
Journal of Systems Engineering and Electronics ›› 2026, Vol. 37 ›› Issue (2): 616-635.doi: 10.23919/JSEE.2026.000079
• SYSTEMS ENGINEERING • Previous Articles
Jingbo WANG1,2( ), Liaoyuan ZHU2(), Shaojie XIA2(), Huibin LIU2(), Jing LIU2(), Chongxiao QU2,*(), Zhihuan SONG1()
), Liaoyuan ZHU2(), Shaojie XIA2(), Huibin LIU2(), Jing LIU2(), Chongxiao QU2,*(), Zhihuan SONG1()
Received:2024-01-08
Online:2026-04-18
Published:2026-04-30
Contact:
Chongxiao QU
E-mail:wangjingbo2@cetc.com.cn;zhuliaoyuan1@cetc.com.cn;xiashaojie@cetc.com.cn;liuhuibin@cetc.com.cn;liujing2@cetc.com.cn;quchongxiao@cetc.com.cn;songzhihuan@zju.edu.cn
About author:Supported by:Jingbo WANG, Liaoyuan ZHU, Shaojie XIA, Huibin LIU, Jing LIU, Chongxiao QU, Zhihuan SONG. Application of self-play reinforcement learning and explainable decision tree in intelligent air combat[J]. Journal of Systems Engineering and Electronics, 2026, 37(2): 616-635.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
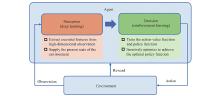
Fig 1
Framework of DRL"
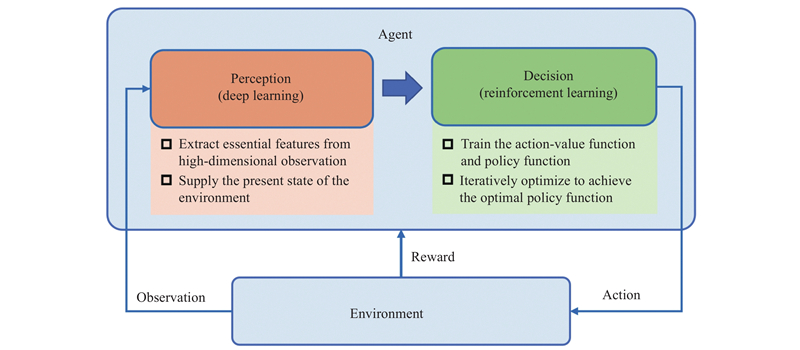

Fig 2
State space of an aircraft"
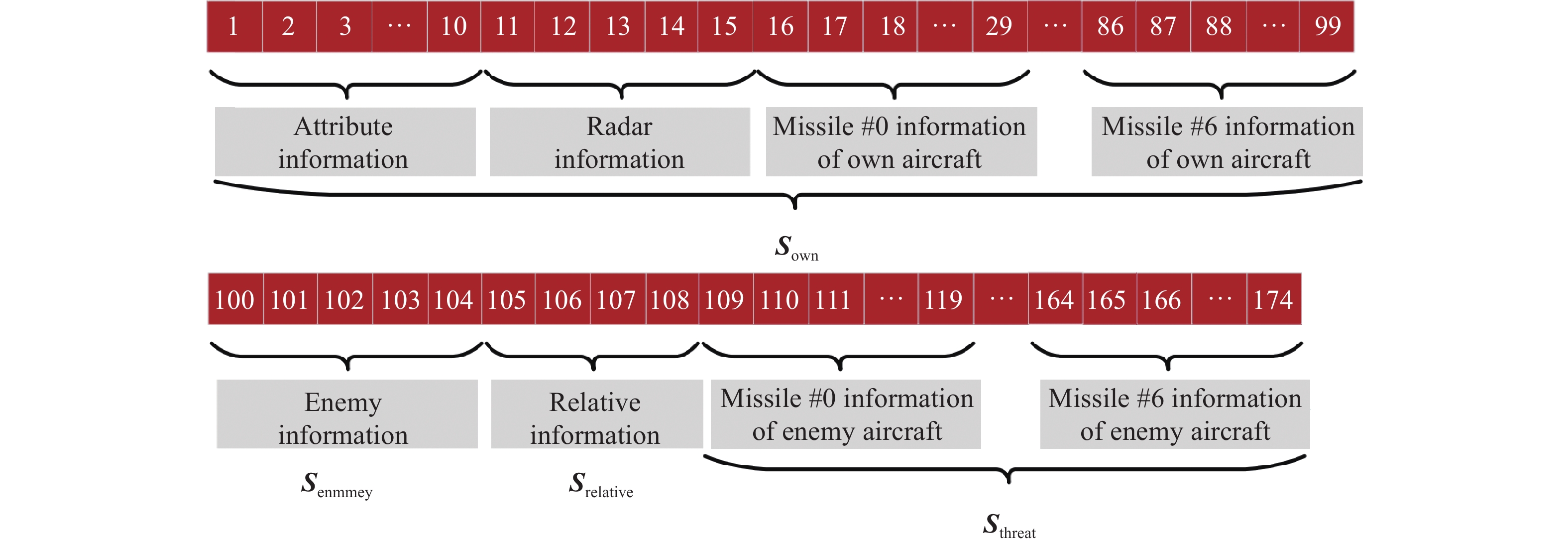
Fig 3
Two-layered framework for designing the action space of the air combat agent"
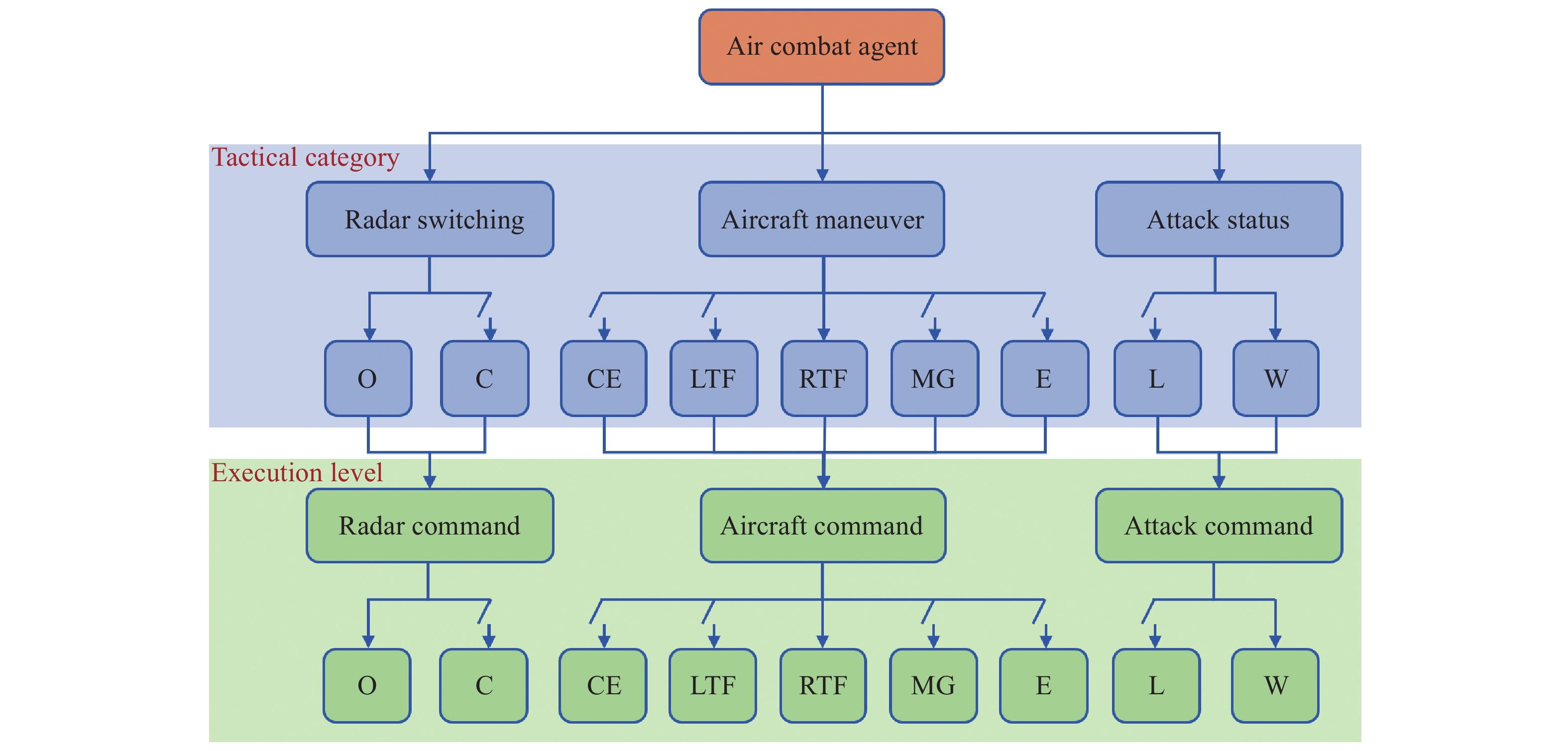
Table 1
Detailed descriptions of maneuver, radar switching, and attack status"
| Action | Component | Description |
| Maneuver | CE | Get the enemy’s position and accelerate towards it |
| LTF | Get the positions of the own and enemy aircraft, calculate the azimuth angle of the enemy relative to the own aircraft, and then accelerate in the direction 90° to the left of the azimuth angle | |
| RTF | Get the positions of the own and enemy aircraft, calculate the azimuth angle of the enemy relative to the own aircraft, and then accelerate in the direction 90° to the right of the azimuth angle | |
| MG | The aircraft gets the enemy’s position and flies towards it at a constant velocity. Before the launched missile opens its radar, the aircraft shares the enemy position information with the missile. Once the missile opens its radar, the aircraft no longer provides the enemy position information | |
| E | Get the position of the missile attacking the aircraft, calculate the azimuth angle of the missile relative to the aircraft, then accelerate in the direction 180° opposite to the azimuth angle while simultaneously decreasing to evade the missile attack | |
| Radar | C | Close the aircraft’s radar |
| O | Open the aircraft’s radar | |
| Missile | L | When the conditions for missile launch are met (radar has locked onto the enemy, the missile is available, the enemy is within the maximum launch angle of the missile, the enemy is within the missile attack range relative to the own aircraft), initiate missile launch to attack the enemy |
| W | Do not initiate missile launch to attack the enemy |
Fig 4
Framework of PS-PSP training"
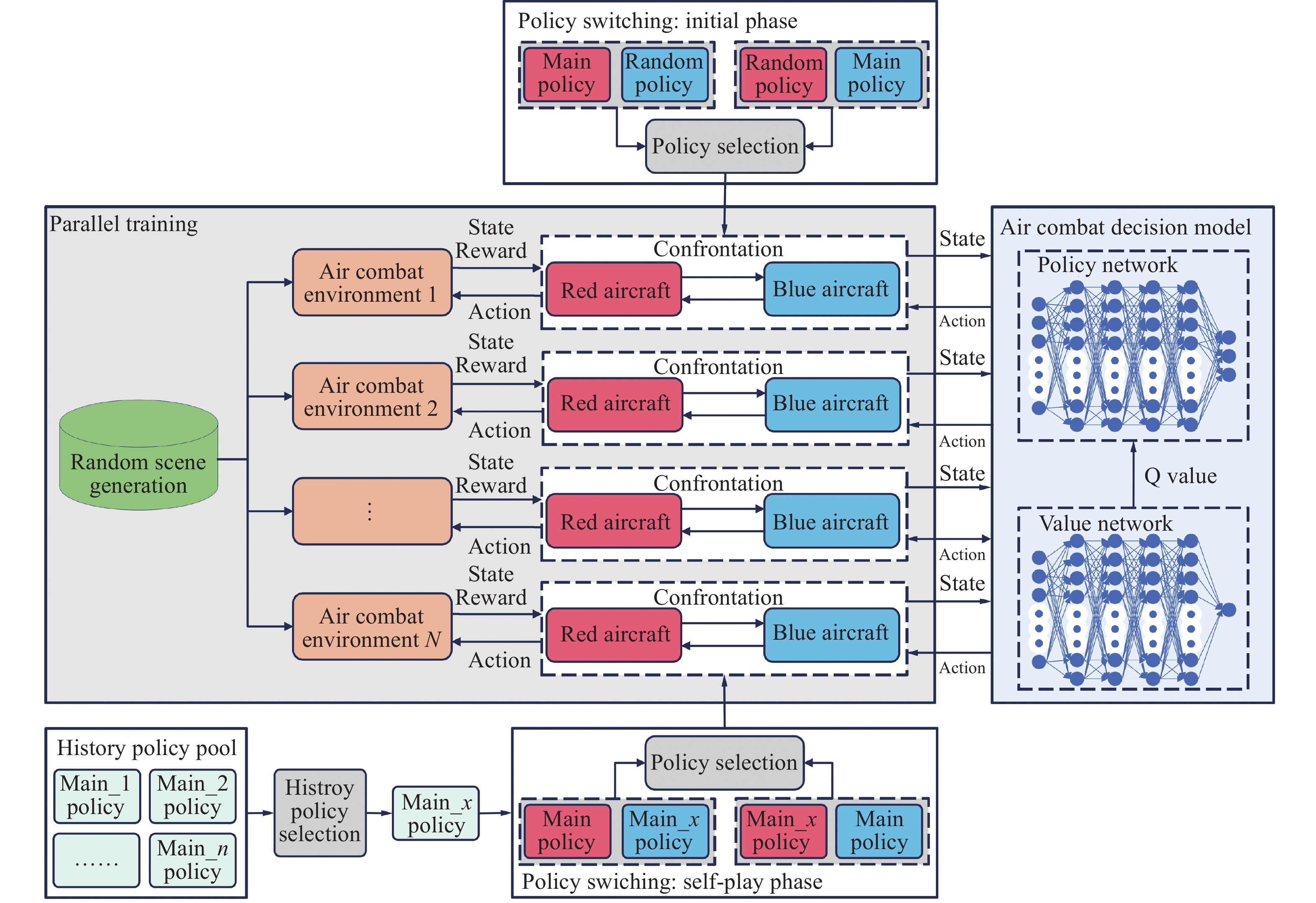
Fig 5
Diagram of training the explainable model"
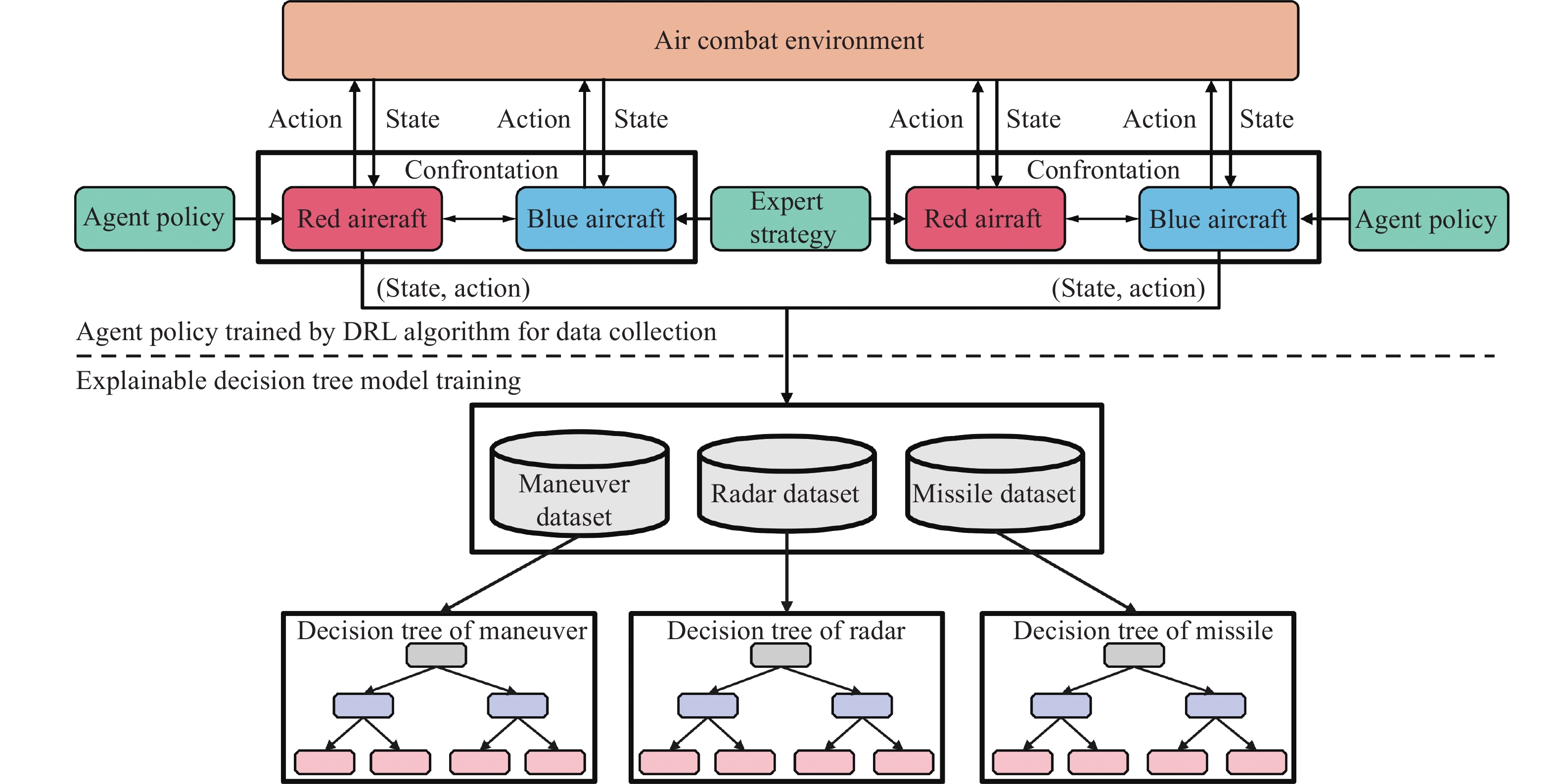
Table 2
Configuration of initial positions, velocities, and angles of all aircraft"
| Side | Initial angle/(°) | Initial velocity/(m/s) | Initial position | ||
| x-axis/m | y-axis/m | z-axis/m | |||
| Red | [0,360] | [260,290] | [− | [− | [ |
| Blue | [0,360] | [260,290] | Position is created based on the position of the red aircraft | ||
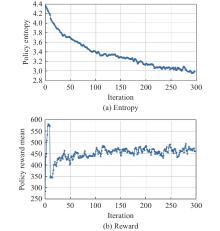
Fig 6
Entropy and reward curves in the PS-PSP training process"
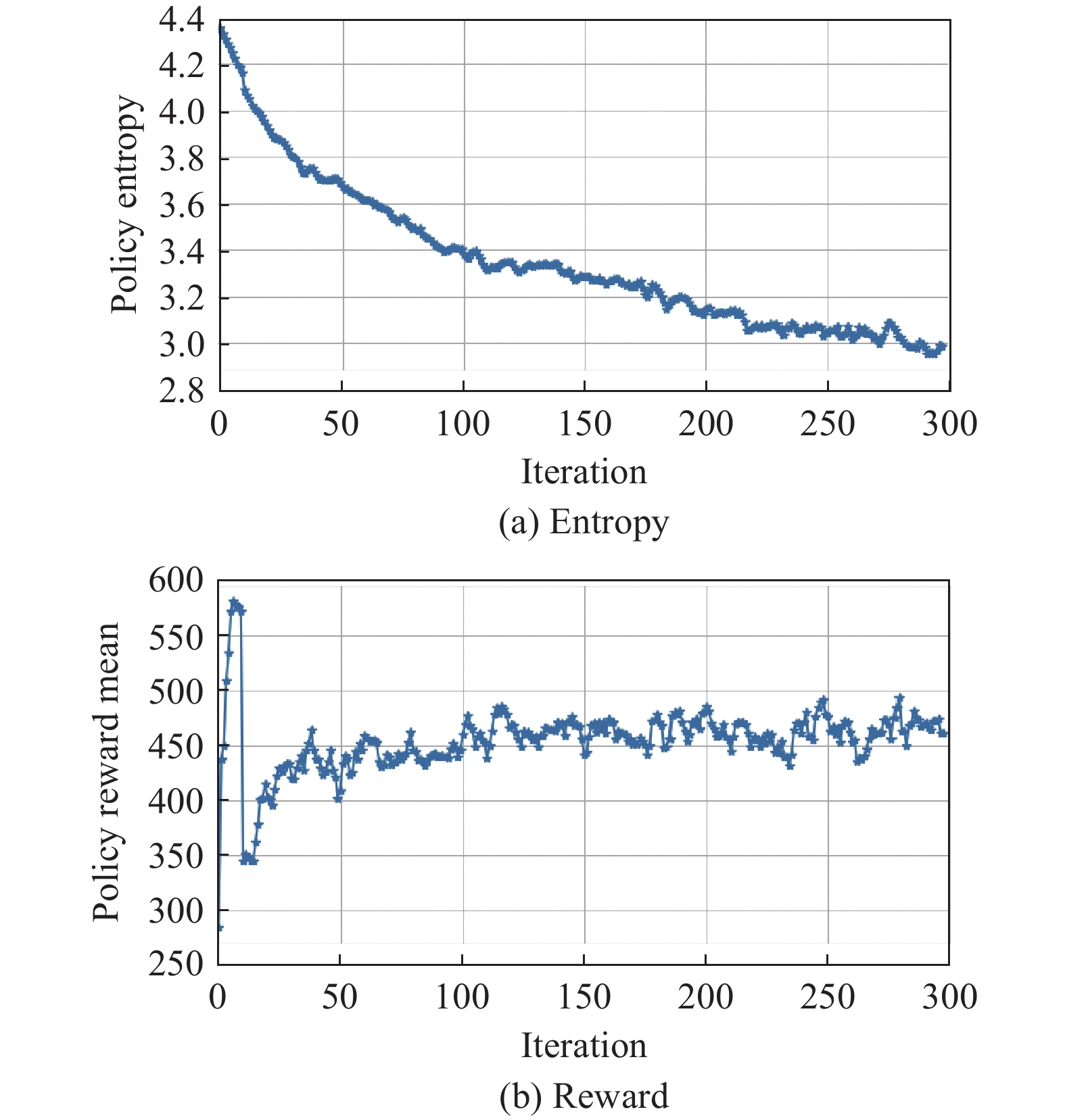

Fig 7
Score matrix of these agent policies in the form of a heatmap"
Table 3
p-value of the non-parametric Wilcoxon signed rank test for these agent policies"
| Policy | V300 | V250 | V200 | V150 | V100 | V50 | V10 |
| V300 | − | 1 | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 |
| V250 | 1 | − | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 |
| V200 | 0.016 | 0.016 | − | 0.016 | 0.016 | 0.016 | 0.016 |
| V150 | 0.016 | 0.016 | 0.016 | − | 0.016 | 0.016 | 0.016 |
| V100 | 0.016 | 0.016 | 0.016 | 0.016 | − | 0.016 | 0.016 |
| V50 | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 | − | 0.016 |
| V10 | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 | − |
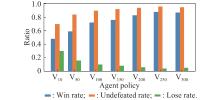
Fig 8
Results of different agent policies against an expert strategy"
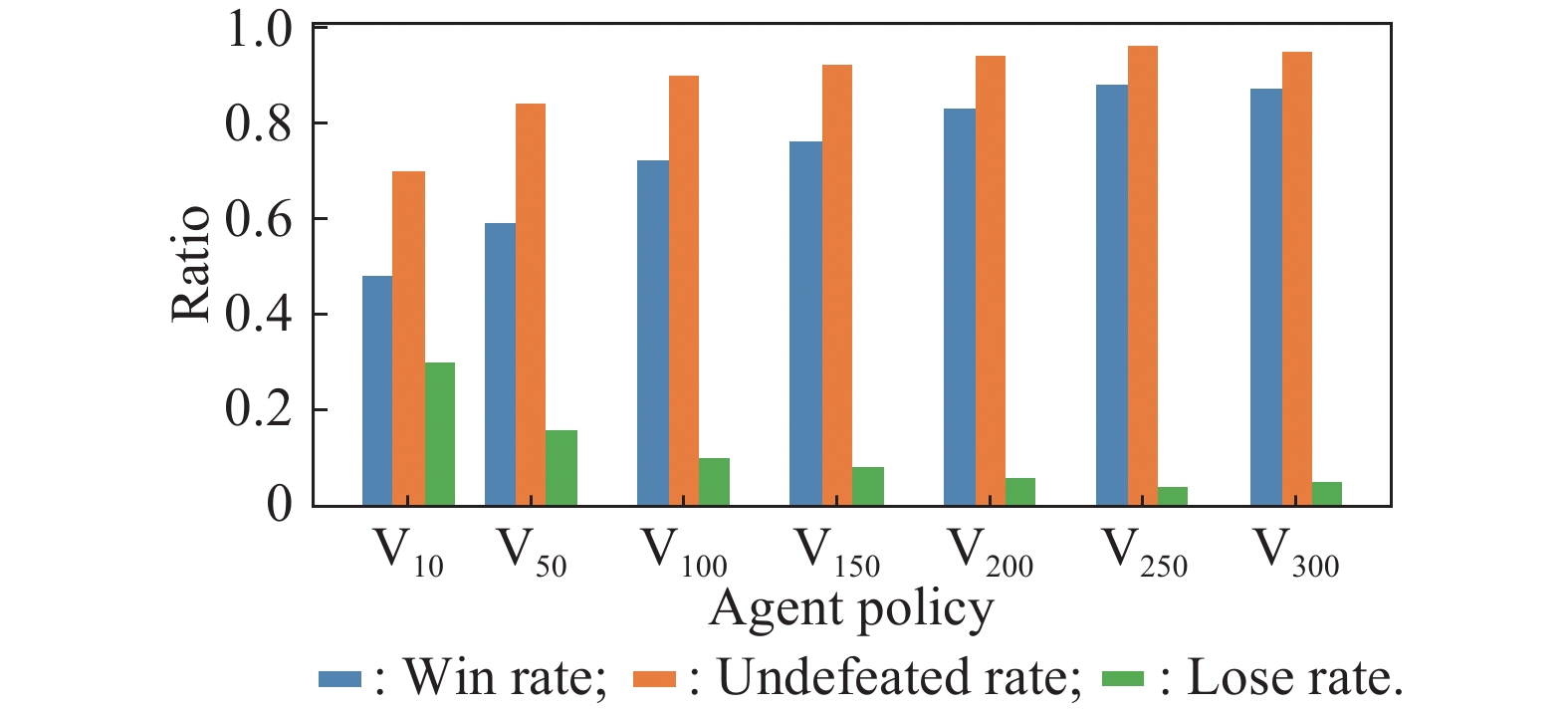
Fig 9
Adversarial processes between the agent policy V10 and the expert strategy"
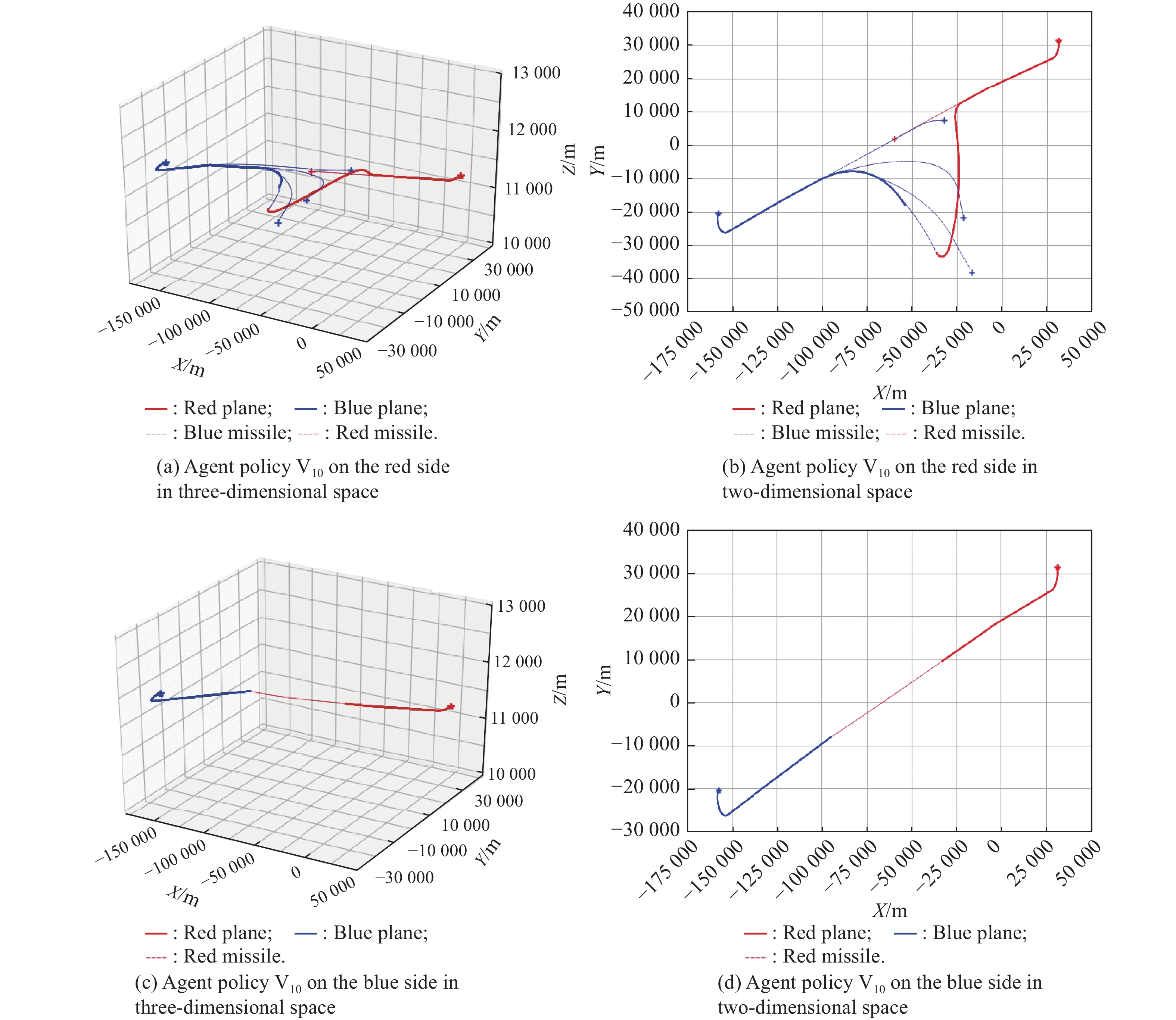

Fig 10
Adversarial processes between the agent policy V250 and the expert strategy"
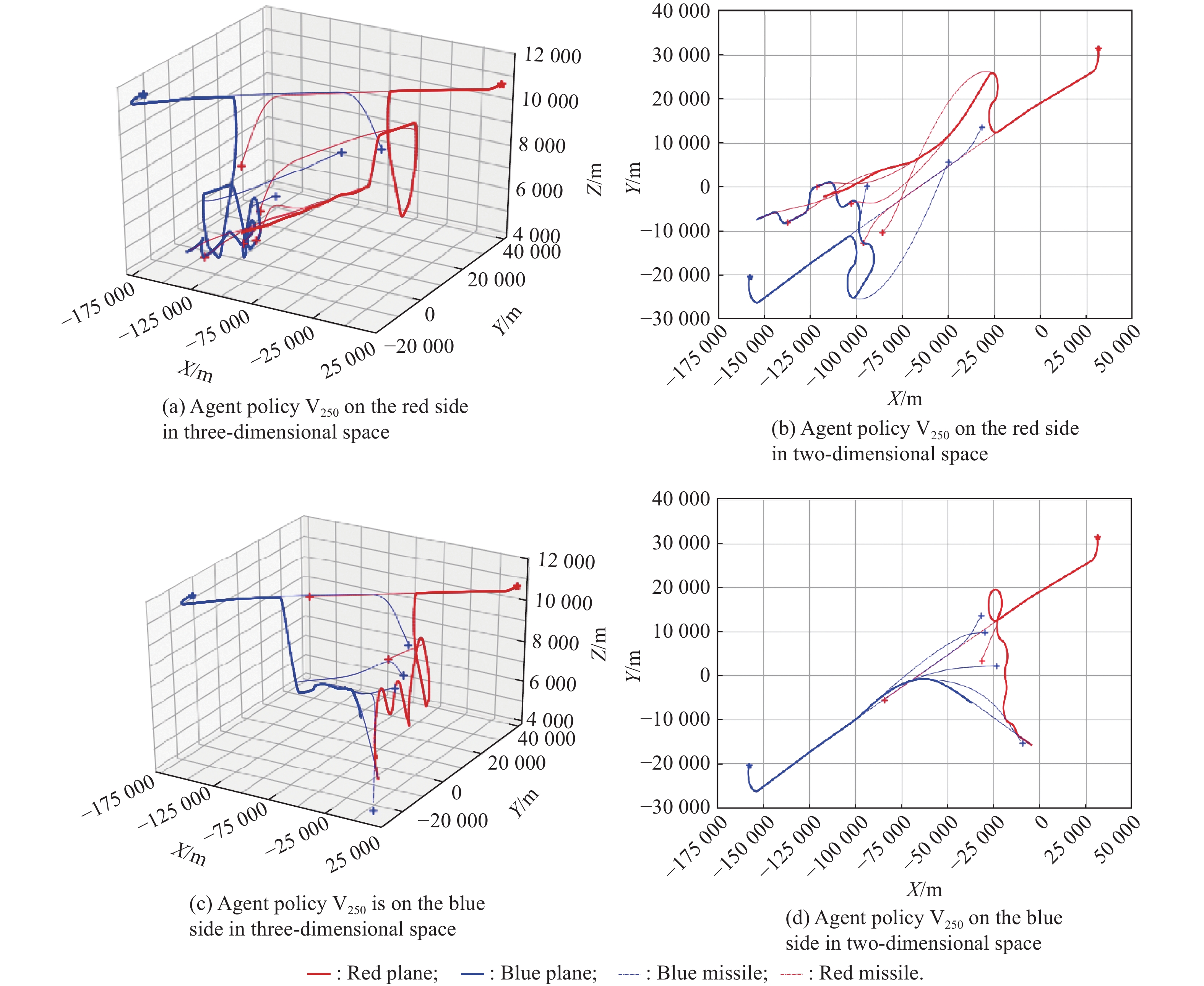
Table 4
Confrontation results of the agent policies V250 derived from both the PS-PSP and PSP training"
| Agent policy under evaluation | Policy V250 trained by PS-PSP | Policy V250 trained by PSP | Policy V250 trained by PS-PSP |
| Opponent policy | Expert strategy | Expert strategy | Policy V250 trained by PSP |
| Results (win: draw: lose) | 88:8:4 | 67:17:16 | 60:17:23 |
| Win rate of agent policy under evaluation | 88% | 67% | 60% |
| Undefeated rate of agent policy under evaluation | 96% | 84% | 77% |
| Lose rate of agent policy under evaluation | 4% | 16% | 23% |
Fig 11
Adversarial processes between the agent policies V250 trained by the PSP and PS-PSP method"
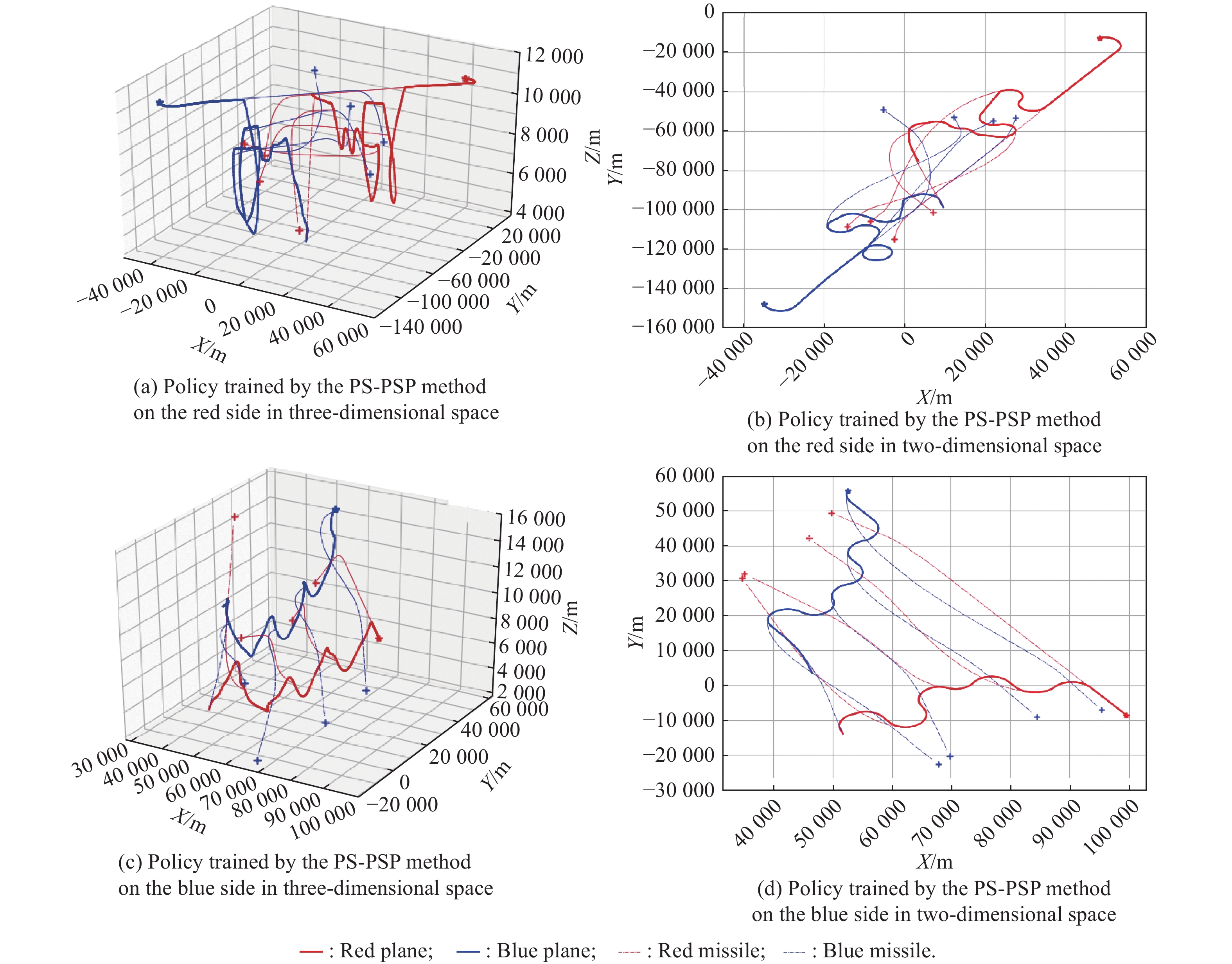

Fig 12
Entropy and reward curves for complete information and different incomplete information"
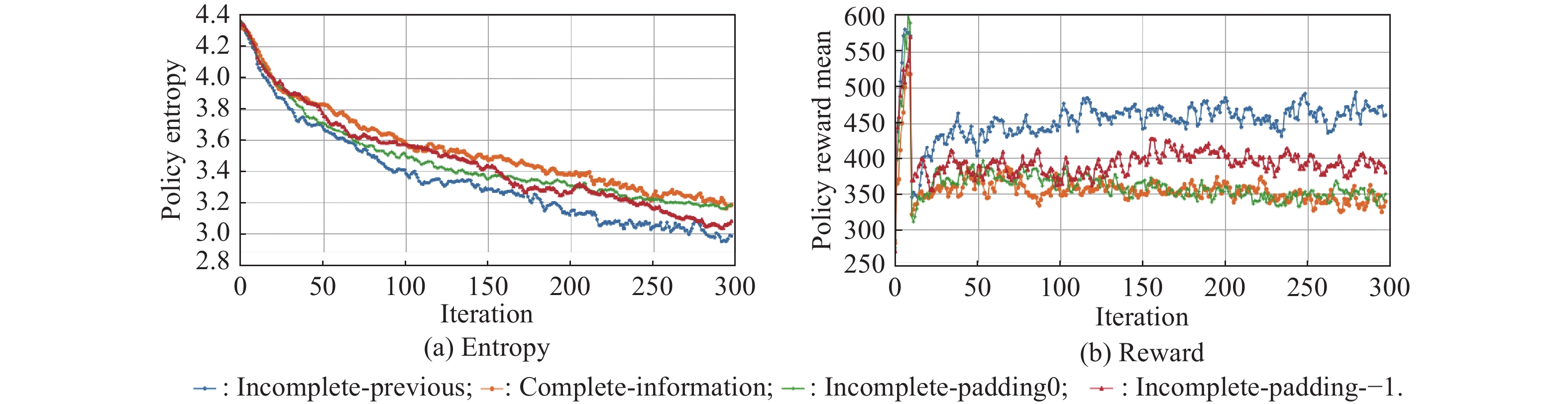
Table 5
Comparison results of the four methods"
| Experiment | Training time/s | Mean reward | Mean step in each episode | Policy V250 against the expert strategy | ||
| Win rate/% | Undefeated rate/% | Lose rate/% | ||||
| Complete information | 347.9 | 245 | 90 | 95 | 5 | |
| Incomplete information with previous data or initial state | 472.7 | 344 | 88 | 96 | 4 | |
| Incomplete information padding 0 | 350.6 | 380 | 76 | 85 | 15 | |
| Incomplete information padding −1 | 385.4 | 395 | 80 | 90 | 10 | |
Table 6
Description of features extracted and constructed from the raw dataset"
| Index | Feature name | Feature description |
| 1 | can_attack_status | Aircraft has attack capability with a value of 1; otherwise, it has a value of 0 |
| 2 | detect_radar_status | Aircraft has opened its detect radar with a value of 1; otherwise, it has a value of 0 |
| 3 | is_attacked_status | Aircraft is attacked with a value of 1; otherwise, it has a value of 0 |
| 4 | is_visible_status | Enemy aircraft is visible with a value of 1; otherwise, it has a value of 0 |
| 5 | lock_target_status | Aircraft has locked the target with a value of 1; otherwise, it has a value of 0 |
| 6 | meet_attack_condition | Attack condition is met with value 1; otherwise, it is with value 0 |
| 7 | missile_fire_status | Missile has been launched with value 1; otherwise, it is with value 0 |
| 8 | open_radar_status_missile | Enemy missile has opened its radar with 1; otherwise, it has a value of 0 |
| 9 | relative_angle_missile | Relative angle between the own aircraft and the enemy missile |
| 10 | relative_angle_plane | Relative angle between the own aircraft and the enemy aircraft |
| 11 | relative_distance_missile | Relative distance between the own aircraft and the enemy missile |
| 12 | relative_distance_plane | Relative distance between the own aircraft and the enemy aircraft |
| 13 | relative_height_missile | Relative height between the own aircraft and the enemy missile |
| 14 | relative_height_plane | Relative height between the own aircraft and the enemy aircraft |
| 15 | relative_speed_missile | Relative speed between the own aircraft and the enemy missile |
| 16 | relative_speed_plane | Relative speed between the own aircraft and the enemy aircraft |
Table 7
Detailed information about the air combat dataset"
| Label | Maneuver | Radar | Missile | ||||||||
| 0(CE) | 1(LTF) | 2(RTF) | 3(MG) | 4(E) | 0(C) | 1(O) | 0(W) | 1(L) | |||
| Win | 226 | ||||||||||
| Draw | 59 | 64 | 113 | 711 | |||||||
| Lose | 126 | 120 | 144 | ||||||||
| Sum | 411 | 1906 | |||||||||

Fig 13
Fitting accuracy of the explainable model across different tree depths on the training and testing set"
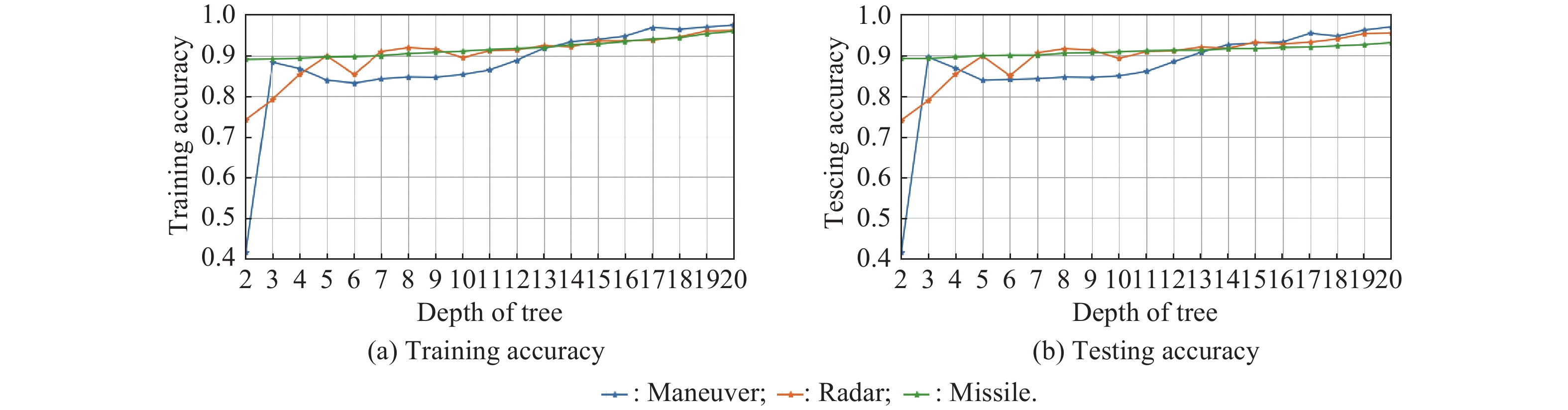
Fig 14
Visual representations of the decision tree for maneuver, radar, and missile, respectively"
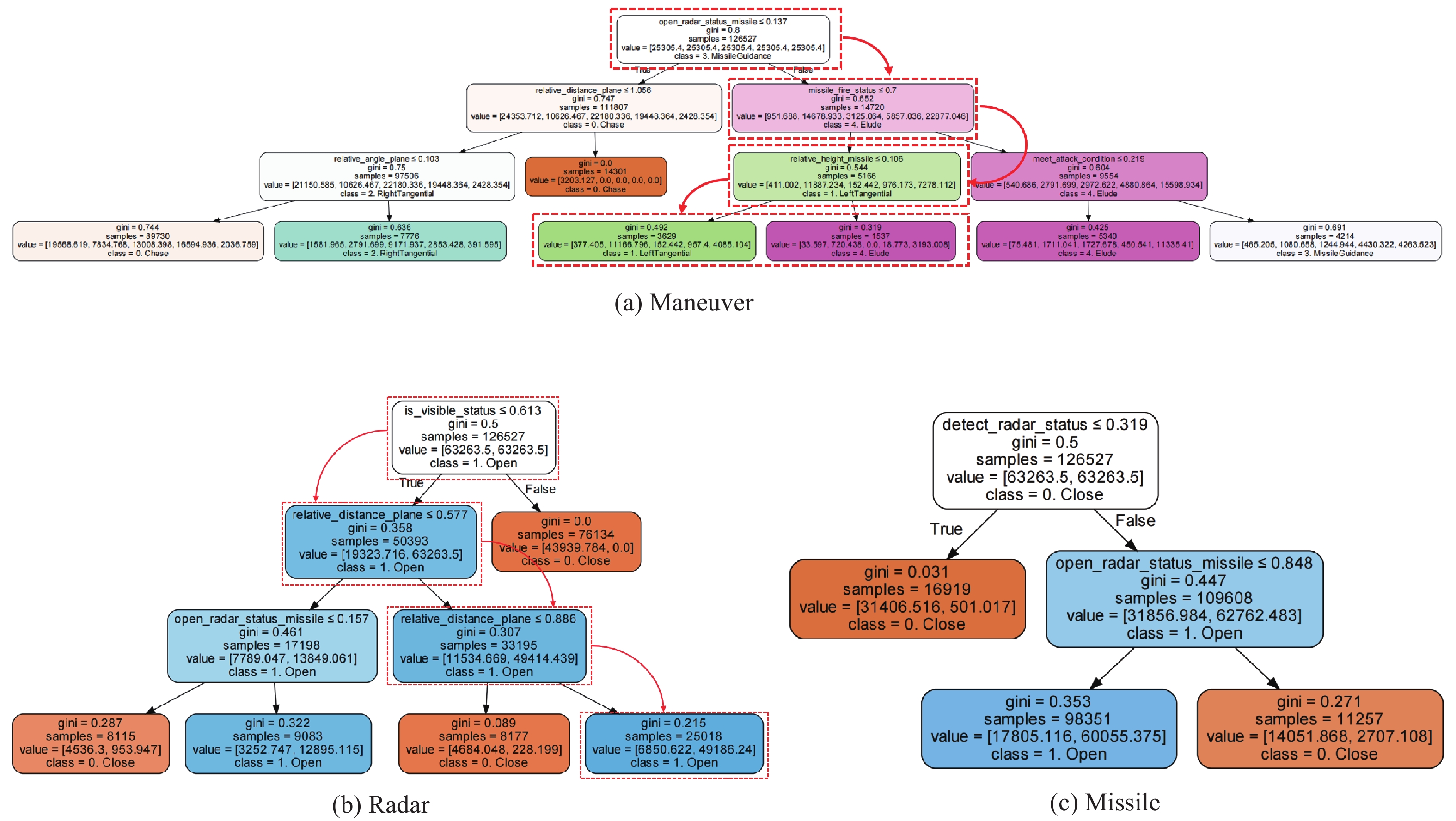
Table 8
Results of the agent policy V250 and the explainable model against the expert strategy"
| Agent policy under evaluation | Opponent policy | Results (win: draw: lose) | Win rate of agent policy under evaluation/% | Undefeated rate of agent policy under evaluation/% | Lose rate of agent policy under evaluation/% |
| Agent V250 trained by PS-PSP | Expert | 88:8:4 | 88 | 96 | 4 |
| Explainable model | Expert | 86:5:9 | 86 | 91 | 9 |
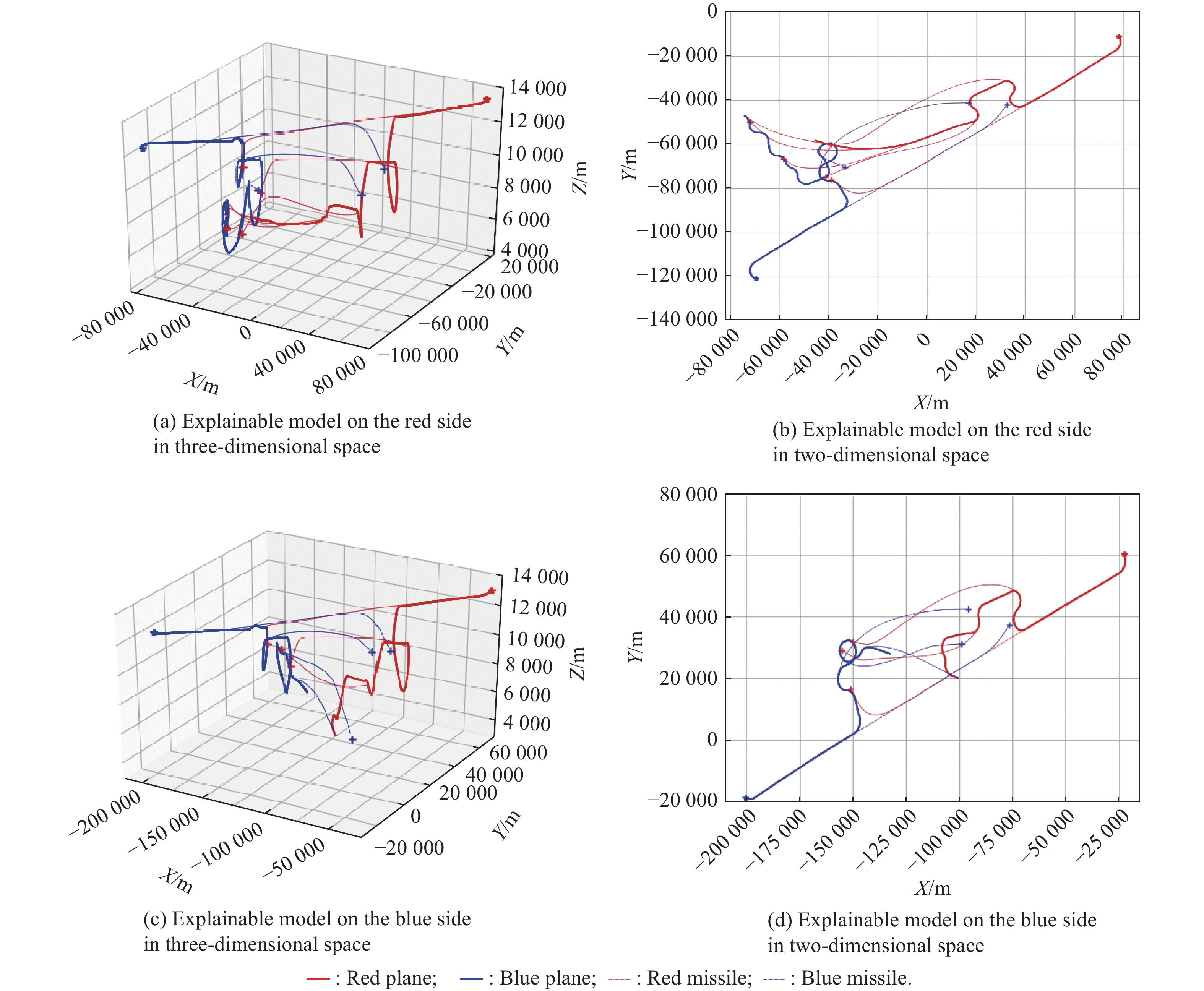
Fig 15
Adversarial process involving the agent controlled by the explainable model and the expert strategy"
| 1 |
ZHANG J D, YANG Q M, SHI G Q, et al UAV cooperative air combat maneuver decision based on multi-agent reinforcement learning. Journal of Systems Engineering and Electronics, 2021, 32 (6): 1421- 1438.
doi: 10.23919/jsee.2021.000121 |
| 2 |
ZHU J G, KUANG M C, ZHOU W Q, et al Mastering air combat game with deep reinforcement learning. Defence Technology, 2024, 34, 295- 312.
doi: 10.1016/j.dt.2023.08.019 |
| 3 |
WANG N, LI Z, LIANG X L, et al A review of deep reinforcement learning methods and military application research. Mathematical Problems in Engineering, 2023, 1, 7678382.
doi: 10.1155/2023/7678382 |
| 4 |
HU D Y, YANG R N, ZUO J L, et al Application of deep reinforcement learning in maneuver planning of beyond-visual-range air combat. IEEE Access, 2021, 9, 32282- 32297.
doi: 10.1109/ACCESS.2021.3060426 |
| 5 |
REN Z, ZHANG D, TANG S, et al Cooperative maneuver decision making for multi-UAV air combat based on incomplete information dynamic game. Defence Technology, 2023, 27, 308- 317.
doi: 10.1016/j.dt.2022.10.008 |
| 6 |
ZHANG T Y , WANG Y S, SUN M W, et al Air combat maneuver decision based on deep reinforcement learning with auxiliary reward. Neural Computing & Applications, 2024, 36 (21): 13341- 13356.
doi: 10.1007/s00521-024-09720-z |
| 7 | BULLOCK H E. ACE: the airborne combat expert systems: an exposition in two parts. Fort Belvoir: Defense Technical Information Center, 1986. (in Chinese) |
| 8 | WANG X, WANG W J, SONG K P UAV air combat decision based on evolutionary expert system tree. Ordnance Industry Automation, 2019, 38 (1): 42- 47. |
| 9 |
ISCI H, GUNEL G O Fuzzy logic based air-to-air combat algorithm for unmanned air vehicles. International Journal of Dynamics and Control, 2022, 10 (1): 230- 242.
doi: 10.1007/s40435-021-00803-6 |
| 10 |
SMITH R E, DIKE B A, MEHRA R K, et al Classifier systems in combat: two-sided learning of maneuvers for advanced fighter aircraft. Computer Methods in Applied Mechanics and Engineering, 2000, 186 (2/4): 421- 437.
doi: 10.1016/s0045-7825(99)00395-3 |
| 11 |
ERNEST N, CARROLL D, SCHUMACHER C, et al Genetic fuzzy based artificial intelligence for unmanned combat aerial vehicle control in simulated air combat missions. Journal of Defense Management, 2016, 6 (1): 114.
doi: 10.4172/2167-0374.1000144 |
| 12 |
GARCIA E, CASBEER D W, PACHTER M Active target defence differential game: fast defender case. IET Control Theory and Applications, 2017, 11 (17): 2985- 2993.
doi: 10.1049/iet-cta.2017.0302 |
| 13 |
LI S Y, CHEN M, WANG Y H, et al Air combat decision-making of multiple UCAVs based on constraint strategy games. Defence Technology, 2022, 18 (3): 368- 383.
doi: 10.1016/j.dt.2021.01.005 |
| 14 |
LI S Y, CHEN M, WANG Y H, et al A fast algorithm to solve large-scale matrix games based on dimensionality reduction and its application in multiple unmanned combat air vehicles attack-defense decision-making. Information Sciences, 2022, 594, 305- 321.
doi: 10.1016/j.ins.2022.02.025 |
| 15 |
LIU R Z, GUO H F, JI X Z, et al Efficient reinforcement learning for StartCraft by abstract forward models and transfer learning. IEEE Trans. on Games, 2022, 14 (2): 294- 307.
doi: 10.1109/TG.2021.3071162 |
| 16 |
LUO Q, TAN T P RARSMSDou: master the game of DouDiZhu with deep reinforcement learning algorithms. IEEE Trans. on Emerging Topics in Computational Intelligence, 2024, 8 (1): 427- 439.
doi: 10.1109/TETCI.2023.3303251 |
| 17 |
DIMITRIU A, MICHALETZKY T V, REMELI V, et al A reinforcement learning approach to military simulations in Command: modern operations. IEEE Access, 2024, 12, 77501- 77513.
doi: 10.1109/ACCESS.2024.3406148 |
| 18 |
SUN Y, YUAN B, ZHANG T, et al Research and implementation of intelligent decision based on a priori knowledge and DQN algorithms in wargame environment. Electronics, 2020, 9 (10): 1668.
doi: 10.3390/electronics9101668 |
| 19 | TANG B J, SUN Y X, YU J H, et al. Parallel intelligent command decision-making technology based on combat prior knowledge and reinforcement learning algorithm. Proc. of the International Conference on Cyber-Physical Social Intelligence, 2021. DOI: 10.1109/ICCSI53130.2021.9736221. |
| 20 | SHI W, FENG Y H, CHENG G Q, et al Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47 (7): 1610- 1623. |
| 21 |
SUN Y X, YUAN B, XIANG Q, et al Intelligent decision-making and human language communication based on deep reinforcement learning in a wargame environment. IEEE Trans. on Human-Machine Systems, 2023, 53 (1): 201- 214.
doi: 10.1109/THMS.2022.3225867 |
| 22 | ZHANG Q, YANG R N, YU L X, et al BVR air combat maneuvering decision by using Q-network reinforcement learning. Journal of Air Force Engineering University (Natural Science Edition), 2018, 19 (6): 8- 14. |
| 23 |
CAO Y, KOU Y X, LI Z W, et al Autonomous maneuver decision of UCAV air combat based on double deep Q network algorithm and stochastic game theory. International Journal of Aerospace Engineering, 2023, 2023 (1): 3657814.
doi: 10.1155/2023/3657814 |
| 24 | WANG Y, ZHANG X W, ZHOU R, et al Research on UCAV maneuvering decision method based on heuristic reinforcement learning. Computational Intelligence and Neuroscience, 2022, 2022 (1): 1477078. |
| 25 | DING W, WANG Y, DING D L, et al Maneuvering decision of UCAV in close air combat based on LSTMPPO algorithm. Journal of Air Force Engineering University (Natural Science Edition), 2022, 23 (3): 19- 25. |
| 26 | POPE A P, IDE J S, MICOVIC D, et al. Hierarchical reinforcement learning for air combat at DARPA’s AlphaDogfight trials. IEEE Trans. on Artificial Intelligence, 2023, 4(6): 1371−1385. |
| 27 |
FAN Z H, XU Y, KANG Y H, et al Air combat maneuver decision method based on A3C deep reinforcement learning. Machines, 2022, 10 (11): 1033.
doi: 10.3390/machines10111033 |
| 28 |
BAI S X, SONG S M, LIANG S Y, et al UAV maneuvering decision-making algorithm based on twin delayed deep deterministic policy gradient algorithm. Journal of Artificial Intelligence and Technology, 2022, 2 (1): 16- 22.
doi: 10.37965/jait.2021.12003 |
| 29 |
SUN Z X, PIAO H Y, YANG Z, et al Multi-agent hierarchical policy gradient for air combat tactics emergence via self-play. Engineering Applications of Artificial Intelligence, 2021, 98, 104112.
doi: 10.1016/j.engappai.2020.104112 |
| 30 |
HU J W, WANG L H, HU T M, et al Autonomous maneuver decision making of dual-UAV cooperative air combat based on deep reinforcement learning. Electronics, 2022, 11 (3): 467.
doi: 10.3390/electronics11030467 |
| 31 | LIU X, LIU S Y, ZHUANG Y K, et al Explainable reinforcement learning: basic problems exploration and method survey. Journal of Software, 2023, 34 (5): 2300- 2316. |
| 32 | DING L F, GENG F L. Principle of radar. 3rd ed. Xi’an: Xidian University Press, 2014. (in Chinese) |
| 33 |
ZHANG H, WEI Y, ZHOU H, et al Maneuver decision-making for autonomous air combat based on FRE-PPO. Applied Sciences, 2022, 12 (20): 10230.
doi: 10.3390/app122010230 |
| 34 | AUSTIN F, CARBONNE G, FALCO M, et al. Automated maneuvering decisions for air-to-air combat. Guidance, Navigation and Control Conference, 1987: 2393. |
| 35 | XIAO B S, FANG Y W, HU S G, et al New threat assessment method in beyond-the-horizon range air combat. Systems Engineering and Electronics, 2009, 31 (9): 2163- 2166. |
| 36 |
LI B, HUANG J Y, BAI S X, et al Autonomous air combat decision-making of UAV based on parallel self-play reinforcement learning. CAAI Transactions on Intelligence Technology, 2023, 8 (1): 64- 81.
doi: 10.1049/cit2.12109 |
| 37 | RODRIGUEZ-FDEZ I, CANOSA A, MUCIENTES M, et al. STAC: a web platform for the comparison of algorithms using statistical tests. Proc. of the IEEE International Conference on Fuzzy Systems, 2015. DOI: 10.1109/FUZZ-IEEE.2015.7337889. |
| 38 |
PENG L X, ZHOU X Z, ZHAO J J, et al Three-way multi-attribute decision making under incomplete mixed environments using probabilistic similarity. Information Sciences, 2022, 614, 432- 463.
doi: 10.1016/j.ins.2022.10.038 |
| 39 |
BAE J H, JUNG H, KIM S, et al Deep reinforcement learning-based air-to-air combat maneuver generation in a realistic environment. IEEE Access, 2023, 11, 26427- 26440.
doi: 10.1109/ACCESS.2023.3257849 |
| 40 |
WANG H, WANG J T Enhancing multi-UAV air combat decision making via hierarchical reinforcement learning. Scientific Reports, 2024, 14 (1): 4458.
doi: 10.1038/s41598-024-54938-5 |
| 41 | JIANG S, WANG W, HUANG S B. Deep Q-network based target search of UAV under partially observable conditions. Proc. of the IEEE International Conference on Sensors, Electronics and Computer Engineering, 2023: 71−75. |
| [1] | Nanxun DUO, Qinzhao WANG, Qiang LYU, Wei WANG. Tactical reward shaping for large-scale combat by multi-agent reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1516-1529. |
| [2] | Guofei LI, Shituo LI, Bohao LI, Yunjie WU. Deep reinforcement learning guidance with impact time control [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1594-1603. |
| [3] | Guang ZHAN, Kun ZHANG, Ke LI, Haiyin PIAO. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience [J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 644-665. |
| [4] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [5] | Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224. |
| [6] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [7] | Ang GAO, Qisheng GUO, Zhiming DONG, Zaijiang TANG, Ziwei ZHANG, Qiqi FENG. Research on virtual entity decision model for LVC tactical confrontation of army units [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1249-1267. |
| [8] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [9] | Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments [J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||