
Journal of Systems Engineering and Electronics ›› 2024, Vol. 35 ›› Issue (6): 1516-1529.doi: 10.23919/JSEE.2024.000062
• SYSTEMS ENGINEERING • Previous Articles
Nanxun DUO1,*( ), Qinzhao WANG1(), Qiang LYU2(), Wei WANG3()
), Qinzhao WANG1(), Qiang LYU2(), Wei WANG3()
Received:2022-12-29
Online:2024-12-18
Published:2025-01-14
Contact:
Nanxun DUO
E-mail:nanxunduo@outlook.com;13641331602@163.com;rokyou@live.cn;wangwei5zjs@163.com
About author:Nanxun DUO, Qinzhao WANG, Qiang LYU, Wei WANG. Tactical reward shaping for large-scale combat by multi-agent reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1516-1529.
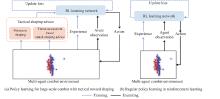
Fig 1
Illustration of policy learning with TRS"
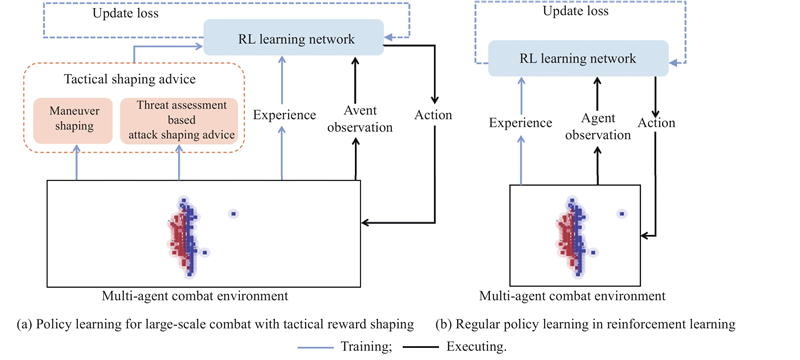

Fig 2
Illustration of maneuver shaping advice"
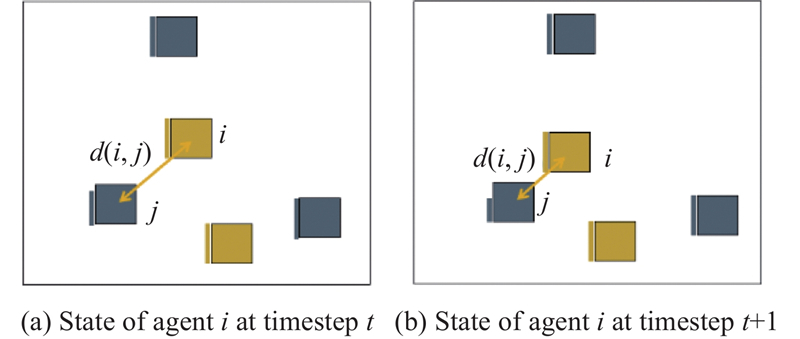

Fig 3
Illustration of self-focused threat assessment attack shaping advice"
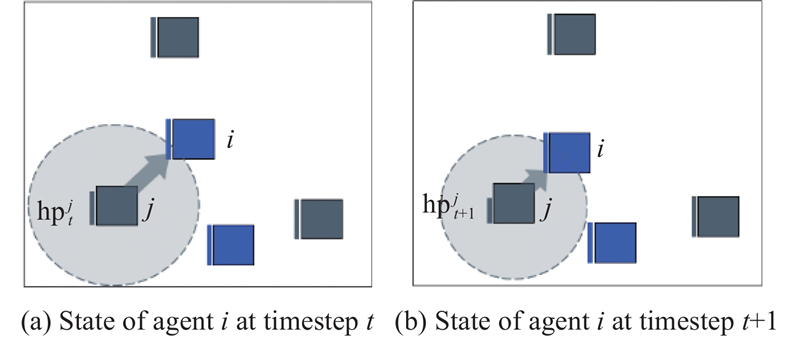
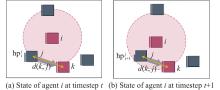
Fig 4
Illustration of ally-focused threat assessment attack shaping advice"
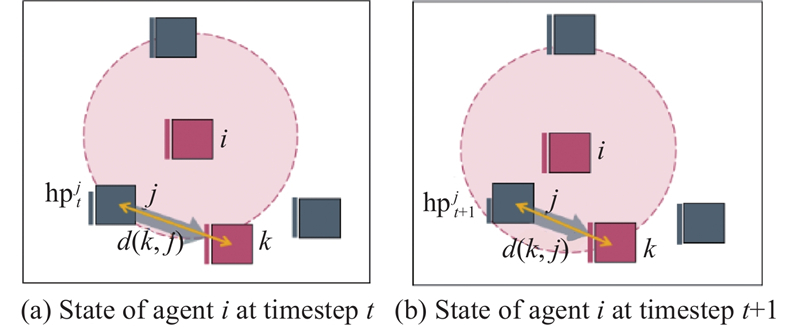
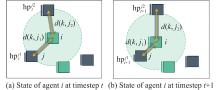
Fig 5
Illustration of enemy-focused threat assessment attack shaping advice"
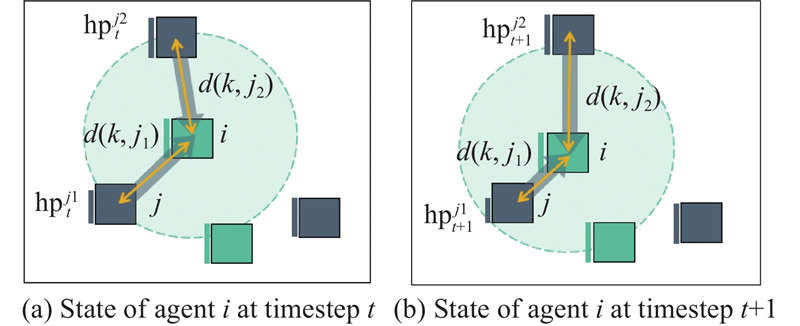

Fig 6
Regular battle scenario in MAgent"

Table 1
Test results of TRS"
| Algorithm | Win rate/% | Effective attack ratio/% | Episode length/ steps |
| Maneuver | 75 | 72 | 53 |
| Self | 81 | 82 | 43 |
| Self maneuver maneuver | 72 | 79 | 44 |
| Ally | 94 | 84 | 40 |
| Ally maneuver | 99 | 88 | 38 |
| Enemy | 92 | 78 | 41 |
| Enemy maneuver | 75 | 76 | 42 |
| Baseline | − | 68 | 53 |

Fig 7
Training results of TRS"
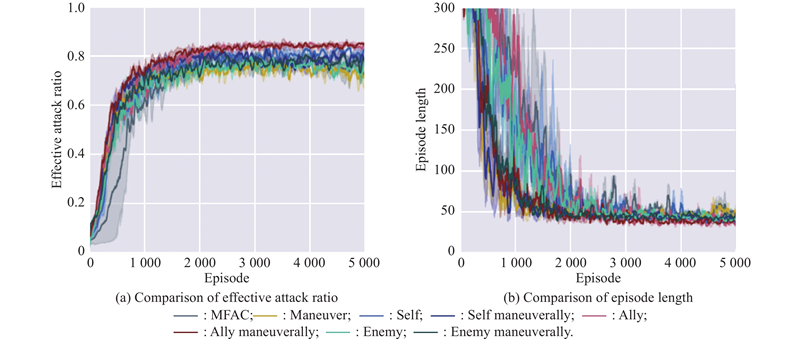
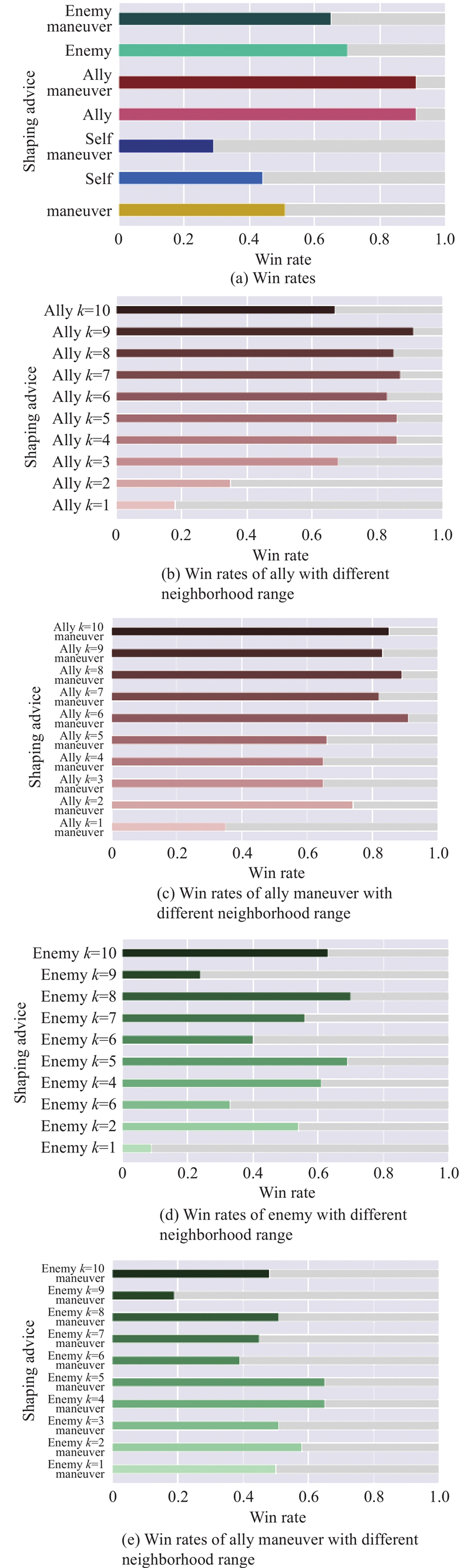
Table 2
Test results of ally with different neighborhood range %"
| Neighborhood range | Win rate | |
| Without maneuver | With maneuver | |
| 1 | 41 | 12 |
| 2 | 81 | 52 |
| 3 | 69 | 70 |
| 4 | 80 | 82 |
| 5 | 90 | 43 |
| 6 | 68 | 99 |
| 7 | 94 | 94 |
| 8 | 82 | 89 |
| 9 | 81 | 87 |
| 10 | 86 | 87 |
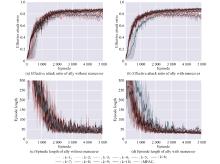
Fig 8
Training results of ally-focused threat assessment attack shaping advice with different neighborhood range"

Table 3
Test results of enemy with different neighborhood range in regular battle %"
| Neighborhood range | Win rate | |
| Without maneuver | With maneuver | |
| 1 | 39 | 50 |
| 2 | 53 | 54 |
| 3 | 84 | 46 |
| 4 | 83 | 63 |
| 5 | 53 | 65 |
| 6 | 87 | 52 |
| 7 | 65 | 51 |
| 8 | 76 | 75 |
| 9 | 57 | 67 |
| 10 | 73 | 55 |

Fig 9
Test results and training results of enemy-focused threat assessment attack shaping advice with different neighborhood range"


Fig 10
Comparison of chasing process of ally focused advice and ally maneuver advice with same neighborhood range"
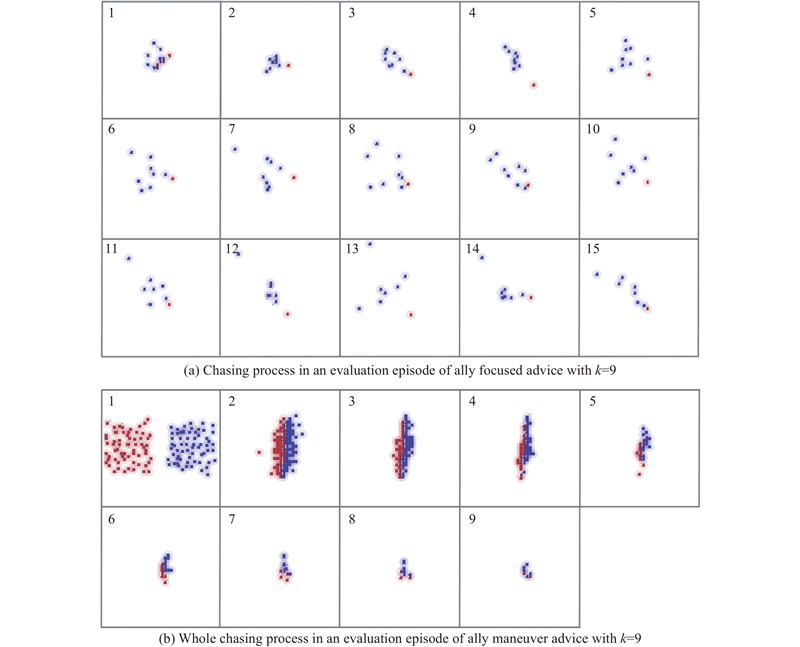

Fig 11
Random battle scenario in MAgent"
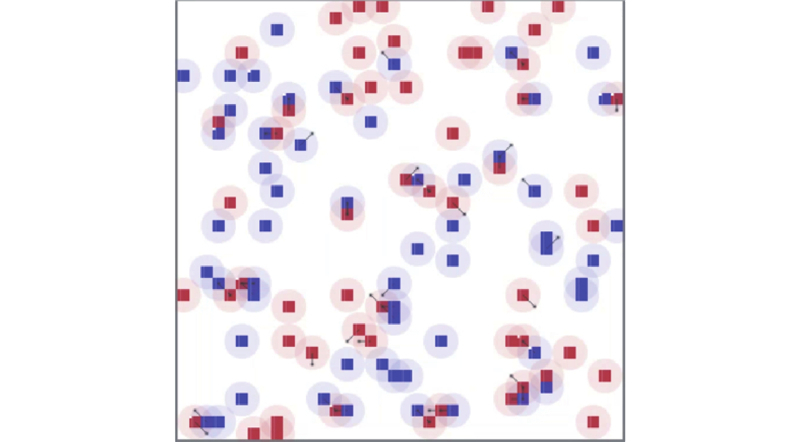
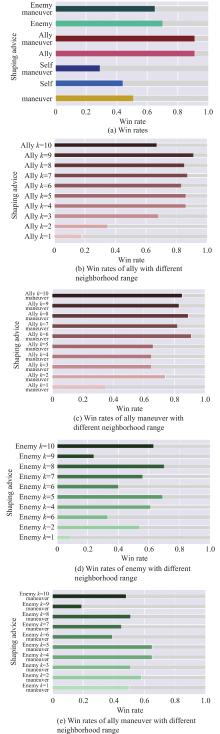
Fig 12
Results of generalization test"
| 1 |
CIL I, MALA M A multi-agent architecture for modelling and simulation of small military unit combat in asymmetric warfare. Expert Systems with Applications, 2010, 37 (2): 1331- 1343.
doi: 10.1016/j.eswa.2009.06.024 |
| 2 | BUSONIU L, BABUSKA R, DE SCHUTTER B A comprehensive survey of multiagent reinforcement learning. IEEE Trans on Systems, Man, and Cybernetics−Part C: Applications and Reviews, 2008, 38, 156- 172. |
| 3 | LIU L B, LUO C M, SHEN F R. Multi-agent formation control with target tracking and navigation. Proc. of the IEEE International Conference on Information and Automation, 2017: 98−103. |
| 4 | WEN G X, CHEN C P, FENG J, et al Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm. IEEE Trans. on Fuzzy Systems, 2017, 26, 2719- 2731. |
| 5 | YANG J C, ZHANG J P, WANG H H. Urban traffic control in software defined internet of things via a multi-agent deep reinforcement learning approach. IEEE Trans. on Intelligent Transportation Systems, 2020, 22: 3742–3754. |
| 6 | WIERING M A. Multi-agent reinforcement learning for traffic light control. Proc. of the 17th International Conferenconeon Machine Learning, 2000: 1151−1158. |
| 7 |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575 (7782): 350- 354.
doi: 10.1038/s41586-019-1724-z |
| 8 | CHANG Y H, HO T, KAELBLING L. All learning is local: multi-agent learning in global reward games. Proc. of the Advances in Neural Information Processing Systems, 2003: 16. |
| 9 |
AGOGINO A K, TUMER K Analyzing and visualizing multiagent rewards in dynamic and stochastic domains. Autonomous Agents and Multi-Agent Systems, 2008, 17, 320- 338.
doi: 10.1007/s10458-008-9046-9 |
| 10 |
DEVLIN S, KUDENKO D, GRZES M An empirical study of potential-based reward shaping and advice in complex, multi-agent systems. Advances in Complex Systems, 2011, 14 (2): 251- 278.
doi: 10.1142/S0219525911002998 |
| 11 | DEVLIN S, YLINIEMI L, KUDENKO D, et al. Potential-based difference rewards for multiagent reinforcement learning. Proc. of the International Conference on Autonomous Agents and Multi-Agent Systems, 2014: 165−172. |
| 12 | LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. Proc. of the 31st International Conference on Neural Information Processing Systems, 2017, 30: 6382−6393. |
| 13 | FOERSTER J, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. https://doi.org/10.1609/aaai.v32il.11794. |
| 14 | LI J H, KUANG K, WANG B X, et al. Shapley counterfactual credits for multi-agent reinforcement learning. Proc. of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021: 934−942. |
| 15 | SHAPLEY L S. A value for n-person games. WILLIAM K H, ed. Classics in game theory. Princeton: Princeton University Press, 1997. |
| 16 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning. https://arxiv.org/abs/1706.05296. |
| 17 | RASHID T, SAMVELYAN M, DE WITT C S, et al Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research, 2020, 21 (1): 7234- 7284. |
| 18 | NG A Y, HARADA D, RUSSELL S. Policy invariance under reward transformations: theory and application to reward shaping. Proc. of the International Conference on Machine Learning, 1999: 278−287. |
| 19 | BRYS T, HARUTYUNYAN A, SUAY H B, et al. Reinforcement learning from demonstration through shaping. Proc. of the 24th International Joint Conference on Artificial Intelligence, 2015: 3352−3358. |
| 20 | BADNAVA B, MOZAYANI N. A new potential-based reward shaping for reinforcement learning agent. Proc. of the 13th Annual Computing and Communication Workshop and Conference, 2023. DOI: 10.1109/CCWC57344.2023.10099211. |
| 21 | WANG Z, LI H, WU H L, et al. Improving maneuver strategy in air combat by alternate freeze games with a deep reinforcement learning algorithm. Mathematical Problems in Engineering, 2020, 2020: 7180639. |
| 22 | SAMVELYAN M, RASHID T, DE WITT C S, et al. The starcraft multi-agent challenge. https://arxiv.org/abs/1902.04043. |
| 23 |
HUANG L W, FU M S, QU H, et al A deep reinforcement learning-based method applied for solving multi-agent defense and attack problems. Expert Systems with Applications, 2021, 176, 114896.
doi: 10.1016/j.eswa.2021.114896 |
| 24 | BROCKMAN G, CHEUNG V, PETTERSSON L, et al. Openai gym. https://arxiv.org/abs/1606.01540. |
| 25 | ZAMORA I, LOPEZ N G, VILCHES V M, et al. Extending the openai gym for robotics: a toolkit for reinforcement learning using ros and gazebo. https://arxiv.org/abs/1608.05742. |
| 26 | MORDATCH I, ABBEEL P. Emergence of grounded compositional language in multi-agent populations. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. DOI: https://doi.org/10.1609/aaai.v32i1.11492. |
| 27 | LIU I J, JAIN U, YEH R A, et al. Cooperative exploration for multi-agent deep reinforcement learning. Proc. of the International Conference on Machine Learning, 2021: 6826−6836. |
| 28 | ZHENG L M, YANG J C, CAI H, et al. Magent: a many-agent reinforcement learning platform for artificial collective intelligence. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. DOI: https://doi.org/10.1609/aaai.v32i1.11371. |
| 29 | YANG Y D, LUO R, LI M, et al. Mean field multi-agent reinforcement learning. Proc. of the International Conference on Machine Learning, 2018: 5571−5580. |
| 30 | DEVLIN S, KUDENKO D. Theoretical considerations of potential-based reward shaping for multi-agent systems. Proc. of the 10th International Conference on Autonomous Agents and Multiagent Systems, 2011: 225−232. |
| 31 | ASMUTH J, LITTMAN M L, ZINKOV R. Potential-based shaping in model-based reinforcement learning. Proc. of the AAAI Conference on Artificial Intelligence, 2008: 604–609. |
| [1] | Guang ZHAN, Kun ZHANG, Ke LI, Haiyin PIAO. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience [J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 644-665. |
| [2] | Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224. |
| [3] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [4] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [5] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [6] | Ang GAO, Qisheng GUO, Zhiming DONG, Zaijiang TANG, Ziwei ZHANG, Qiqi FENG. Research on virtual entity decision model for LVC tactical confrontation of army units [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1249-1267. |
| [7] | Wenzhang LIU, Lu DONG, Jian LIU, Changyin SUN. Knowledge transfer in multi-agent reinforcement learning with incremental number of agents [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 447-460. |
| [8] | Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||