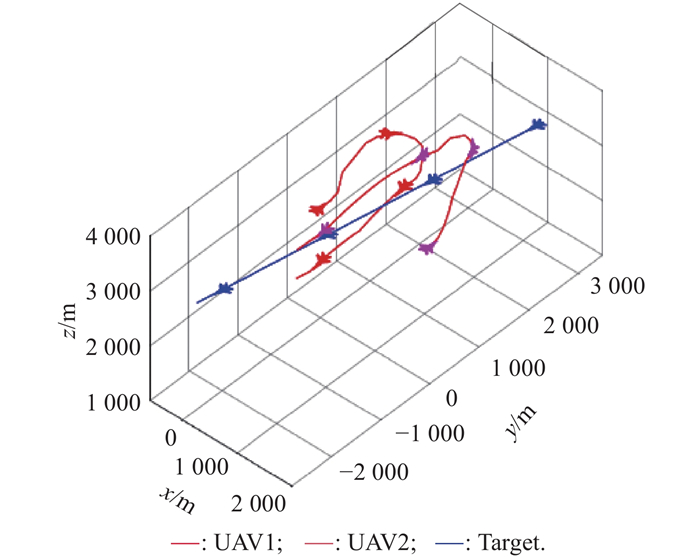
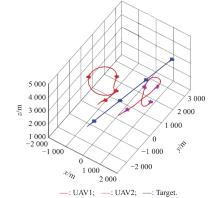
Fig 11
2v1 maneuver trajectory after basic training of disadvantage initial state"
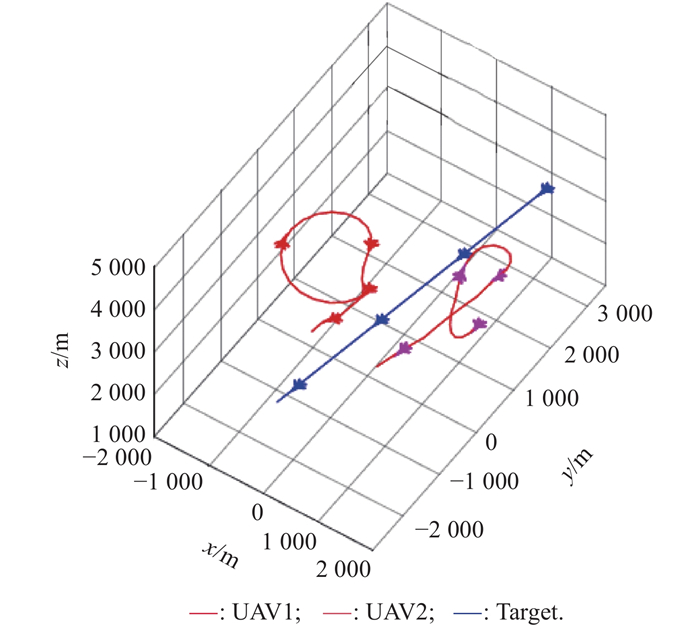
Table 3
Balance initial state setting for 2v1 confrontation training"
| Initial state | x/m | y/m | z/m | v/(m/s) | | | |
| Training episode | UAV1 | [?200, 200] | [?300, 300] | 3000 | 200 | 0 | [?60, 60] |
| UAV2 | [1500, 2500] | [?500, 500] | 3500 | 200 | 0 | [?60, 60] | |
| Target | [1000, 2 000] | [2500, 3500] | [2800, 3800] | [150, 300] | 0 | [120, 240] | |
| Evaluation episode | UAV1 | 0 | 0 | 3000 | 200 | 0 | 0 |
| UAV2 | 2 000 | 0 | 3500 | 200 | 0 | 0 | |
| Target | 1000 | 3000 | 3000 | 220 | 0 | 200 | |
Fig 12
2v1 maneuver trajectory after confrontation training of balance initial state"
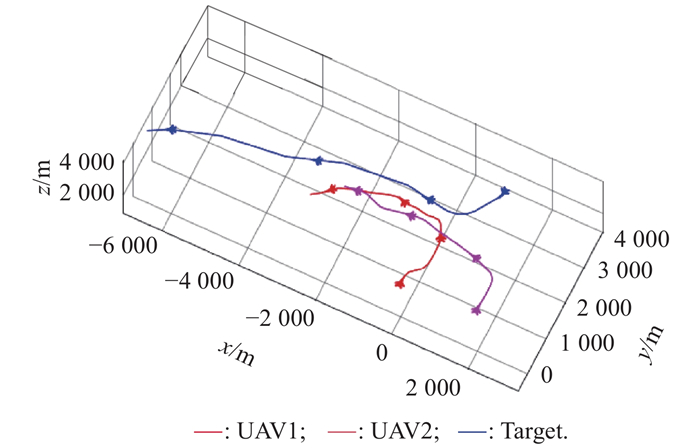
Table 4
Balance initial state setting for 2v2 basic training"
| Initial State | x/m | y/m | z/m | v/(m/s) | | | |
| Training episode | UAV1 | [?200, 200] | [?300, 300] | 3000 | 200 | 0 | [10, 70] |
| UAV2 | [2800, 3200] | [?300, 300] | 3200 | 200 | 0 | [10, 70] | |
| Target1 | [2500, 3500] | [2500, 3500] | [2900, 3100] | [180, 220] | 0 | [?165, ?105] | |
| Target2 | [5500, 6500] | [2500, 3500] | [2900, 3100] | [180, 220] | 0 | [?165, ?105] | |
| Evaluation episode | UAV1 | 0 | 0 | 3000 | 200 | 0 | 40 |
| UAV2 | 3000 | 0 | 3200 | 200 | 0 | 40 | |
| Target1 | 3000 | 3000 | 3000 | 200 | 0 | ?135 | |
| Target2 | 6000 | 3000 | 3000 | 200 | 0 | ?135 | |
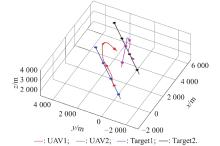
Fig 13
2v2 maneuver trajectory after basic training of balance initial state"
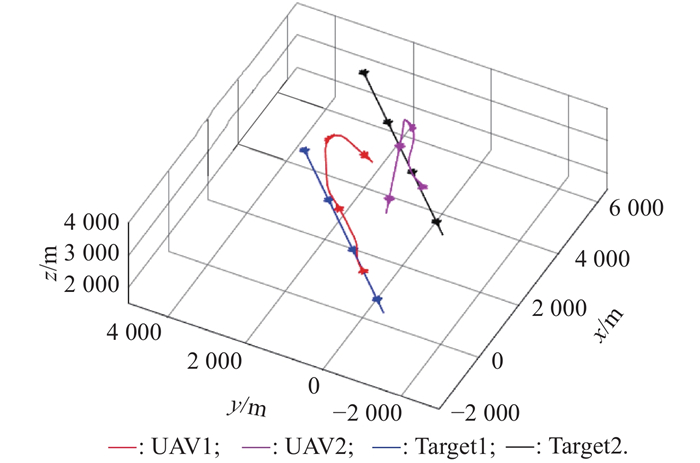
Table 5
Balance initial state setting for 2v2 confrontation training"
| Initial state | x/m | y/m | z/m | v/(m/s) | | | |
| Training episode | UAV1 | [?200, 200] | [?200, 200] | 3000 | 200 | 0 | [20, 60] |
| UAV2 | [2800, 3200] | [?200, 200] | 3200 | 200 | 0 | [20, 60] | |
| Target1 | [2500, 3500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?155, ?115] | |
| Target2 | [5500, 6500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?125, ?115] | |
| Evaluation episode | UAV1 | 0 | 0 | 3000 | 200 | 0 | 40 |
| UAV2 | 3000 | 0 | 3200 | 200 | 0 | 40 | |
| Target1 | 3000 | 3000 | 3000 | 200 | 0 | ?135 | |
| Target2 | 6000 | 3000 | 3000 | 200 | 0 | ?135 | |
Fig 14
2v2 maneuver trajectory after confrontation training of balance initial state"
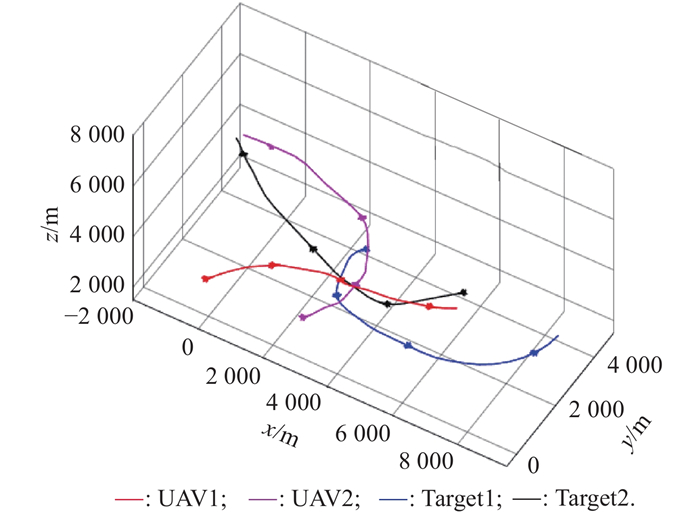
Table 6
Balance initial state setting for target assignment performance testing"
| Initial state | x/m | y/m | z/m | v/(m/s) | | | |
| Training episode | UAV1 | [?200, 200] | [?200, 200] | 3000 | 200 | 0 | [20, 60] |
| UAV2 | [2800, 3200] | [?200, 200] | 3200 | 200 | 0 | [20, 60] | |
| Target1 | [2500, 3500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?155, ?115] | |
| Target2 | [5500, 6500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?125, ?115] | |
| Evaluation episode | UAV1 | [?100, 100] | [?100, 100] | 3000 | 200 | 0 | [35, 45] |
| UAV2 | [2900, 3100] | [?100, 100] | 3200 | 200 | 0 | [35, 45] | |
| Target1 | [2500, 3500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?155, ?115] | |
| Target2 | [5500, 6500] | [2800, 3200] | [2900, 3100] | [180, 220] | 0 | [?125, ?115] | |
Table 7
Conditions of air combat result"
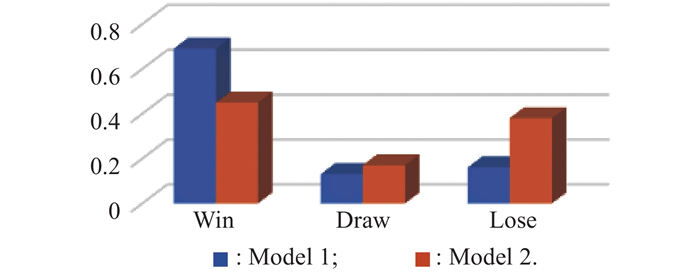
| Result | Condition |
| Win | All targets are shot down |
| Draw | Number of remaining targets and drones are equal |
| Lose | All UAVs are shot down |
Fig 15
Result of the confrontation test"
| 1 |
ZHOU K, WEI R, XU Z, et al An air combat decision learning system based on a brain-like cognitive mechanism. Cognitive Computation, 2020, 12 (1): 128- 139.
doi: 10.1007/s12559-019-09683-7 |
| 2 |
YANG Q M, ZHANG J D, SHI G Q Modeling of UAV path planning based on IMM under POMDP framework. Journal of Systems Engineering and Electronics, 2019, 30 (3): 545- 554.
doi: 10.21629/JSEE.2019.03.12 |
| 3 |
MCGREW J S, HOW J P, WILLIAMS B, et al Air-combat strategy using approximate dynamic programming. Journal of Guidance, Control, and Dynamics, 2010, 33 (5): 1641- 1654.
doi: 10.2514/1.46815 |
| 4 | ZHOU K, WEI R X, XU Z F, et al A brain like air combat learning system inspired by human learning mechanism. Proc. of IEEE/CSAA Guidance, Navigation and Control Conference, 2018, 286- 293. |
| 5 | XU G, WEI S, ZHANG H Application of situation function in air combat differential games. Proc. of the 36th Chinese Control Conference, 2017, 5865- 5870. |
| 6 | PARK H, LEE B Y, TAHK M J, et al Differential game based air combat maneuver generation using scoring function matrix. International Journal of Aeronautical & Space Sciences, 2015, 17 (2): 204- 213. |
| 7 | SMITH R E, DIKE B A, MEHRA R K, et al Classifier systems in combat: two-sided learning of maneuvers for advanced fighter aircraft. Computer Methods in Applied Mechanics & Engineering, 2000, 186 (2): 421- 437. |
| 8 |
HANG C Q, DONG K S, HUANG H Q, et al Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization. Journal of Systems Engineering and Electronics, 2018, 29 (1): 86- 97.
doi: 10.21629/JSEE.2018.01.09 |
| 9 | GUO H F, HOU M Y, ZHANG Q J, et al UCAV robust maneuver decision based on statistics principle. Acta Armamentarii, 2017, 38 (1): 160- 167. |
| 10 | FU L, XIE H An UAV air-combat decision expert system based on receding horizon control. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41 (11): 1994- 1999. |
| 11 | ROGER W S, ALAN E B. Neural network models of air combat maneuvering. Las Cruces, U.S.: New Mexico State University, 1992. |
| 12 | DING L J, YANG Q M Research on air combat maneuver decision of UAVs based on reinforcement learning. Avionics Technology, 2018, 49 (2): 29- 35. |
| 13 | LIU P, MA Y A deep reinforcement learning based intelligent decision method for UCAV air combat. Proc. of Asian Simulation Conference, 2017, 274- 286. |
| 14 | ZUO J L, YANG R N, ZHANG Y, et al Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning. Acta Aeronautica et Astronautica Sinica, 2017, 38 (10): 217- 230. |
| 15 |
ZHANG X B, LIU G Q, YANG C J, et al Research on air confrontation maneuver decision-making method based on reinforcement learning. Electronics, 2018, 7 (11): 279.
doi: 10.3390/electronics7110279 |
| 16 | YANG Q M, ZHU Y, ZHANG J D, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm. Proc. of the IEEE 15th International Conference on Control and Automation, 2019: 37−42. |
| 17 |
YANG Q M, ZHANG J D, SHI G Q, et al Maneuver decision of UAV in short-range air combat based on deep reinforcement learning. IEEE Access, 2020, 8, 363- 378.
doi: 10.1109/ACCESS.2019.2961426 |
| 18 |
WAN K F, GAO X G Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning. Remote Sensing, 2020, 12, 640.
doi: 10.3390/rs12040640 |
| 19 | ROBERT L S. Fighter combat—tactics and maneuvering. Maryland: Naval Institute Press, 1985. |
| 20 | XI Z F, XU A, KOU Y X, et al Decision process of multi-aircraft cooperative air combat maneuver. Systems Engineering and Electronics, 2020, 42 (2): 381- 389. |
| 21 | LI J X, TONG M A, JIN D K Bargaining differential game theory and application to multiple-airplane combat analysis. Systems Engineering-Theory & Practice, 1997, 6 (6): 68- 72. |
| 22 | WANG Y N, JIANG Y X An intelligent differential game on air combat decision. Flight Dynamics, 2003, 21 (1): 66- 70. |
| 23 | ZUO J L, ZHANG Y, YANG R N, et al Reconstruction and evaluation of medium-rang cooperation air combat decision-making process with two phase clustering. Systems Engineering and Electronics, 2020, 42 (1): 108- 117. |
| 24 | XIE R Z, LI J Y, LUO D L Research on maneuvering decisions for multi-UAVs Air combat. Proc. of the 11th IEEE International Conference on Control & Automation, 2014, 767- 772. |
| 25 | LUO D L, SHEN C L, WANG B, et al Air combat decision-making for cooperative multiple target attack using heuristic adaptive genetic algorithm. Proc. of the International Conference on Machine Learning and Cybernetics, 2005, 473- 478. |
| 26 |
SU M C, LAI S C, LIN S C, et al A new approach to multi-aircraft air combat assignments. Swarm and Evolutionary Computation, 2012, 6, 39- 46.
doi: 10.1016/j.swevo.2012.03.003 |
| 27 | WANG Y, ZHANG W, LI Y An efficient clonal selection algorithm to solve dynamic weapon-target assignment game model in UAV cooperative aerial combat. Proc. of the 35th Chinese Control Conference, 2016, 9578- 9581. |
| 28 |
TAL S, STEVE R, DAVE G Assigning micro UAVs to task tours in an urban terrain. IEEE Trans. on Control Systems Technology, 2007, 15 (4): 601- 612.
doi: 10.1109/TCST.2007.899154 |
| 29 | . PENG P, WEN Y, YANG Y, et al. Multiagent bidirectionally-coordinated nets: emergence of human-level coordination in learning to play star craft combat games. arXiv preprint arXiv: 1703.10069v4, 2017. |
| 30 | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms. Proc. of the 31st International Conference on Machine Learning, 2014, 605- 619. |
| 31 | SUTTON R, MCALLESTER D, SINGH S, et al Policy gradient methods for reinforcement learning with function approximation. Proc. of the 13th Annual Neural Information Processing Systems Conference, 1999, 1057- 1063. |
| [1] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [2] | Xiaofeng LI, Lu DONG, Changyin SUN. Hybrid Q-learning for data-based optimal control of non-linear switching system [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1186-1194. |
| [3] | Ang GAO, Qisheng GUO, Zhiming DONG, Zaijiang TANG, Ziwei ZHANG, Qiqi FENG. Research on virtual entity decision model for LVC tactical confrontation of army units [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1249-1267. |
| [4] | Shouyi LI, Mou CHEN, Qingxian WU, Yuhui WANG. Threat sequencing of multiple UCAVs with incomplete information based on game theory [J]. Journal of Systems Engineering and Electronics, 2022, 33(4): 986-996. |
| [5] | Jingyu CAO, Lu DONG, Changyin SUN. Day-ahead scheduling based on reinforcement learning with hybrid action space [J]. Journal of Systems Engineering and Electronics, 2022, 33(3): 693-705. |
| [6] | Xiangyang LIN, Qinghua XING, Fuxian LIU. Choice of discount rate in reinforcement learning with long-delay rewards [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 381-392. |
| [7] | Wenzhang LIU, Lu DONG, Jian LIU, Changyin SUN. Knowledge transfer in multi-agent reinforcement learning with incremental number of agents [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 447-460. |
| [8] | Wanping SONG, Zengqiang CHEN, Mingwei SUN, Qinglin SUN. Reinforcement learning based parameter optimization of active disturbance rejection control for autonomous underwater vehicle [J]. Journal of Systems Engineering and Electronics, 2022, 33(1): 170-179. |
| [9] | Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508. |
| [10] | Xin ZENG, Yanwei ZHU, Leping YANG, Chengming ZHANG. A guidance method for coplanar orbital interception based on reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2021, 32(4): 927-938. |
| [11] | Ye MA, Tianqing CHANG, Wenhui FAN. A single-task and multi-decision evolutionary game model based on multi-agent reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2021, 32(3): 642-657. |
| [12] | Caihua WU, Jianchao MA, Xiuwei ZHANG, Dang XIE. User space transformation in deep learning based recommendation [J]. Journal of Systems Engineering and Electronics, 2020, 31(4): 674-684. |
| [13] | Yong LIU, Jiao LI, Renshi ZHANG. Decision-making approach by employing grey incidence analysis and group negotiation [J]. Journal of Systems Engineering and Electronics, 2019, 30(4): 760-769. |
| [14] | Zhenzhen MA, Kumaraswamy PONNAMBALAM, Jianjun ZHU, Shitao ZHANG. Dynamic hesitant fuzzy linguistic group decision-making from a reliability perspective [J]. Journal of Systems Engineering and Electronics, 2018, 29(5): 1009-1021. |
| [15] | Ximeng XU, Rennong YANG, Ying FU. Situation assessment for air combat based on novel semi-supervised naive Bayes [J]. Journal of Systems Engineering and Electronics, 2018, 29(4): 768-779. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||