
Journal of Systems Engineering and Electronics ›› 2023, Vol. 34 ›› Issue (1): 99-116.doi: 10.23919/JSEE.2023.000022
• SYSTEMS ENGINEERING • Previous Articles Next Articles
Xing LEI1,2( ), Xiaoxuan HU1,2(), Guoqiang WANG1,2,3(), He LUO1,3,*()
), Xiaoxuan HU1,2(), Guoqiang WANG1,2,3(), He LUO1,3,*()
Received:2021-07-14
Online:2023-02-18
Published:2023-03-03
Contact:
He LUO
E-mail:leixing@mail.hfut.edu.cn;xiaoxuanhu@hfut.edu.cn;gqwang2017@hfut.edu.cn;luohe@hfut.edu.cn
About author:Supported by:Xing LEI, Xiaoxuan HU, Guoqiang WANG, He LUO. A multi-UAV deployment method for border patrolling based on Stackelberg game[J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 99-116.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
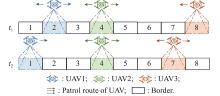
Fig 1
Possible patrol path of three UAVs at a certain altitude between two consecutive time points"
Fig 2
Examples of directed graph"
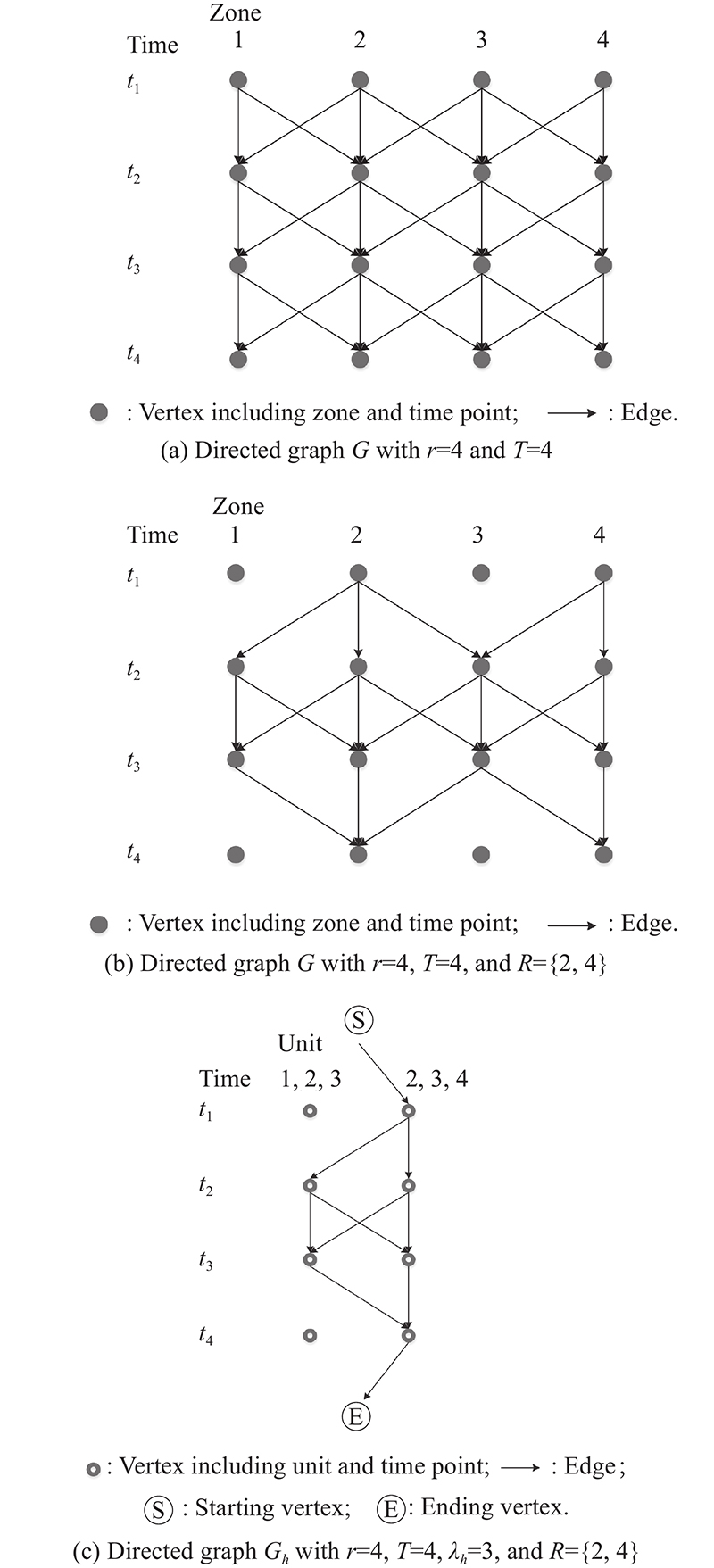
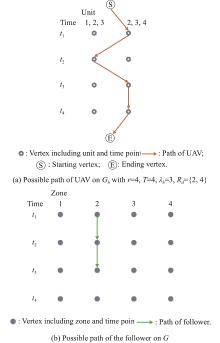
Fig 3
Examples of path of the UAV and the follower"
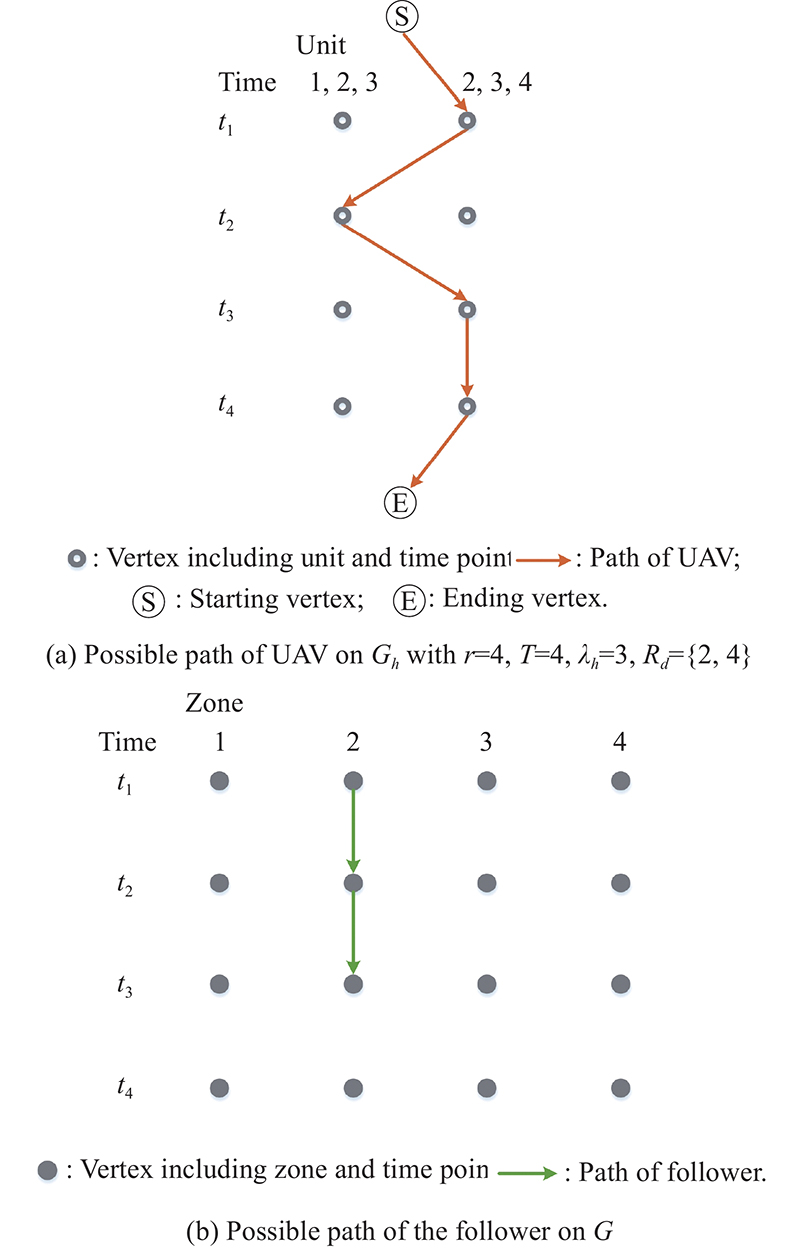
Table 1
Average results on utilities of four CRLPs, ACS, and PCS for all instances % "
| Set | UAV | Percentage difference | | | | | |||||||
| PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | ||||||
| Set A | 20 | Aver | 1.62 | 1.69 | −0.05 | 0.02 | 5.08 | 5.14 | 4.88 | 4.95 | |||
| Max | 3.75 | 3.70 | 0.08 | 0.20 | 11.07 | 10.99 | 10.73 | 10.75 | |||||
| Min | 0.70 | 0.74 | −0.35 | −0.43 | 2.28 | 2.32 | 2.17 | 2.22 | |||||
| All | Aver | 1.02 | 1.06 | −0.03 | 0.01 | 3.20 | 3.24 | 3.08 | 3.12 | ||||
| Max | 3.75 | 3.70 | 0.08 | 0.20 | 11.07 | 10.99 | 10.73 | 10.75 | |||||
| Min | 0.18 | 0.19 | −0.35 | −0.43 | 0.58 | 0.58 | 0.55 | 0.56 | |||||
| Set B | 20 | Aver | 2.63 | 3.03 | −0.31 | 0.10 | 6.48 | 6.85 | 6.23 | 6.61 | |||
| Max | 5.84 | 7.10 | −0.11 | 0.68 | 13.83 | 14.98 | 13.32 | 14.42 | |||||
| Min | 1.14 | 1.30 | −1.11 | −0.42 | 2.86 | 3.07 | 2.80 | 2.90 | |||||
| All | Aver | 1.65 | 1.90 | −0.19 | 0.10 | 4.10 | 4.34 | 3.94 | 4.18 | ||||
| Max | 5.84 | 7.10 | −0.03 | 0.68 | 13.83 | 14.98 | 13.32 | 14.42 | |||||
| Min | 0.29 | 0.33 | −1.11 | −0.42 | 0.72 | 0.78 | 0.71 | 0.73 | |||||
| Set C | 20 | Aver | 6.94 | 10.43 | 1.14 | 4.93 | 7.60 | 11.06 | 6.65 | 10.15 | |||
| Max | 16.29 | 23.54 | 3.20 | 11.25 | 17.21 | 24.38 | 14.38 | 21.75 | |||||
| Min | 3.09 | 4.38 | 0.29 | 1.86 | 3.39 | 4.67 | 2.96 | 4.33 | |||||
| All | Aver | 4.42 | 6.67 | 0.71 | 3.11 | 4.82 | 7.05 | 4.20 | 6.46 | ||||
| Max | 16.29 | 23.54 | 3.20 | 11.25 | 17.21 | 24.38 | 14.38 | 21.75 | |||||
| Min | 0.78 | 1.11 | 0.07 | 0.47 | 0.86 | 1.19 | 0.75 | 1.10 | |||||
Table 2
Results on utilities of four CRLPs, ACS and PCS for Set A instances with six time points % "
| Inst | Zone | UAV | | | | | |||||||
| PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | ||||||
| A01 | 200 | 5 | 0.95 | 0.90 | −0.06 | −0.11 | 2.89 | 2.84 | 2.72 | 2.67 | |||
| 10 | 1.89 | 1.80 | −0.12 | −0.21 | 5.70 | 5.60 | 5.36 | 5.27 | |||||
| 15 | 2.83 | 2.69 | −0.18 | −0.32 | 8.42 | 8.29 | 7.93 | 7.79 | |||||
| 20 | 3.75 | 3.56 | −0.23 | −0.43 | 11.07 | 10.90 | 10.43 | 10.25 | |||||
| A07 | 400 | 5 | 0.48 | 0.48 | −0.01 | −0.02 | 1.46 | 1.46 | 1.38 | 1.38 | |||
| 10 | 0.96 | 0.95 | −0.03 | −0.04 | 2.91 | 2.90 | 2.75 | 2.74 | |||||
| 15 | 1.44 | 1.42 | −0.04 | −0.06 | 4.33 | 4.31 | 4.09 | 4.08 | |||||
| 20 | 1.92 | 1.89 | −0.06 | −0.08 | 5.73 | 5.71 | 5.42 | 5.40 | |||||
| A13 | 600 | 5 | 0.32 | 0.33 | 0.00 | 0.00 | 0.98 | 0.98 | 0.92 | 0.93 | |||
| 10 | 0.65 | 0.65 | 0.00 | 0.00 | 1.94 | 1.95 | 1.84 | 1.85 | |||||
| 15 | 0.97 | 0.98 | 0.00 | 0.01 | 2.90 | 2.91 | 2.75 | 2.76 | |||||
| 20 | 1.29 | 1.30 | 0.00 | 0.01 | 3.85 | 3.86 | 3.65 | 3.66 | |||||
| A19 | 800 | 5 | 0.24 | 0.24 | −0.01 | −0.02 | 0.73 | 0.73 | 0.68 | 0.68 | |||
| 10 | 0.47 | 0.47 | −0.03 | −0.03 | 1.45 | 1.45 | 1.36 | 1.36 | |||||
| 15 | 0.71 | 0.71 | −0.04 | −0.05 | 2.17 | 2.16 | 2.03 | 2.03 | |||||
| 20 | 0.94 | 0.94 | −0.06 | −0.06 | 2.88 | 2.87 | 2.70 | 2.69 | |||||
| A25 | 1000 | 5 | 0.19 | 0.20 | −0.01 | 0.00 | 0.58 | 0.59 | 0.55 | 0.56 | |||
| 10 | 0.38 | 0.39 | −0.01 | 0.00 | 1.17 | 1.18 | 1.11 | 1.12 | |||||
| 15 | 0.57 | 0.59 | −0.02 | 0.00 | 1.74 | 1.76 | 1.65 | 1.67 | |||||
| 20 | 0.76 | 0.79 | −0.03 | 0.00 | 2.32 | 2.34 | 2.20 | 2.22 | |||||
Table 3
Results on utilities of four CRLPs, ACS and PCS for Set C instances with 200 zones % "
| Inst | TP | UAV | | | | | |||||||
| PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | PD-ACS | PD-PCS | ||||||
| C01 | 6 | 5 | 4.35 | 6.49 | 0.72 | 2.94 | 4.61 | 6.75 | 3.71 | 5.86 | |||
| 10 | 8.50 | 12.56 | 1.43 | 5.79 | 9.01 | 13.04 | 7.28 | 11.38 | |||||
| 15 | 12.48 | 18.23 | 2.13 | 8.56 | 13.20 | 18.91 | 10.71 | 16.58 | |||||
| 20 | 16.29 | 23.54 | 2.83 | 11.25 | 17.21 | 24.38 | 14.02 | 21.47 | |||||
| C02 | 12 | 5 | 3.87 | 5.70 | 0.54 | 2.43 | 4.26 | 6.08 | 3.75 | 5.58 | |||
| 10 | 7.60 | 11.08 | 1.09 | 4.81 | 8.34 | 11.79 | 7.36 | 10.85 | |||||
| 15 | 11.18 | 16.15 | 1.63 | 7.13 | 12.24 | 17.15 | 10.84 | 15.82 | |||||
| 20 | 14.62 | 20.93 | 2.16 | 9.39 | 15.98 | 22.18 | 14.18 | 20.52 | |||||
| C03 | 18 | 5 | 3.87 | 5.58 | 0.39 | 2.16 | 4.25 | 5.96 | 3.54 | 5.26 | |||
| 10 | 7.59 | 10.85 | 0.77 | 4.28 | 8.33 | 11.57 | 6.96 | 10.25 | |||||
| 15 | 11.16 | 15.83 | 1.15 | 6.35 | 12.23 | 16.84 | 10.26 | 14.97 | |||||
| 20 | 14.60 | 20.53 | 1.53 | 8.37 | 15.96 | 21.80 | 13.44 | 19.45 | |||||
| C04 | 24 | 5 | 3.90 | 5.80 | 0.81 | 2.77 | 4.27 | 6.16 | 3.81 | 5.71 | |||
| 10 | 7.65 | 11.26 | 1.61 | 5.46 | 8.35 | 11.94 | 7.47 | 11.09 | |||||
| 15 | 11.25 | 16.41 | 2.41 | 8.08 | 12.26 | 17.36 | 10.99 | 16.17 | |||||
| 20 | 14.72 | 21.26 | 3.20 | 10.63 | 16.01 | 22.45 | 14.38 | 20.95 | |||||
| C05 | 30 | 5 | 3.96 | 6.17 | 0.56 | 2.84 | 4.28 | 6.48 | 3.73 | 5.95 | |||
| 10 | 7.76 | 11.95 | 1.11 | 5.60 | 8.37 | 12.54 | 7.33 | 11.54 | |||||
| 15 | 11.41 | 17.38 | 1.66 | 8.29 | 12.29 | 18.20 | 10.79 | 16.80 | |||||
| 20 | 14.92 | 22.48 | 2.21 | 10.89 | 16.05 | 23.50 | 14.12 | 21.75 | |||||
| C06 | 36 | 5 | 3.75 | 5.59 | 0.61 | 2.51 | 4.13 | 5.96 | 3.70 | 5.54 | |||
| 10 | 7.35 | 10.86 | 1.21 | 4.96 | 8.08 | 11.56 | 7.27 | 10.78 | |||||
| 15 | 10.82 | 15.84 | 1.82 | 7.34 | 11.87 | 16.83 | 10.70 | 15.73 | |||||
| 20 | 14.16 | 20.54 | 2.41 | 9.67 | 15.51 | 21.79 | 14.01 | 20.40 | |||||
Table 4
Average results on UAVs needed for four CRLPs for all instances"
| Zone | Goal | Inst | Minimum_UAV | |||
| | | | | |||
| 200 | 0.2 | A01-A06 | 232 | 317 | 148 | 151 |
| B01-B06 | 133 | 183 | 97 | 99 | ||
| C01-C06 | 67 | 93 | 65 | 68 | ||
| 0.8 | A01-A06 | 33 | 45 | 21 | 21 | |
| B01-B06 | 19 | 26 | 14 | 14 | ||
| C01-C06 | 10 | 13 | 9 | 10 | ||
| 400 | 0.2 | A07-A12 | 464 | 630 | 295 | 301 |
| B07-B12 | 266 | 362 | 194 | 198 | ||
| C07-C12 | 133 | 185 | 130 | 135 | ||
| 0.8 | A07-A12 | 65 | 88 | 42 | 42 | |
| B07-B12 | 37 | 51 | 27 | 28 | ||
| C07-C12 | 19 | 26 | 18 | 19 | ||
| 600 | 0.2 | A13-A18 | 696 | 951 | 443 | 452 |
| B13-B18 | 399 | 543 | 290 | 295 | ||
| C13-C18 | 200 | 260 | 194 | 204 | ||
| 0.8 | A13-A18 | 97 | 132 | 62 | 63 | |
| B13-B18 | 56 | 76 | 41 | 41 | ||
| C13-C18 | 28 | 39 | 28 | 29 | ||
| 800 | 0.2 | A19-A24 | 929 | 1270 | 590 | 603 |
| B19-B24 | 531 | 726 | 387 | 394 | ||
| C19-C24 | 266 | 369 | 258 | 270 | ||
| 0.8 | A19-A24 | 129 | 176 | 82 | 84 | |
| B19-B24 | 74 | 101 | 54 | 55 | ||
| C19-C24 | 37 | 51 | 36 | 38 | ||
| 1000 | 0.2 | A25-A30 | 1160 | 1584 | 737 | 754 |
| B25-B30 | 663 | 906 | 484 | 492 | ||
| C25-C30 | 332 | 460 | 323 | 338 | ||
| 0.8 | A25-A30 | 161 | 220 | 103 | 105 | |
| B25-B30 | 93 | 126 | 68 | 69 | ||
| C25-C30 | 47 | 64 | 45 | 47 | ||
Table 5
Results on UAVs needed for four CRLPs for Set B instances"
| Inst | Zone | Goal | Minimum_UAVs | |||
| | | | | |||
| B01-B06 | 200 | 0.2 | 133 | 183 | 97 | 99 |
| 0.4 | 76 | 104 | 56 | 57 | ||
| 0.6 | 43 | 58 | 31 | 32 | ||
| 0.8 | 19 | 26 | 14 | 14 | ||
| B07-B12 | 400 | 0.2 | 266 | 362 | 194 | 198 |
| 0.4 | 152 | 207 | 111 | 113 | ||
| 0.6 | 85 | 115 | 62 | 63 | ||
| 0.8 | 37 | 51 | 27 | 28 | ||
| B13-B18 | 600 | 0.2 | 399 | 543 | 290 | 295 |
| 0.4 | 227 | 309 | 166 | 169 | ||
| 0.6 | 127 | 173 | 93 | 94 | ||
| 0.8 | 56 | 76 | 41 | 41 | ||
| B19-B24 | 800 | 0.2 | 531 | 726 | 387 | 394 |
| 0.4 | 303 | 413 | 220 | 225 | ||
| 0.6 | 169 | 231 | 123 | 125 | ||
| 0.8 | 74 | 101 | 54 | 55 | ||
| B25-B30 | 1000 | 0.2 | 663 | 906 | 484 | 492 |
| 0.4 | 378 | 516 | 276 | 281 | ||
| 0.6 | 211 | 288 | 154 | 156 | ||
| 0.8 | 93 | 126 | 68 | 69 | ||
Table 6
Average results on robustness of four CRLPs compared with itself, ACS and PCS for all instances % "
| Set | Case | Percentage difference | | | | |
| Set A | Prop | PDP-I | −0.59 | −0.43 | 0.02 | 0.06 |
| PDP-ACS | 0.44 | −0.46 | 3.22 | 3.14 | ||
| PDP-PCS | 0.48 | −0.42 | 3.26 | 3.18 | ||
| Cover | PDC-I | −0.40 | −0.29 | 0.02 | −0.04 | |
| PDC-ACS | 0.63 | −0.32 | 3.22 | 3.04 | ||
| PDC-PCS | 0.67 | −0.28 | 3.26 | 3.08 | ||
| Set B | Prop | PDP-I | −1.38 | −0.97 | 0.00 | 0.21 |
| PDP-ACS | 0.31 | −1.16 | 4.10 | 4.13 | ||
| PDP-PCS | 0.56 | −0.90 | 4.34 | 4.37 | ||
| Cover | PDC-I | −0.70 | −0.51 | −0.02 | 0.21 | |
| PDC-ACS | 0.97 | −0.70 | 4.08 | 4.14 | ||
| PDC-PCS | 1.23 | −0.44 | 4.32 | 4.38 | ||
| Set C | Prop | PDP-I | −2.59 | −1.33 | −0.02 | 0.24 |
| PDP-ACS | 1.99 | −0.60 | 4.80 | 4.43 | ||
| PDP-PCS | 4.32 | 1.84 | 7.04 | 6.68 | ||
| Cover | PDC-I | −1.38 | −0.92 | 0.01 | 0.20 | |
| PDC-ACS | 3.14 | −0.20 | 4.83 | 4.39 | ||
| PDC-PCS | 5.44 | 2.23 | 7.06 | 6.65 |
Table 7
Results in the case of deviation of detection probability for Set C instances % "
| PDP | UAV | Percentage difference | | | | |
| PDP-I | 20 | Aver | −3.92 | −1.93 | −0.02 | 0.28 |
| Max | −1.89 | −0.43 | 0.36 | 1.73 | ||
| Min | −9.66 | −3.52 | −1.47 | −0.88 | ||
| All | Aver | −2.59 | −1.33 | −0.02 | 0.24 | |
| Max | −0.43 | −0.14 | 0.57 | 2.09 | ||
| Min | −9.66 | −4.83 | −1.47 | −1.48 | ||
| PDP-ACS | 20 | Aver | 3.34 | −0.77 | 7.59 | 6.91 |
| Max | 14.70 | 0.97 | 17.33 | 14.55 | ||
| Min | 0.27 | −2.38 | 3.39 | 2.19 | ||
| All | Aver | 1.99 | −0.60 | 4.80 | 4.43 | |
| Max | 14.70 | 1.23 | 17.33 | 14.55 | ||
| Min | 0.02 | −3.62 | 0.85 | 0.37 | ||
| PDP-PCS | 20 | Aver | 6.98 | 3.11 | 11.04 | 10.41 |
| Max | 22.09 | 9.55 | 24.49 | 21.71 | ||
| Min | 1.93 | −0.34 | 4.84 | 3.49 | ||
| All | Aver | 4.32 | 1.84 | 7.04 | 6.68 | |
| Max | 22.09 | 9.55 | 24.49 | 21.71 | ||
| Min | 0.40 | −0.40 | 1.28 | 0.88 |
Table 8
Results in the case of deviation of coverage for Set C instances % "
| PDC | UAV | Percentage difference | | | | |
| PDC-I | 20 | Aver | −2.16 | −1.49 | 0.12 | 0.35 |
| Max | 0.00 | −0.03 | 2.70 | 1.70 | ||
| Min | −5.09 | −3.56 | −0.97 | −1.28 | ||
| All | Aver | −1.38 | −0.92 | 0.01 | 0.20 | |
| Max | 0.00 | 0.00 | 2.70 | 1.70 | ||
| Min | −5.09 | −3.56 | −1.34 | −1.76 | ||
| PDC-ACS | 20 | Aver | 4.99 | −0.32 | 7.71 | 6.98 |
| Max | 12.03 | 2.80 | 18.23 | 15.60 | ||
| Min | 2.16 | −1.84 | 2.97 | 2.92 | ||
| All | Aver | 3.14 | −0.20 | 4.83 | 4.39 | |
| Max | 12.03 | 2.80 | 18.23 | 15.60 | ||
| Min | 0.53 | −1.84 | 0.75 | 0.54 | ||
| PDC-PCS | 20 | Aver | 8.58 | 3.54 | 11.16 | 10.47 |
| Max | 19.65 | 11.22 | 24.44 | 22.20 | ||
| Min | 3.46 | 1.17 | 4.58 | 4.22 | ||
| All | Aver | 5.44 | 2.23 | 7.06 | 6.65 | |
| Max | 19.65 | 11.22 | 24.44 | 22.20 | ||
| Min | 0.88 | 0.29 | 1.25 | 1.02 |
Table 9
Average results on runtime of four CRLPs for all instances with and without DS-EM"
| Set | UAV | IR-CPU/% | | | | |
| Set A | 20 | Aver | 72.32 | 60.05 | 82.26 | 84.50 |
| Max | 96.40 | 89.07 | 98.06 | 98.89 | ||
| Min | 37.33 | 9.76 | 22.49 | 12.26 | ||
| All | Aver | 73.33 | 61.38 | 81.56 | 84.99 | |
| Max | 97.13 | 90.74 | 98.06 | 98.95 | ||
| Min | 17.84 | 9.76 | 18.67 | 2.16 | ||
| Set B | 20 | Aver | 76.24 | 57.83 | 82.83 | 84.79 |
| Max | 96.56 | 87.21 | 97.15 | 98.69 | ||
| Min | 27.98 | 5.66 | 21.49 | 35.57 | ||
| All | Aver | 74.73 | 59.59 | 84.64 | 84.14 | |
| Max | 96.89 | 91.22 | 97.52 | 98.82 | ||
| Min | 6.57 | 5.66 | 18.86 | 17.70 | ||
| Set C | 20 | Aver | 80.33 | 72.75 | 81.23 | 82.37 |
| Max | 98.26 | 90.55 | 97.16 | 98.66 | ||
| Min | 45.19 | 45.87 | 18.71 | 1.81 | ||
| All | Aver | 79.42 | 70.53 | 80.20 | 83.23 | |
| Max | 98.26 | 90.73 | 97.16 | 98.86 | ||
| Min | 35.63 | 24.81 | 9.41 | 1.81 |
Table 10
Results on runtime of four CRLPs for Set A instances with 24 time points % "
| Inst | Zone | IR-CPU | |||
| | | | | ||
| A04 | 200 | 90.50 | 86.86 | 92.61 | 93.10 |
| A10 | 400 | 91.54 | 85.78 | 97.75 | 96.87 |
| A16 | 600 | 66.13 | 86.45 | 96.41 | 96.25 |
| A22 | 800 | 61.65 | 84.55 | 96.59 | 95.96 |
| A28 | 1 000 | 86.80 | 88.62 | 95.36 | 95.71 |
Table 11
Results on runtime of four CRLPs for Set B instances with 600 zones % "
| Inst | TP | IR-CPU | |||
| | | | | ||
| B13 | 6 | 58.90 | 51.49 | 39.41 | 52.09 |
| B14 | 12 | 72.19 | 66.85 | 89.45 | 64.33 |
| B15 | 18 | 80.98 | 75.89 | 94.61 | 96.57 |
| B16 | 24 | 81.36 | 79.93 | 95.17 | 94.83 |
| B17 | 30 | 85.46 | 45.58 | 95.60 | 94.79 |
| B18 | 36 | 86.17 | 36.93 | 95.46 | 94.58 |
| 1 | SECURITY H. Border security results. https://www.dhs.gov/border-security-results. |
| 2 | PROTECTION U C A B. 2020 U.S. border patrol strategy. https://www.cbp.gov/border-security/along-us-borders/strategy. |
| 3 |
LINEBARGER C, BRAITHWAITE A Do walls work? The effectiveness of border barriers in containing the cross-border spread of violent militancy. International Studies Quarterly, 2020, 64 (3): 487- 498.
doi: 10.1093/isq/sqaa035 |
| 4 |
JORDAN S, MOORE J, HOVET S, et al State-of-the-art technologies for UAV inspections. IET Radar, Sonar & Navigation, 2018, 12 (2): 151- 164.
doi: 10.1371/journal.pone.0109881 |
| 5 |
GUO S, XIONG X X, LIU Z C, et al Infrared simulation of large-scale urban scene through LOD. Optices Express, 2018, 26 (18): 23980- 24002.
doi: 10.1049/iet-rsn.2017.0251 |
| 6 |
ZHOU R H, SUN H M, LI H, et al TDOA and track optimization of UAV swarm based on D-optimality. Journal of Systems Engineering and Electronics, 2020, 31 (6): 1140- 1151.
doi: 10.1364/OE.26.023980 |
| 7 | FRONTEX. Frontex R&D UAV workshop and Demo 2011 - call for expressions of interest. https://frontex.europa.eu/future-of-border-control/research-and-innovation/announcements/frontex-r-d-uav-workshop-and-demo-2011-call-for-expressions-of-interest-EDouHq. |
| 8 |
CASORRAN C, FORTZ B, LABBE M, et al A study of general and security Stackelberg game formulations. European Journal of Operational Research, 2019, 278 (3): 855- 868.
doi: 10.1016/j.ejor.2019.05.012 |
| 9 |
PITA J, JAIN M, MARECKI J, et al Deployed ARMOR protection_the application of a game theoretic model for security at the Los Angeles International Airport. Proc. of the 7th International Conference on Autonomous Agents and Multiagent Systems, 2008, 125- 132.
doi: 10.5555/1402795.1402819 |
| 10 |
TSAI J, RATHI S, KIEKINTVELD C, et al IRIS-a tool for strategic security allocation in transportation networks. Proc. of the 8th International Conference on Autonomous Agents and Multiagent Systems, 2009, 37- 44.
doi: 10.1017/CBO9780511973031.005 |
| 11 | PITA J, TAMBE M, KIEKINTVELD C, et al GUARDS-game theoretic security allocation on a national scale. Proc. of the 10th International Conference on Autonomous Agents and Multiagent Systems, 2011, 37- 44. |
| 12 |
MUAAFA M, RAMIREZ-MARQUEZ J E Bi-objective evolutionary approach to the design of patrolling schemes for improved border security. Computers & Industrial Engineering, 2017, (107): 74- 84.
doi: 10.1016/j.cie.2017.03.010 |
| 13 |
BUCAREY L V, CASORRAN C, LABBE M, et al Coordinating resources in stackelberg security games. European Journal of Operational Research, 2021, 291 (3): 846- 861.
doi: 10.1016/j.ejor.2019.11.002 |
| 14 |
KARABULUT E, ARAS N, KUBAN ALTıNEL I Optimal sensor deployment to increase the security of the maximal breach path in border surveillance. European Journal of Operational Research, 2017, 259 (1): 19- 36.
doi: 10.1016/j.ejor.2016.09.016 |
| 15 |
LESSIN A M, LUNDAY B J, HILL R R A bilevel exposure-oriented sensor location problem for border security. Computers & Operations Research, 2018, 98, 56- 68.
doi: 10.1016/j.cor.2018.05.017 |
| 16 |
BAYKAL-GURSOY M, DUAN Z, POOR H V, et al Infrastructure security games. European Journal of Operational Research, 2014, 239 (2): 469- 478.
doi: 10.1016/j.ejor.2014.04.033 |
| 17 |
YOLMEH A, BAYKAL-GURSOY M A robust approach to infrastructure security games. Computers & Industrial Engineering, 2017, 110, 515- 526.
doi: 10.1016/j.cie.2017.06.032 |
| 18 |
JIE Y M, LIU C Z, LI M C, et al Game theoretic resource allocation model for designing effective traffic safety solution against drunk driving. Applied Mathematics and Computation, 2020, 376, 125142.
doi: 10.1016/j.amc.2020.125142 |
| 19 | SHIEH E, AN B, YANG R, et al PROTECT: a deployed game theoretic system to protect the ports of the United States. Proc. of the 11th International Conference on Autonomous Agents and Multiagent Systems, 2012, 13- 20. |
| 20 |
PAULSON E C, LINKOV I, KEISLER J M A game theoretic model for resource allocation among countermeasures with multiple attributes. European Journal of Operational Research, 2016, 252 (2): 610- 622.
doi: 10.1016/j.ejor.2016.01.026 |
| 21 |
GOLANY B, GOLDBERG N, ROTHBLUM U G A two-resource allocation algorithm with an application to large-scale zero-sum defensive games. Computers & Operations Research, 2017, 78, 218- 229.
doi: 10.1016/j.cor.2016.08.013 |
| 22 |
CANBOLAT M S, WESOLOWSKY G O A planar single facility location and border crossing problem. Computers & Operations Research, 2012, 39 (12): 3156- 3165.
doi: 10.1016/j.cor.2012.04.002 |
| 23 |
BASILICO N, GATTI N, AMIGONI F Patrolling security games: definition and algorithms for solving large instances with single patroller and single intruder. Artificial Intelligence, 2012, 184/185, 78- 123.
doi: 10.1016/j.artint.2012.03.003 |
| 24 |
YIN Z Y, JIANG A X, TAMBE M, et al Trusts: scheduling randomized patrols for fare inspection in transit systems using game theory. AI Magazine, 2012, 33 (4): 59- 72.
doi: 10.5555/2900929.2901063 |
| 25 | BASILICO N, GATTI N, AMIGONI F Leader-follower strategies for robotic patrolling in environments with arbitrary topologies. Proc. of the 8th International Conference on Autonomous Agents and Multiagent Systems, 2009, 57- 64. |
| 26 |
ALPERN S, MORTON A, PAPADAKI K Patrolling games. Operations Research, 2011, 59 (5): 1246- 1257.
doi: 10.1287/opre.1110.0983 |
| 27 |
ALPERN S, LIDBETTER T, PAPADAKI K Optimizing periodic patrols against short attacks on the line and other networks. European Journal of Operational Research, 2019, 273 (3): 1065- 1073.
doi: 10.1016/j.ejor.2018.08.050 |
| 28 |
PAPADAKI K, ALPERN S, LIDBETTER T, et al Patrolling a border. Operations Research, 2016, 64 (6): 1256- 1269.
doi: 10.1287/opre.2016.1511 |
| 29 |
SARICICEK I, AKKUS Y Unmanned aerial vehicle hub-location and routing for monitoring geographic borders. Applied Mathematical Modelling, 2015, 39 (14): 3939- 3953.
doi: 10.1016/j.apm.2014.12.010 |
| 30 | GIRARD A R, HOWELL A S, HEDRICK J K Border patrol and surveillance missions using multiple unmanned air vehicles. Proc. of the IEEE 43rd Conference on Decision and Control, 2004, 620- 625. |
| 31 |
AMANATIADIS A, BAMPIS L, KARAKASIS E G, et al Real-time surveillance detection system for medium-altitude long-endurance unmanned aerial vehicles. Concurrency and Computation: Practice and Experience, 2018, 30, e4145.
doi: 10.1002/cpe.4145 |
| 32 |
KIM S J, LIM G J Drone-aided border surveillance with an electrification line battery charging system. Journal of Intelligent & Robotic Systems, 2018, 92 (3/4): 657- 670.
doi: 10.1007/s10846-017-0767-3 |
| 33 |
ZHANG Y, YUAN X X, LI W Z, et al Automatic power line inspection using UAV images. Remote Sensing, 2017, 9 (8): 824- 842.
doi: 10.3390/rs9080824 |
| 34 |
ZHOU H L, KONG H, WEI L, et al On detecting road regions in a single UAV image. IEEE Trans. on Intelligent Transportation Systems, 2017, 18 (7): 1713- 1722.
doi: 10.1109/tits.2016.2622280 |
| 35 |
XU J W, DENG Z H, SONG Q, et al Multi-UAV counter-game model based on uncertain information. Applied Mathematics and Computation, 2020, 366, 124684.
doi: 10.1016/j.amc.2019.124684 |
| 36 |
BASILICO N, CARPIN S Online patrolling using hierarchical spatial representations. Proc. of the IEEE International Conference on Robotics and Automation, 2012, 2163- 2169.
doi: 10.1109/ICRA.2012.6224802 |
| 37 | BASILICO N, CHUNG T H, CARPIN S Distributed online patrolling with multi-agent teams of sentinels and searchers. Proc. of the International Symposium on Distributed Autonomous Robotic Systems, 2014, 3- 16. |
| 38 |
BASILICO N, DE NITTIS G, GATTI N Adversarial patrolling with spatially uncertain alarm signals. Artificial Intelligence, 2017, 246, 220- 257.
doi: 10.1016/j.artint.2017.02.007 |
| 39 |
KHANDUZI R, MALEKI H R A novel bilevel model and solution algorithms for multi-period interdiction problem with fortification. Applied Intelligence, 2017, 48 (9): 2770- 2791.
doi: 10.1007/s10489-017-1116-8 |
| 40 | YIN Y, AN B Efficient resource allocation for protecting coral reef ecosystems. Proc. of the 25th International Joint Conference on Artificial Intelligence, 2016, 531- 537. |
| 41 |
KIEKINTVELD C, JAIN M, TSAI J, et al Computing optimal randomized resource allocations for massive security games. Proc. of the 8th International Conference on Autonomous Agents and Multiagent Systems, 2009, 689- 696.
doi: 10.1017/CBO9780511973031.008 |
| [1] | Hao LI, Hemin SUN, Ronghua ZHOU, Huainian ZHANG. Hybrid TDOA/FDOA and track optimization of UAV swarm based on A-optimality [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 149-159. |
| [2] | Weikun HE, Jingbo SUN, Xinyun ZHANG, Zhenming LIU. Micro-Doppler feature extraction of micro-rotor UAV under the background of low SNR [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1127-1139. |
| [3] | Yang XU, Weiming ZHENG, Delin LUO, Haibin DUAN. Dynamic affine formation control of networked under-actuated quad-rotor UAVs with three-dimensional patterns [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1269-1285. |
| [4] | Honghong ZHANG, Xusheng GAN, Shuangfeng LI, Zhiyuan CHEN. UAV safe route planning based on PSO-BAS algorithm [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1151-1160. |
| [5] | Yangjun GAO, Guangyun LI, Zhiwei LYU, Lundong ZHANG, Zhongpan LI. Improved adaptively robust estimation algorithm for GNSS spoofer considering continuous observation error [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1237-1248. |
| [6] | Yuan ZENG, Wenbin LU, Bo YU, Shifei TAO, Haosu ZHOU, Yu CHEN. Improved IMM algorithm based on support vector regression for UAV tracking [J]. Journal of Systems Engineering and Electronics, 2022, 33(4): 867-876. |
| [7] | Dongju CAO, Wendong YANG, Hui CHEN, Yang WU, Xuanxuan TANG. Energy efficiency maximization for buffer-aided multi-UAV relaying communications [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 312-321. |
| [8] | Yangyang JIANG, Yan GAO, Wenqi SONG, Yue LI, Quan QUAN. Bibliometric analysis of UAV swarms [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 406-425. |
| [9] | Jinqiang HU, Husheng WU, Renjun ZHAN, Rafik MENASSEL, Xuanwu ZHOU. Self-organized search-attack mission planning for UAV swarm based on wolf pack hunting behavior [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1463-1476. |
| [10] | Ziquan YU, Youmin ZHANG, Bin JIANG. PID-type fault-tolerant prescribed performance control of fixed-wing UAV [J]. Journal of Systems Engineering and Electronics, 2021, 32(5): 1053-1061. |
| [11] | Juan Antonio VAZQUEZ TREJO, Adrien GUENARD, Manuel ADAM-MEDINA, Jean-Christophe PONSART, Laurent CIARLETTA, Damiano ROTONDO, Didier THEILLIOL. Event-triggered leader-following formation control for multi-agent systems under communication faults: application to a fleet of unmanned aerial vehicles [J]. Journal of Systems Engineering and Electronics, 2021, 32(5): 1014-1022. |
| [12] | Tao YE, Zongyang ZHAO, Jun ZHANG, Xinghua CHAI, Fuqiang ZHOU. Low-altitude small-sized object detection using lightweight feature-enhanced convolutional neural network [J]. Journal of Systems Engineering and Electronics, 2021, 32(4): 841-853. |
| [13] | Gaofeng WU, Kaifang WAN, Xiaoguang GAO, Xiaowei FU. Placement of unmanned aerial vehicles as communication relays in two-tiered multi-agent system: clustering based methods [J]. Journal of Systems Engineering and Electronics, 2020, 31(2): 231-242. |
| [14] | Zhen XU, Enze ZHANG, Qingwei CHEN. Rotary unmanned aerial vehicles path planning in rough terrain based on multi-objective particle swarm optimization [J]. Journal of Systems Engineering and Electronics, 2020, 31(1): 130-141. |
| [15] | Min ZHANG, Chenming ZHENG, Kun HUANG. Fixed-wing UAV guidance law for ground target over-flight tracking [J]. Journal of Systems Engineering and Electronics, 2019, 30(2): 384-392. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||