
Journal of Systems Engineering and Electronics ›› 2024, Vol. 35 ›› Issue (3): 644-665.doi: 10.23919/JSEE.2024.000022
• SYSTEMS ENGINEERING • Previous Articles
Guang ZHAN1( ), Kun ZHANG1,2,*(), Ke LI1(), Haiyin PIAO1()
), Kun ZHANG1,2,*(), Ke LI1(), Haiyin PIAO1()
Received:2022-06-14
Online:2024-06-18
Published:2024-06-19
Contact:
Kun ZHANG
E-mail:zhanguang@mail.nwpu.edu.cn;kunzhang@nwpu.edu.cn;keli_iat@mail.nwpu.edu.cn;haiyinpiao@mail.nwpu.edu.cn
About author:Supported by:Guang ZHAN, Kun ZHANG, Ke LI, Haiyin PIAO. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience[J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 644-665.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
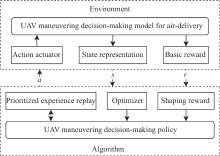
Fig 1
Structure of UAV maneuvering decision-making for air-delivery based on DRL"
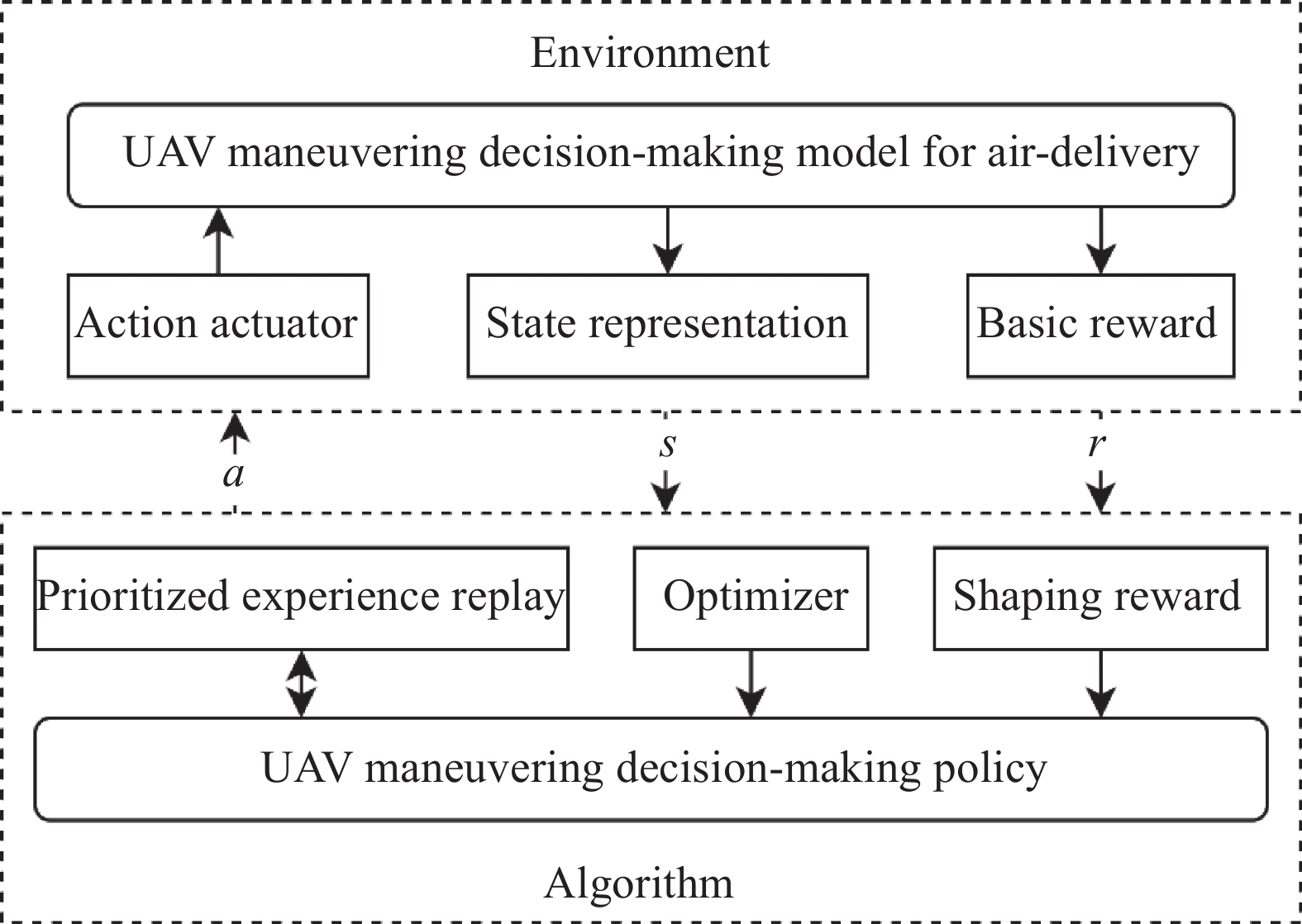
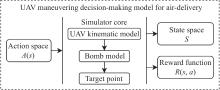
Fig 2
Construction diagram of UAV maneuvering decision-making model for air-delivery based on MDPs"
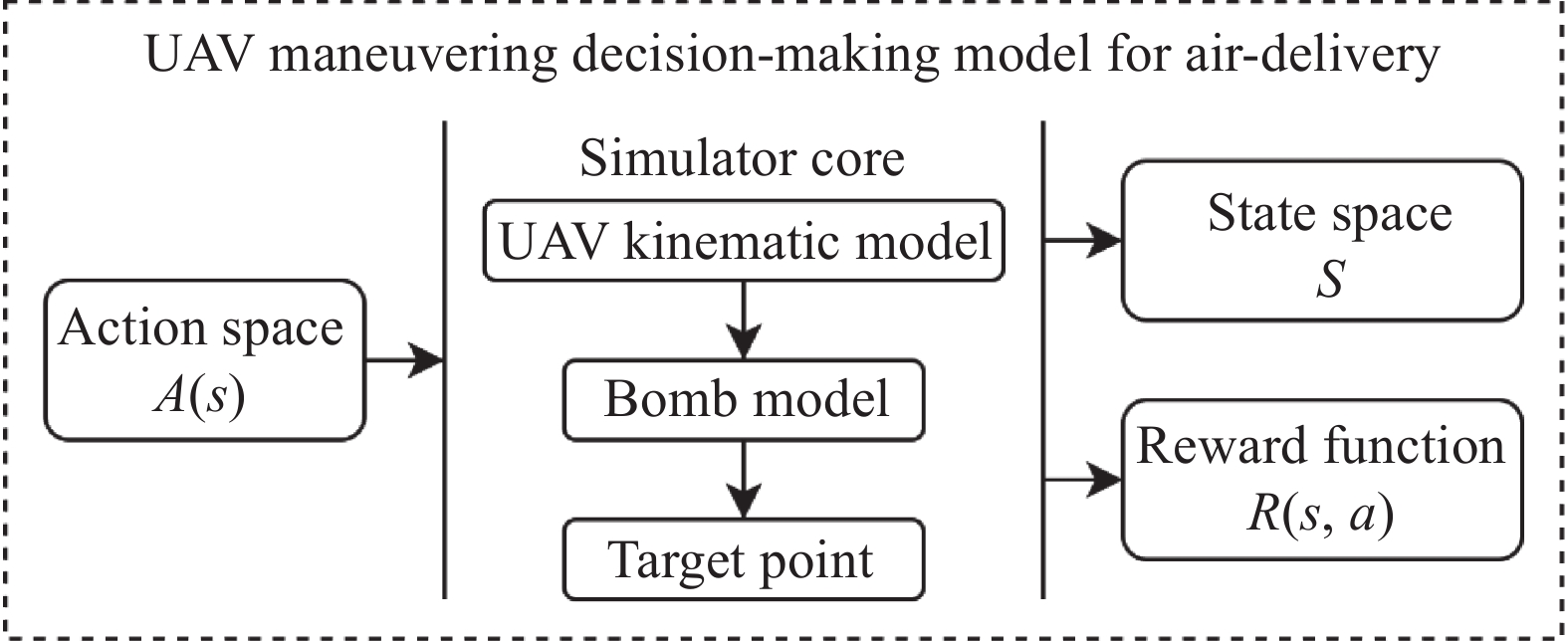
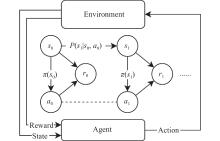
Fig 3
Structure of finite MDPs and traditional scheme of solving MDPs"
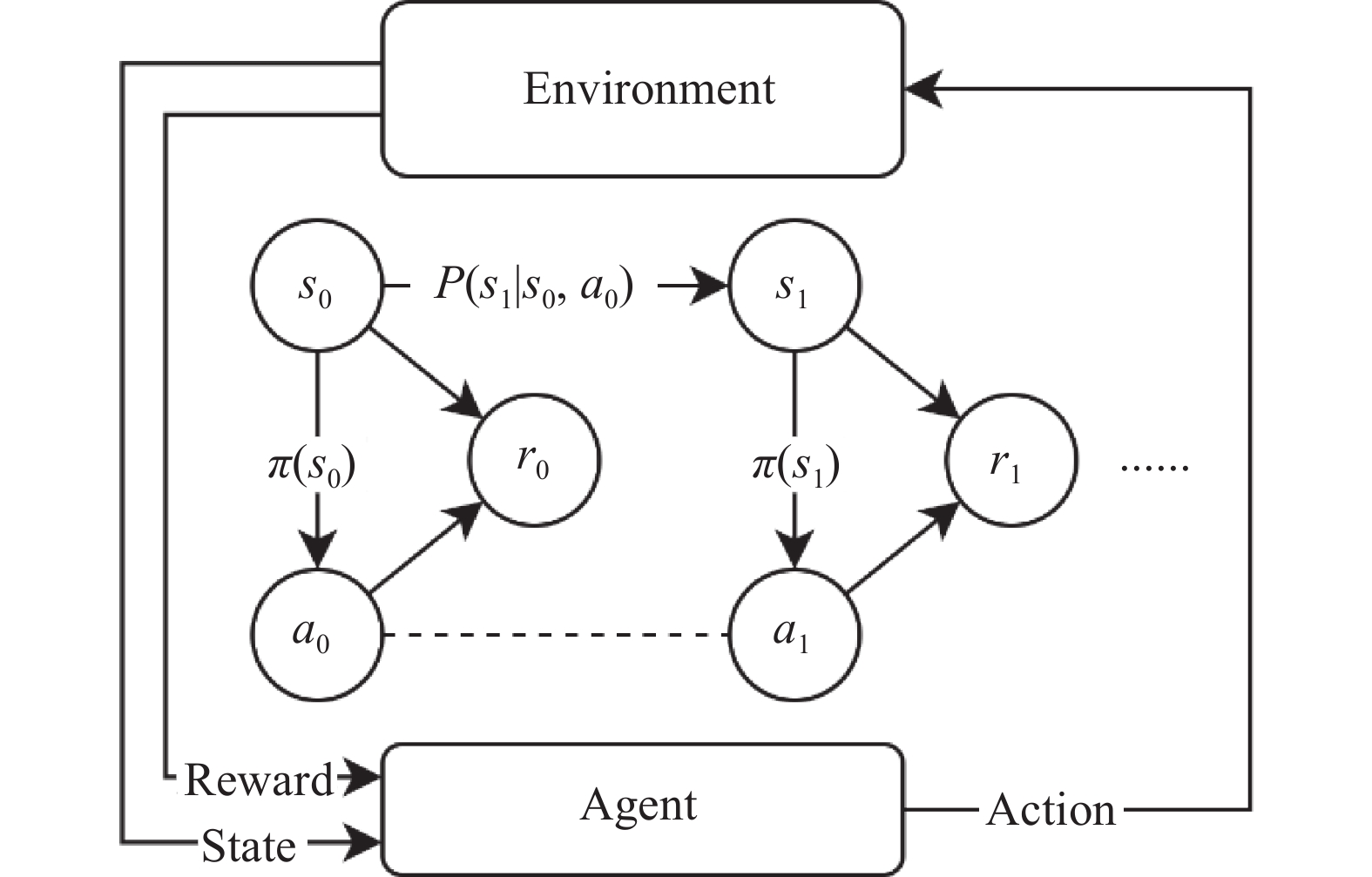
Fig 4
Diagram of guidance towards area task involved in air-delivery mission"
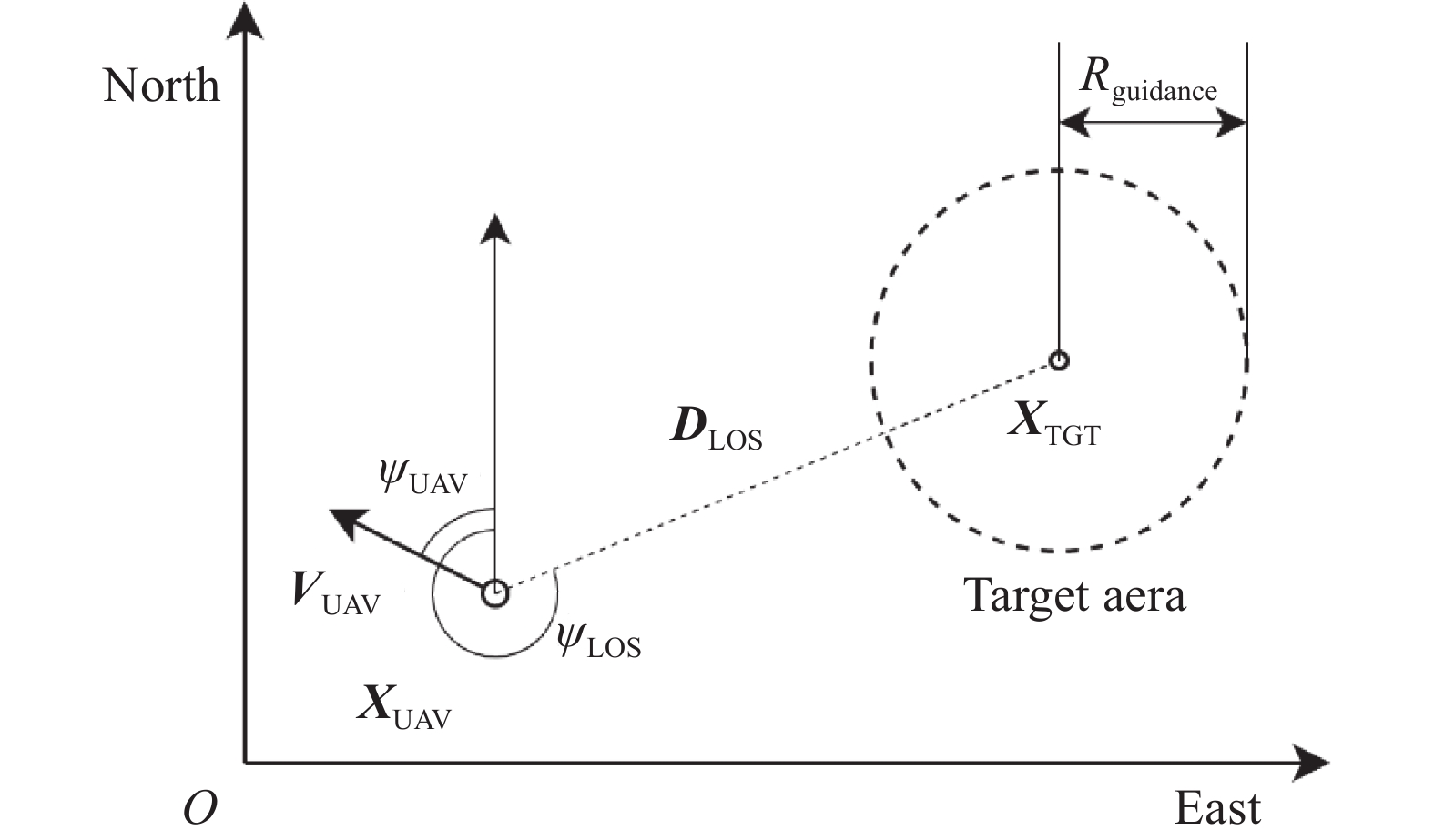

Fig 5
Diagram of guidance towards specific point task involved in air-delivery mission"
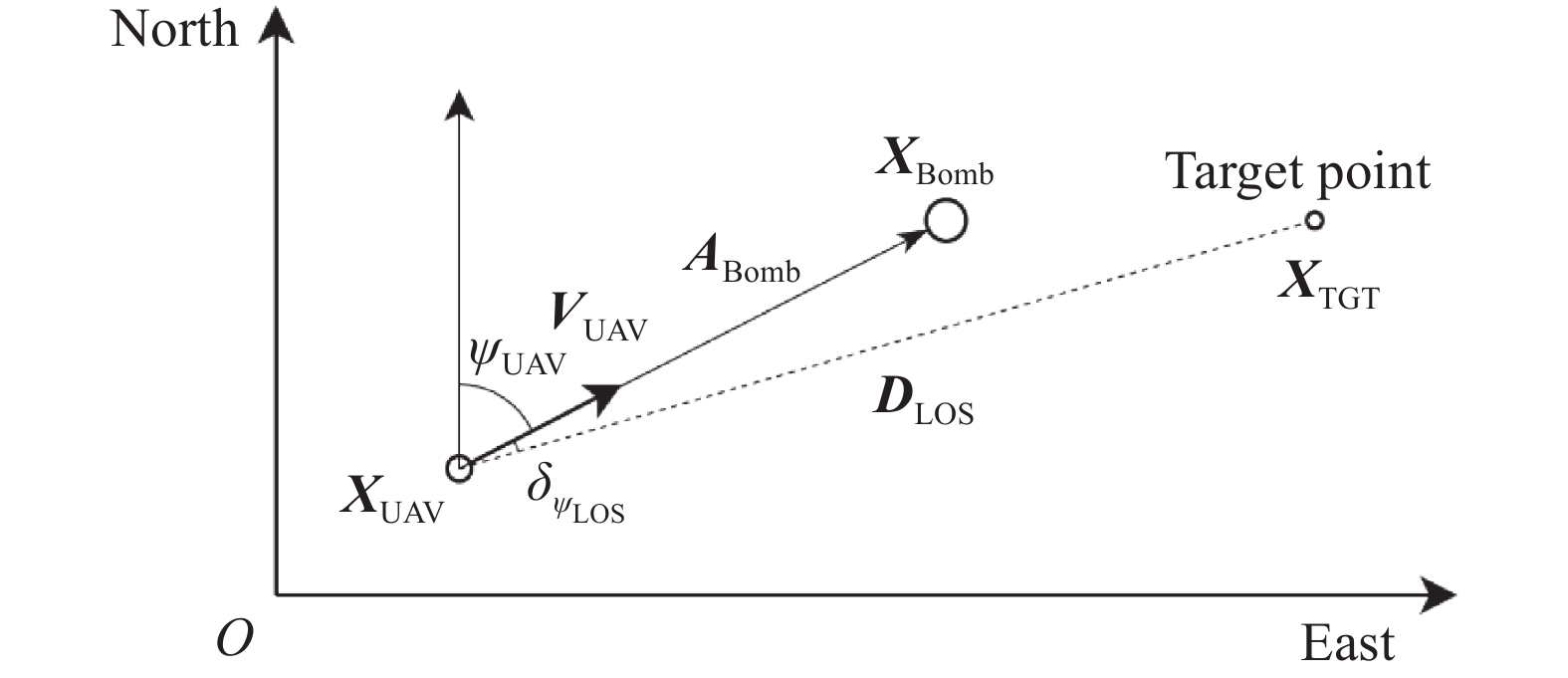
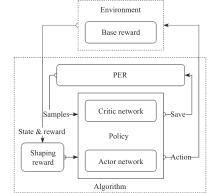
Fig 6
Running process of UAV maneuvering decision-making algorithm for air-delivery"

Fig 7
Diagram of PER-DDPG’s framework"
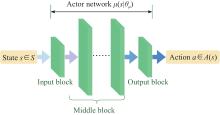
Fig 8
Structure of actor network"
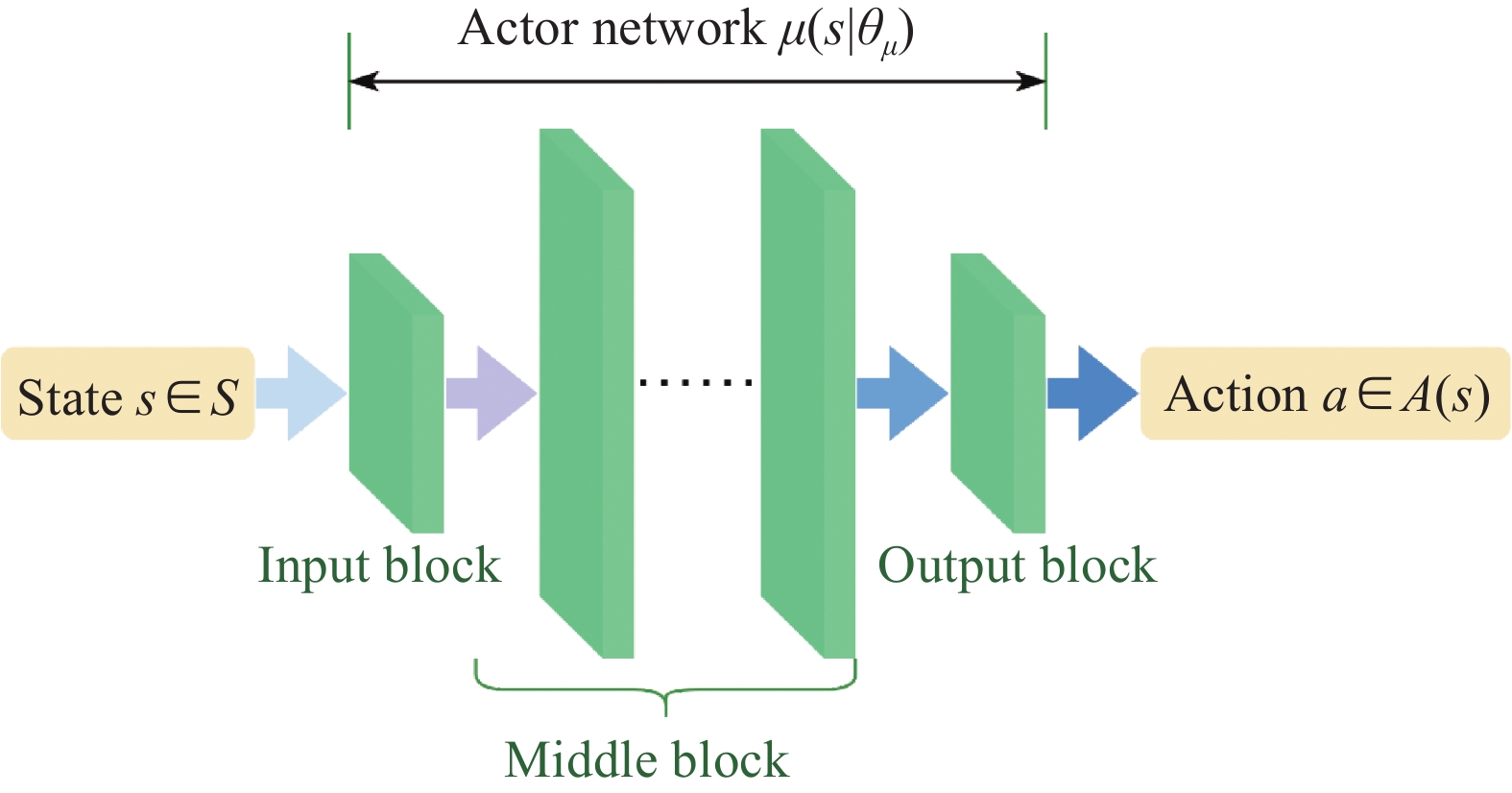
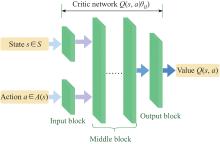
Fig 9
Structure of critic network"
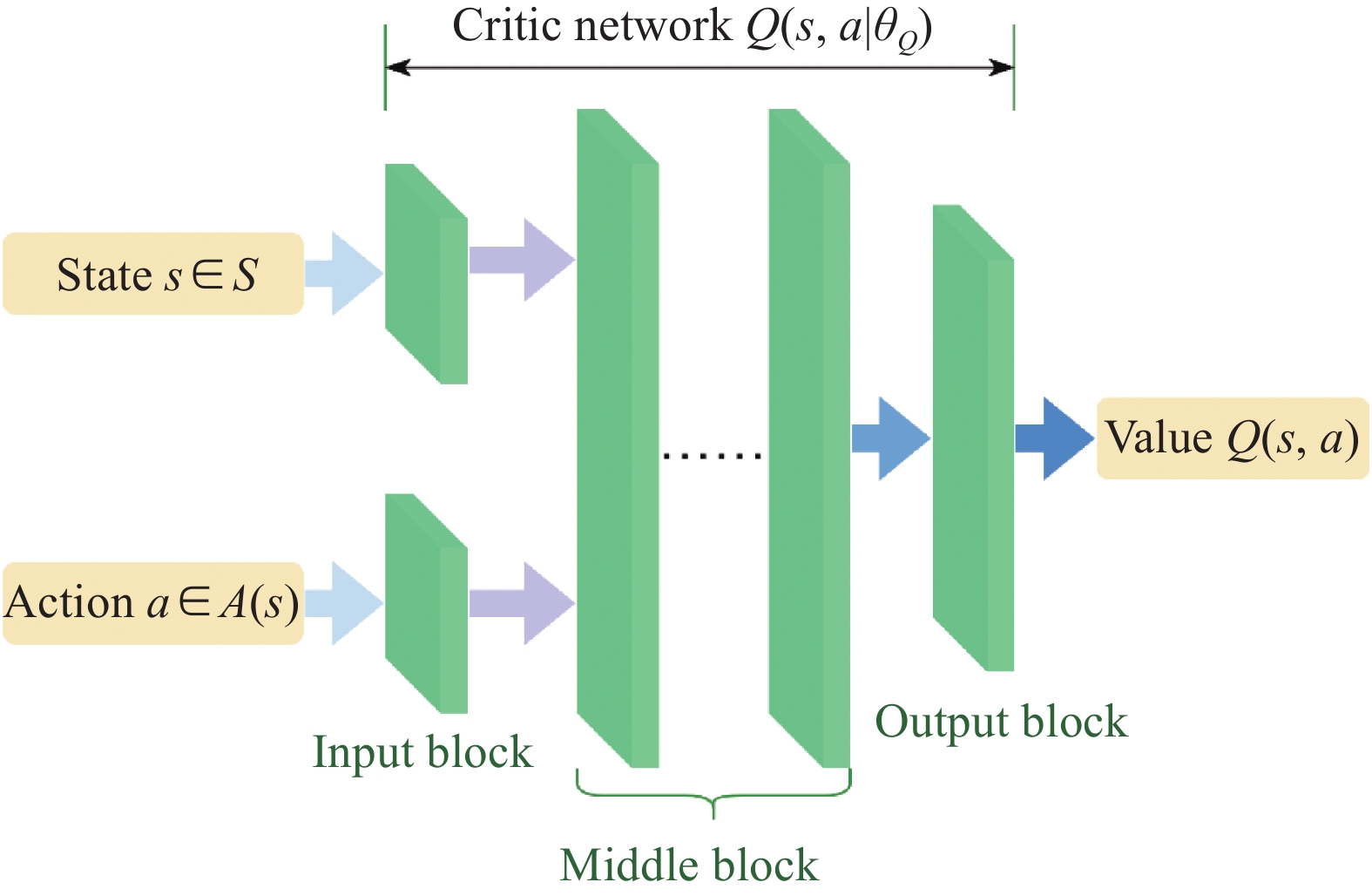
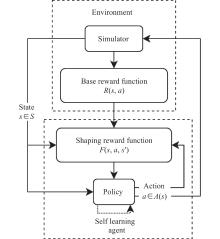
Fig 10
Construction diagram of UAV maneuvering decision-making model for air-delivery"
Table 1
Details of parameters involved in environment"
| Parameter | Range | Meaning |
| Distance between UAV and target point | ||
| Relative azimuth between LOS and the nose direction of UAV | ||
| UAV speed | ||
| UAV height | ||
| Horizontal range of bomb | ||
| Steering overload of UAV |
Table 2
Parameters assignment of algorithm for the guidance towards area task"
| Parameter | Value | Meaning |
| 100 | Policy’s learning period | |
| 100000 | Historical buffer capacity | |
| 0.01 | Soft updating parameter | |
| 128 | Size of minibatch | |
| 0.001 | Actor networks’ learning rate | |
| 0.001 | Critic networks’ learning rate | |
| 0.5 | Availability exponent of PER | |
| 0.4 | Initial IS exponent | |
| 1000 | Maximum training episodes | |
| 5000 | Maximum steps per episode |
Table 3
Structure of critic network ${\boldsymbol{Q}}\left( {{\boldsymbol{s}},{\boldsymbol{a}}|{{\boldsymbol{\theta}} _{\boldsymbol{Q}}}} \right)$ for the guidance towards area task"
| Layer name | Layer structure | |
| Unit | Activation function | |
| Input layer of state | 16 | ReLU |
| Input layer of action | 16 | ReLU |
| Hidden layer 1 | 32 | ReLU |
| Hidden layer 2 | 64 | ReLU |
| Hidden layer 3 | 32 | ReLU |
| Output layer | 1 | None |
Table 4
Structure of actor network ${\boldsymbol{\mu}} \left( {{\boldsymbol{s}}|{{\boldsymbol{\theta}} _{\boldsymbol{\mu}} }} \right)$ for the guidance towards area task"
| Layer name | Layer structure | |
| Unit | Activation function | |
| Input layer | 16 | Tanh |
| Hidden layer 1 | 32 | Tanh |
| Hidden layer 2 | 64 | Tanh |
| Hidden layer 3 | 32 | Tanh |
| Output layer | 1 | Tanh |
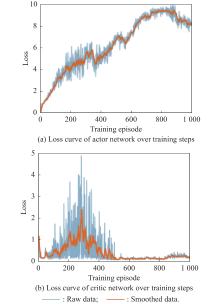
Fig 11
Loss curves of actor network and critic network over training steps under the setting of UER-DDPG and RS without advice in the guidance towards area task"

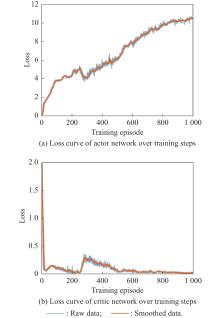
Fig 12
Loss curves of actor network and critic network over training steps under the setting of PER-DDPG and RS without advice in the guidance towards area task"
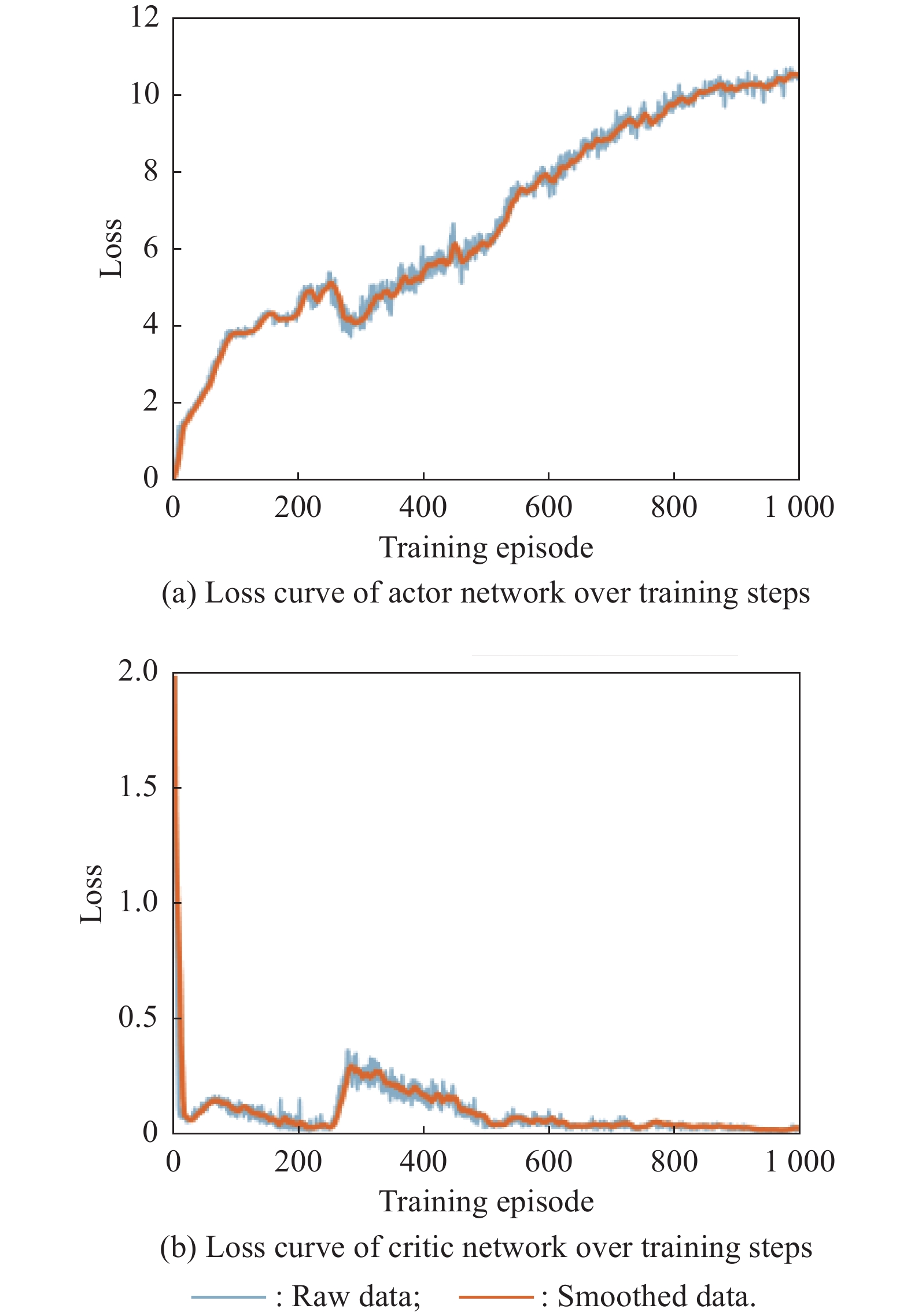
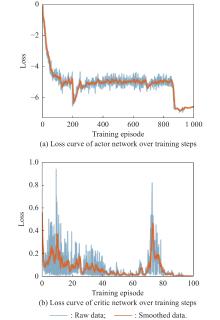
Fig 13
Loss curves of actor network and critic network over training steps under the setting of UER-DDPG and RS with advice in the guidance towards area task"
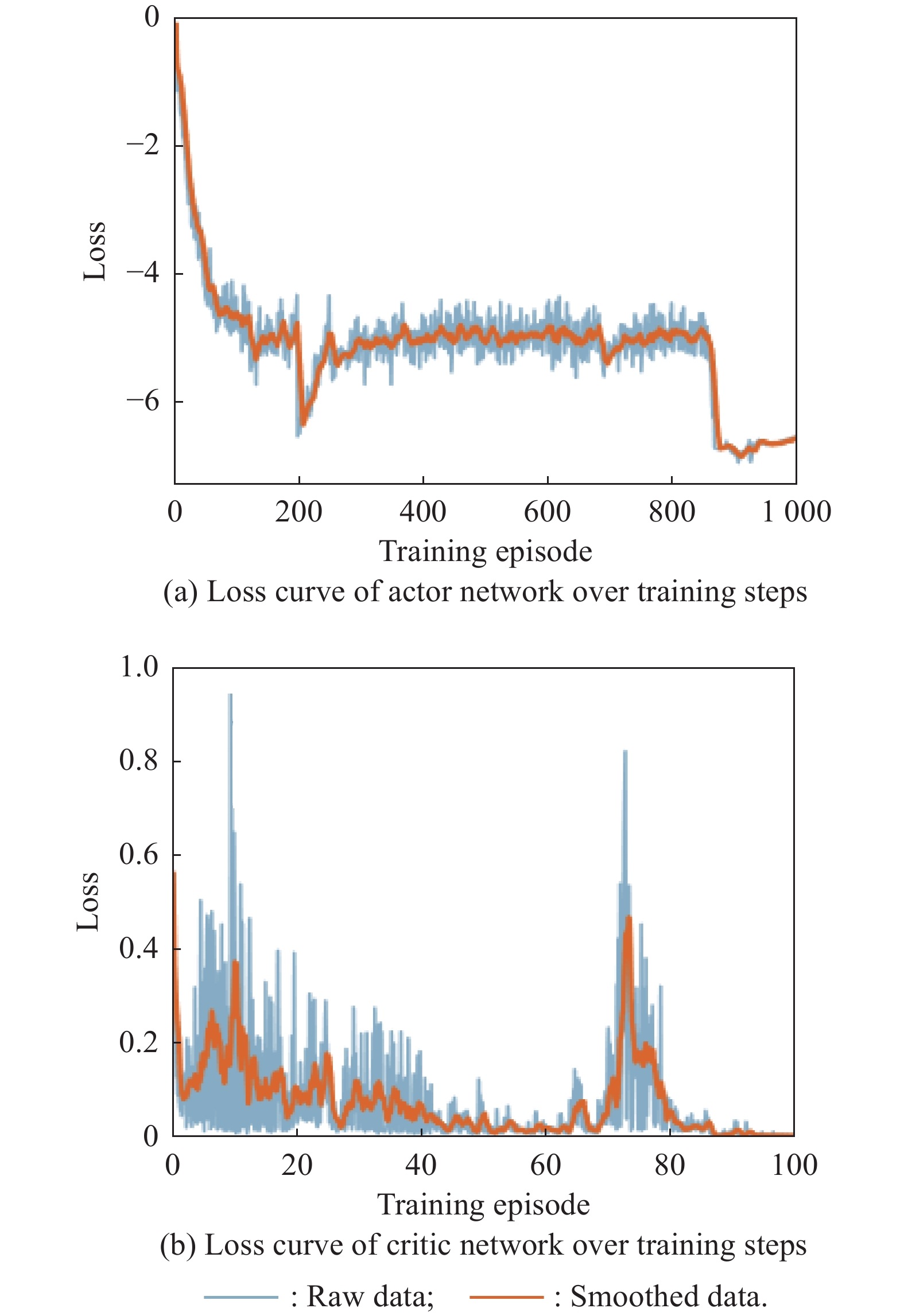
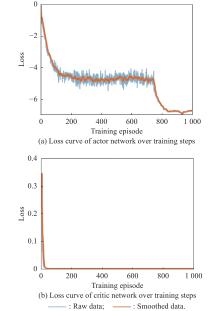
Fig 14
Loss curves of actor network and critic network over training steps under the setting of PER-DDPG and RS with advice in the guidance towards area task"
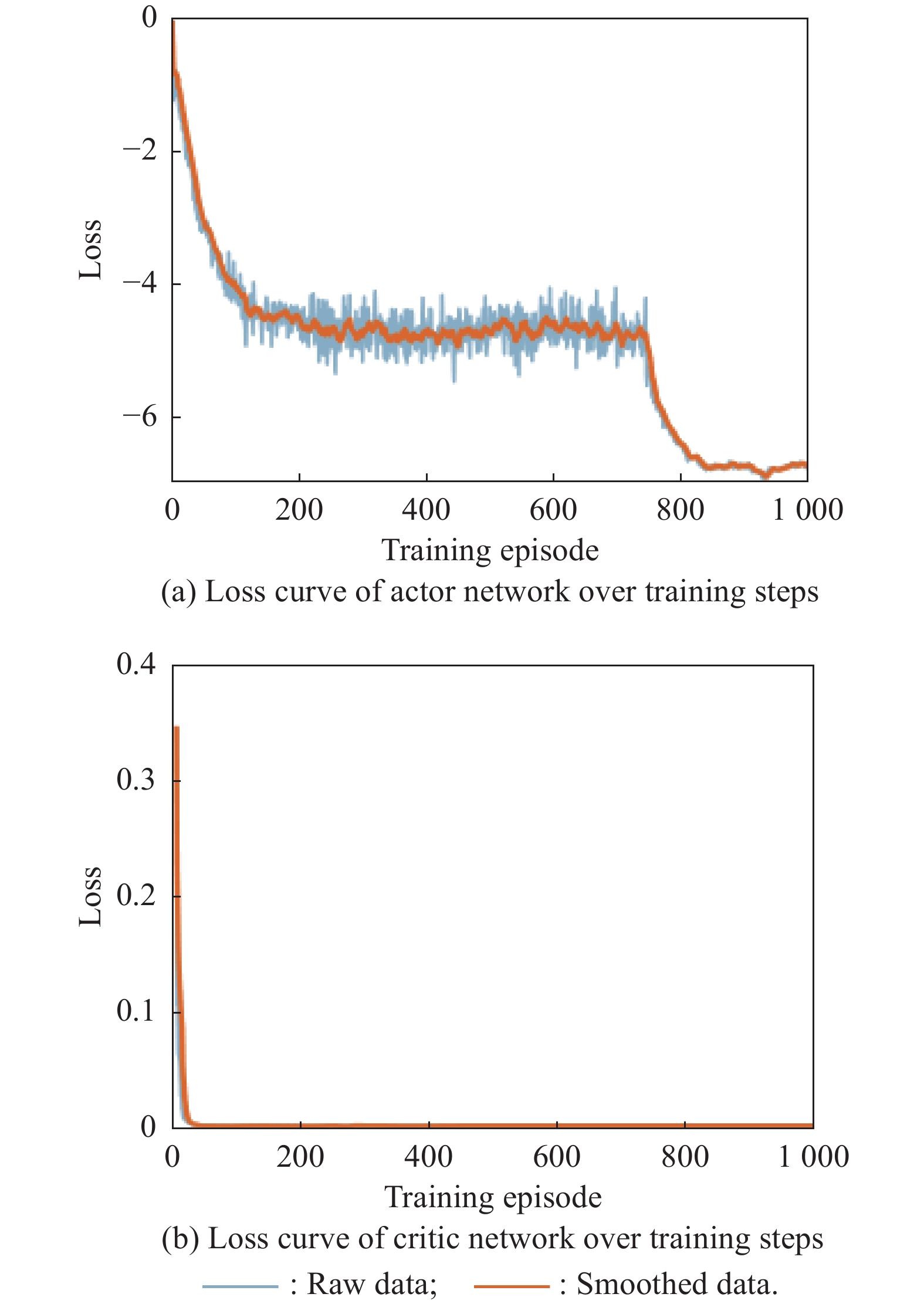
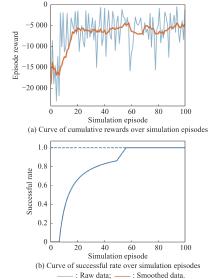
Fig 15
Curves of evaluation parameters for training under the setting of UER-DDPG and RS without advice in the guidance towards areatask"

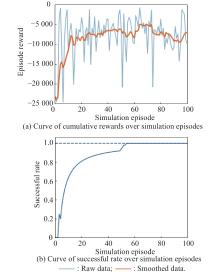
Fig 16
Curves of evaluation parameters for training under the setting of PER-DDPG and RS without advice in the guidance towards areatask"
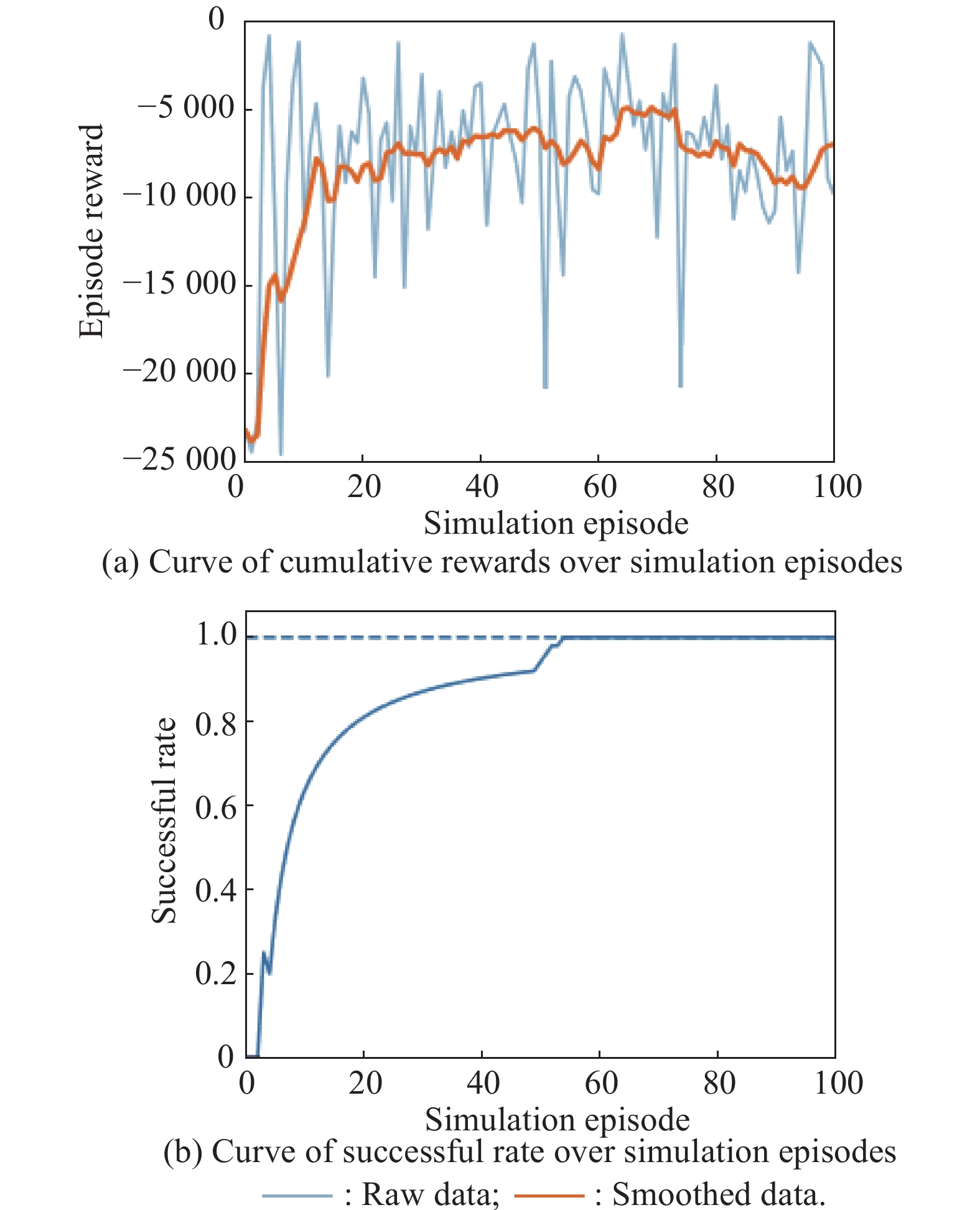
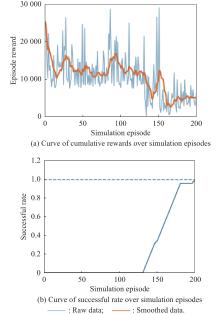
Fig 17
Curves of evaluation parameters for training under the setting of UER-DDPG and RS with advice in the guidance towards area task"
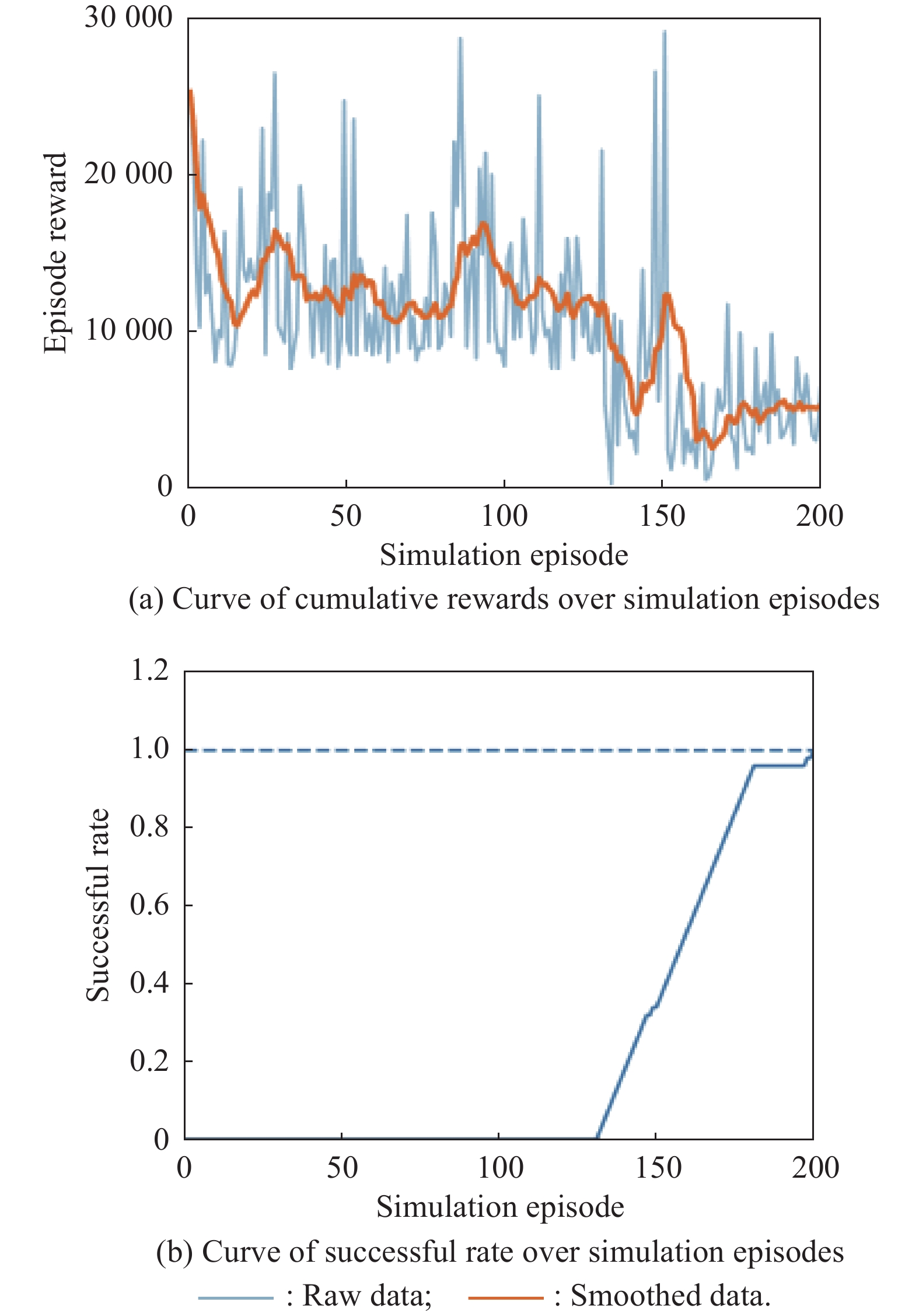
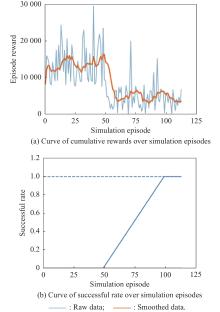
Fig 18
Curves of evaluation parameters for training under the setting of PER-DDPG and RS with advice in the guidance towards area task"
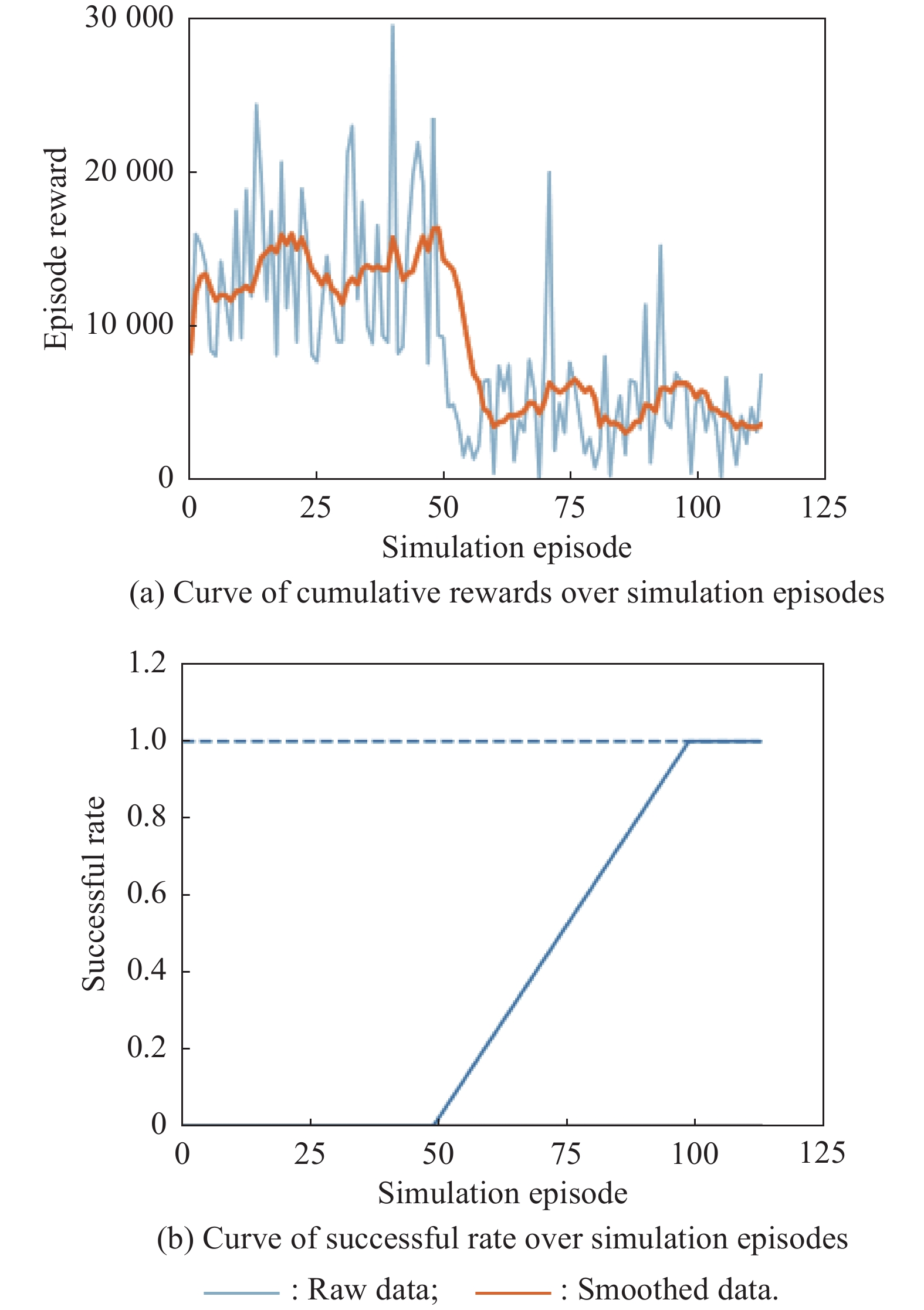
Table 5
Statistical results of MC test experiments in the guidance towards area task"
| Method | Number of experiments | Number of successful experiments | Successful rate |
| UER-DDPG and RS without advice | 1000 | 998 | 0.998 |
| PER-DDPG and RS without advice | 1000 | 999 | 0.999 |
| UER-DDPG and RS with advice | 1000 | 999 | 0.999 |
| PER-DDPG and RS | 1000 | 999 | 0.999 |
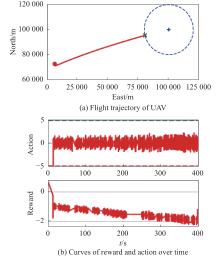
Fig 19
Visualization of test experiment for the trained policy of UER-DDPG and RS without advice in the guidance towards area task"
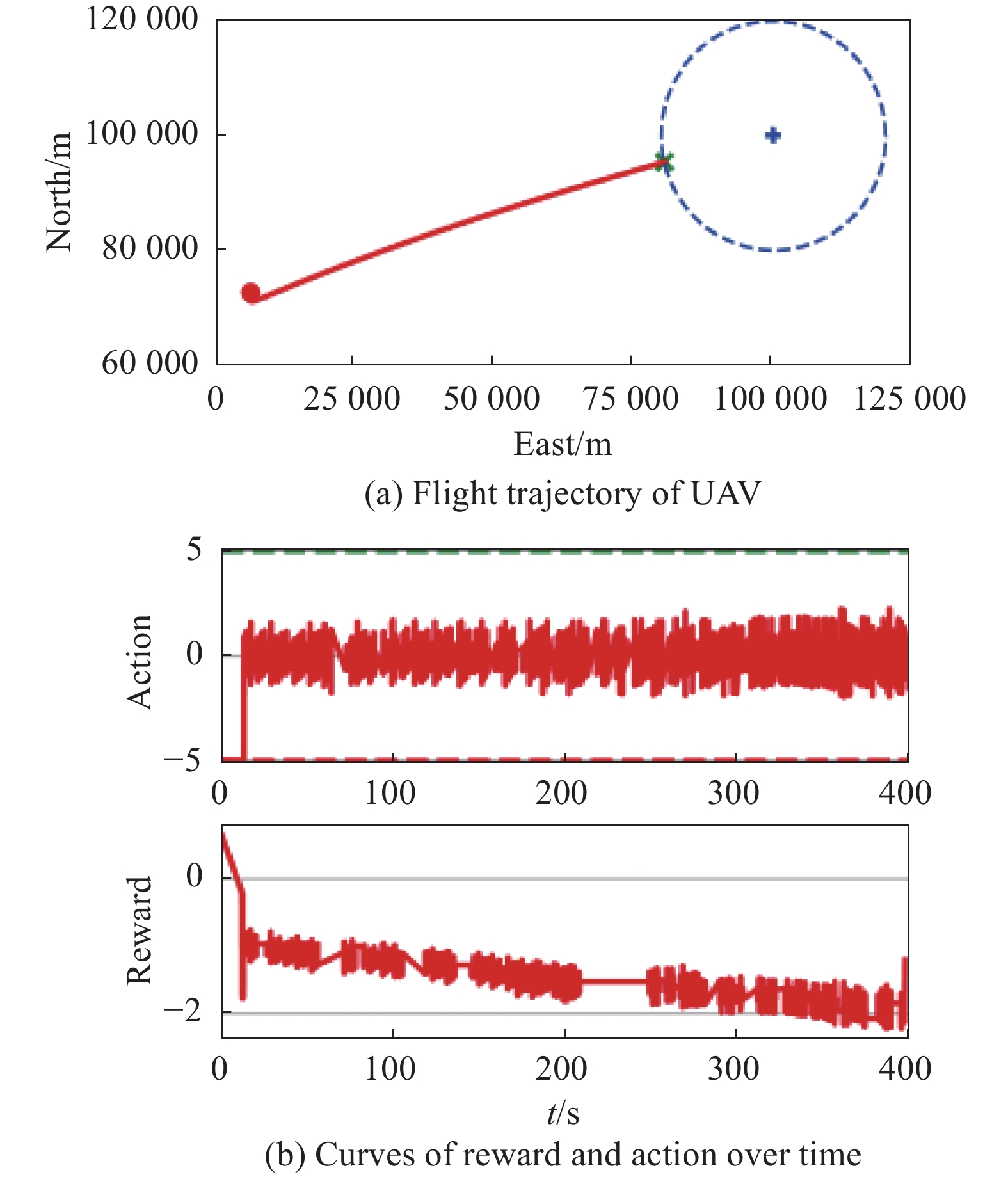
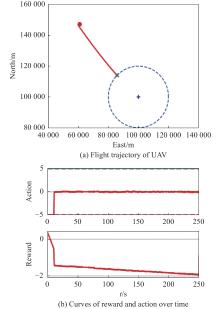
Fig 20
Visualization of test experiment for the trained policy of PER-DDPG and RS without advice in the guidance towards area task"
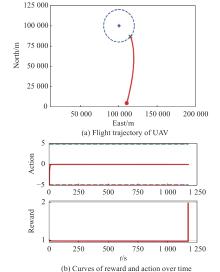
Fig 21
Visualization of test experiment for the trained policy of UER-DDPG and RS with advice in the guidance towards area task"
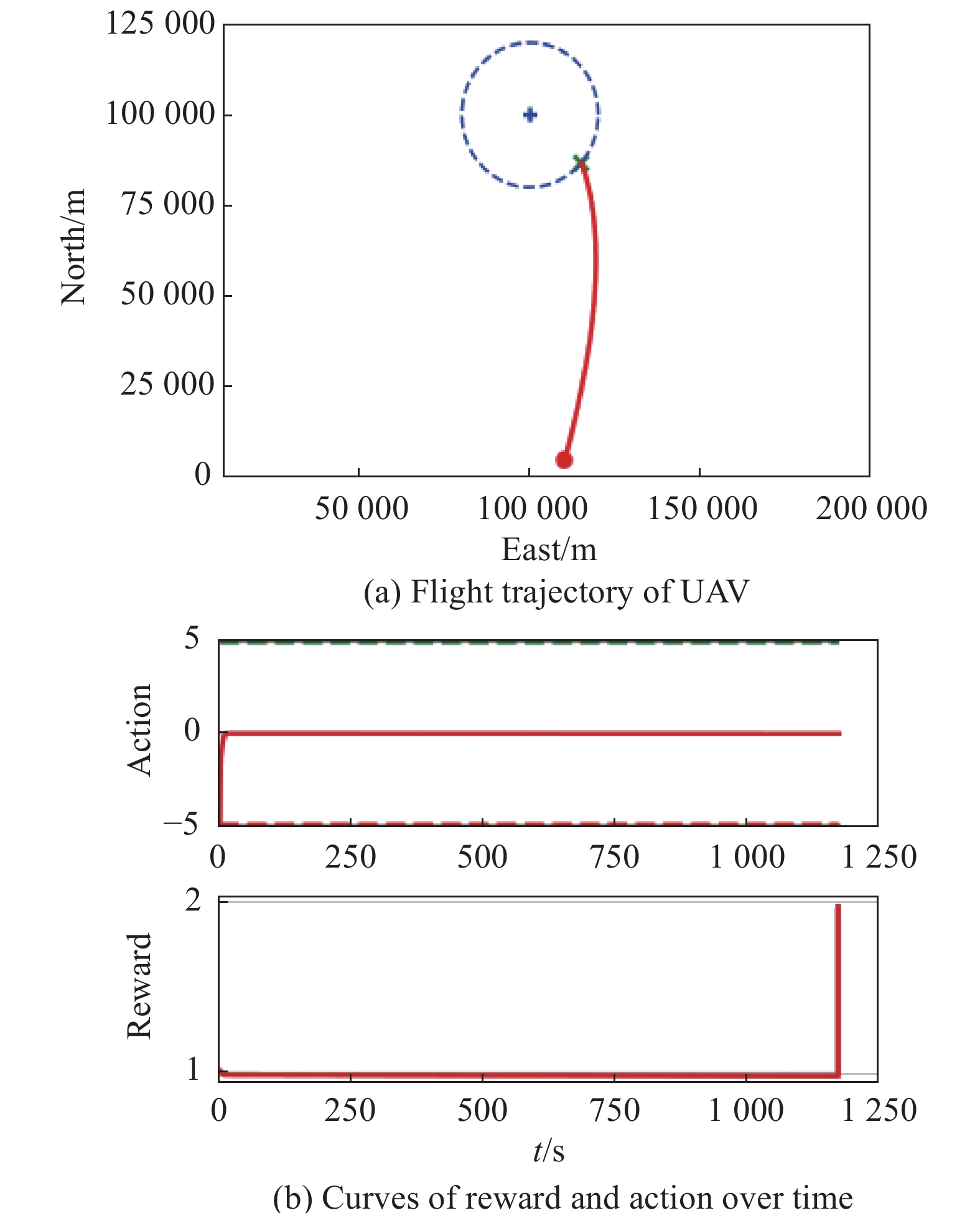

Fig 22
Visualization of test experiment for the trained policy of PER-DDPG and RS with Advice in the guidance towards area task"
Table 6
Parameters assignment of algorithm for the guidance towards specific point task"
| Parameter | Value | Meaning |
| 100 | Policy’s learning period | |
| 50000 | Historical buffer capacity | |
| 0.01 | Soft updating parameter | |
| 256 | Size of minibatch | |
| 0.001 | Actor networks’ learning rate | |
| 0.001 | Critic networks’ learning rate | |
| 0.5 | Availability exponent of PER | |
| 0.1 | Initial IS exponent | |
| 3000 | Maximum training episodes | |
| 5000 | Maximum steps per episode |
Table 7
Structure of critic network ${\boldsymbol{Q}}\left( {{\boldsymbol{s}},{\boldsymbol{a}}|{{\boldsymbol{\theta}} _{\boldsymbol{Q}}}} \right)$ for the guidance towards specific point task"
| Layer name | Layer structure | |
| Unit | Activation function | |
| Input layer of state | 16 | ReLU |
| Input layer of action | 16 | ReLU |
| Hidden layer 1 | 32 | ReLU |
| Hidden layer 2 | 64 | ReLU |
| Hidden layer 3 | 32 | ReLU |
| Output layer | 1 | None |
Table 8
Structure of actor network ${\boldsymbol{\mu}} \left( {{\boldsymbol{s}}|{{\boldsymbol{\theta }}_{\boldsymbol{\mu}} }} \right)$ for the guidance towards specific point task"
| Layer name | Layer structure | |
| Unit | Activation function | |
| Input layer | 16 | Tanh |
| Hidden layer 1 | 32 | Tanh |
| Hidden layer 2 | 64 | Tanh |
| Hidden layer 3 | 32 | Tanh |
| Output layer | 1 | Tanh |
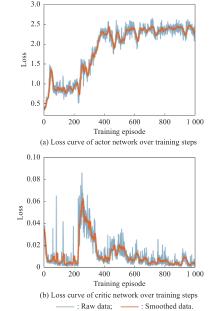
Fig 23
Loss curves of actor network and critic network over training steps under the setting of UER-DDPG and RS without advice in the guidance towards specific point task"
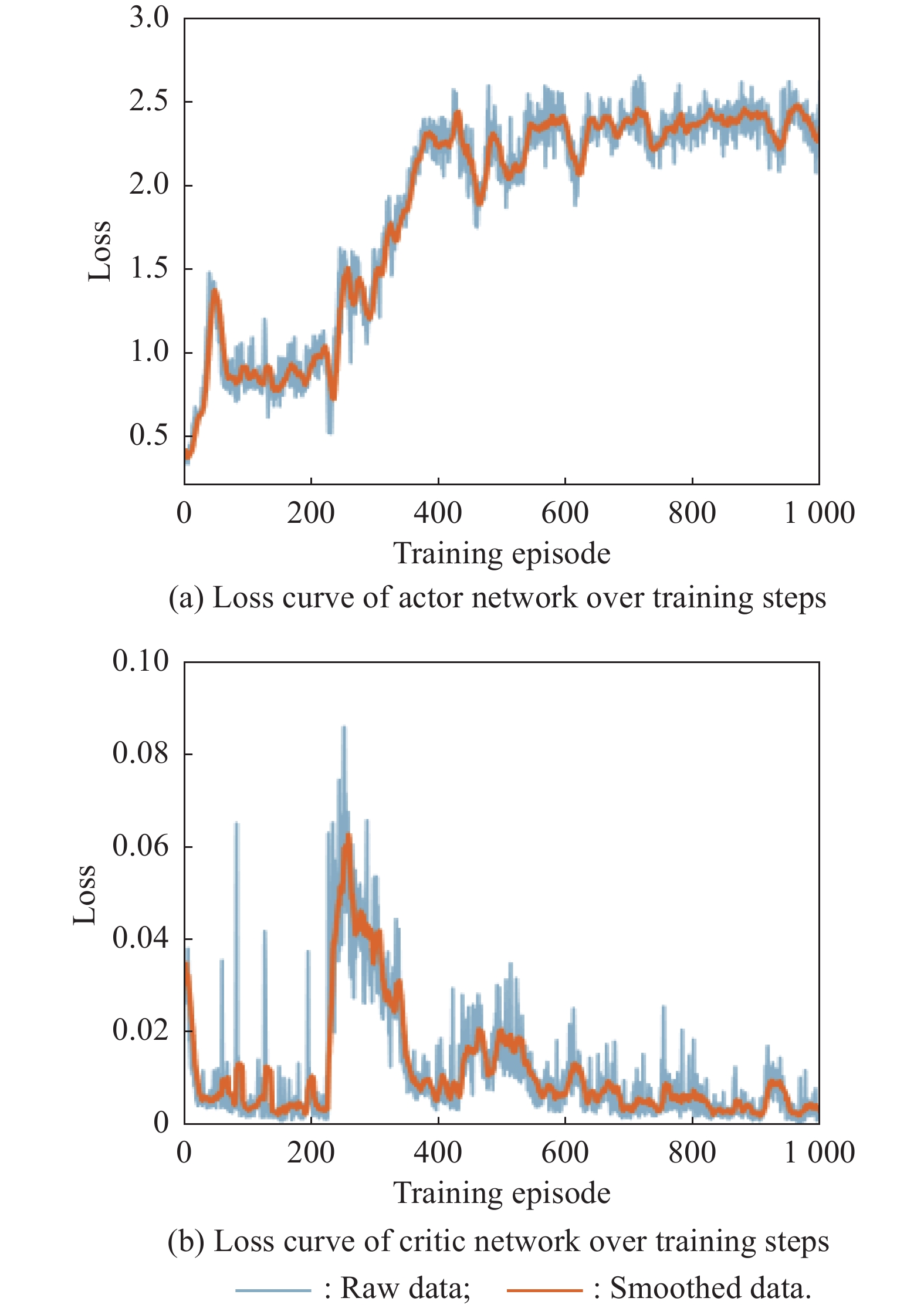
Fig 24
Loss curves of actor network and critic network over training steps under the setting of PER-DDPG and RS without advice in theguidance towards specific point task"
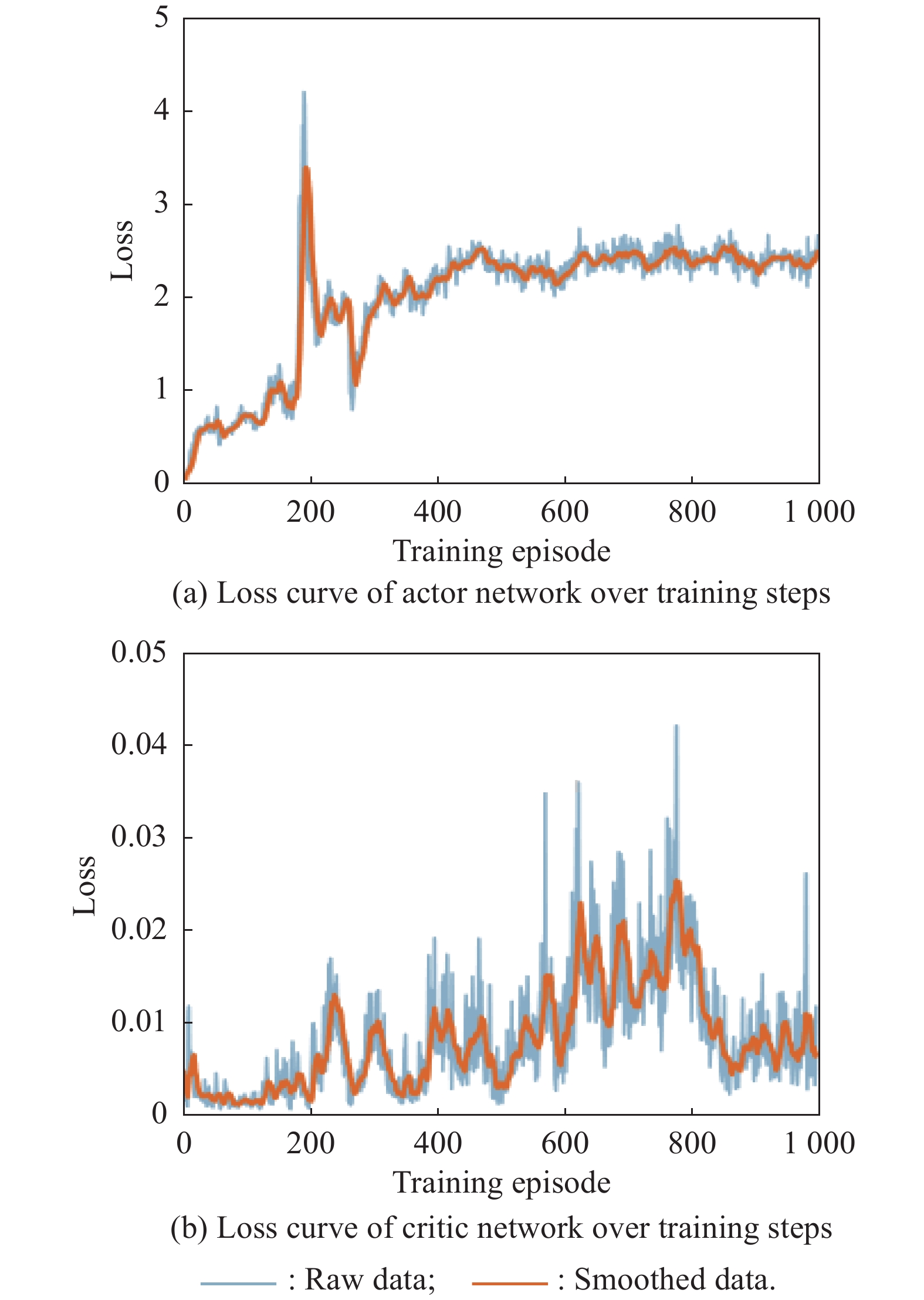
Fig 25
Loss curves of actor network and critic network over training steps under the setting of UER-DDPG and RS with advice in the guidance towards specific point task"
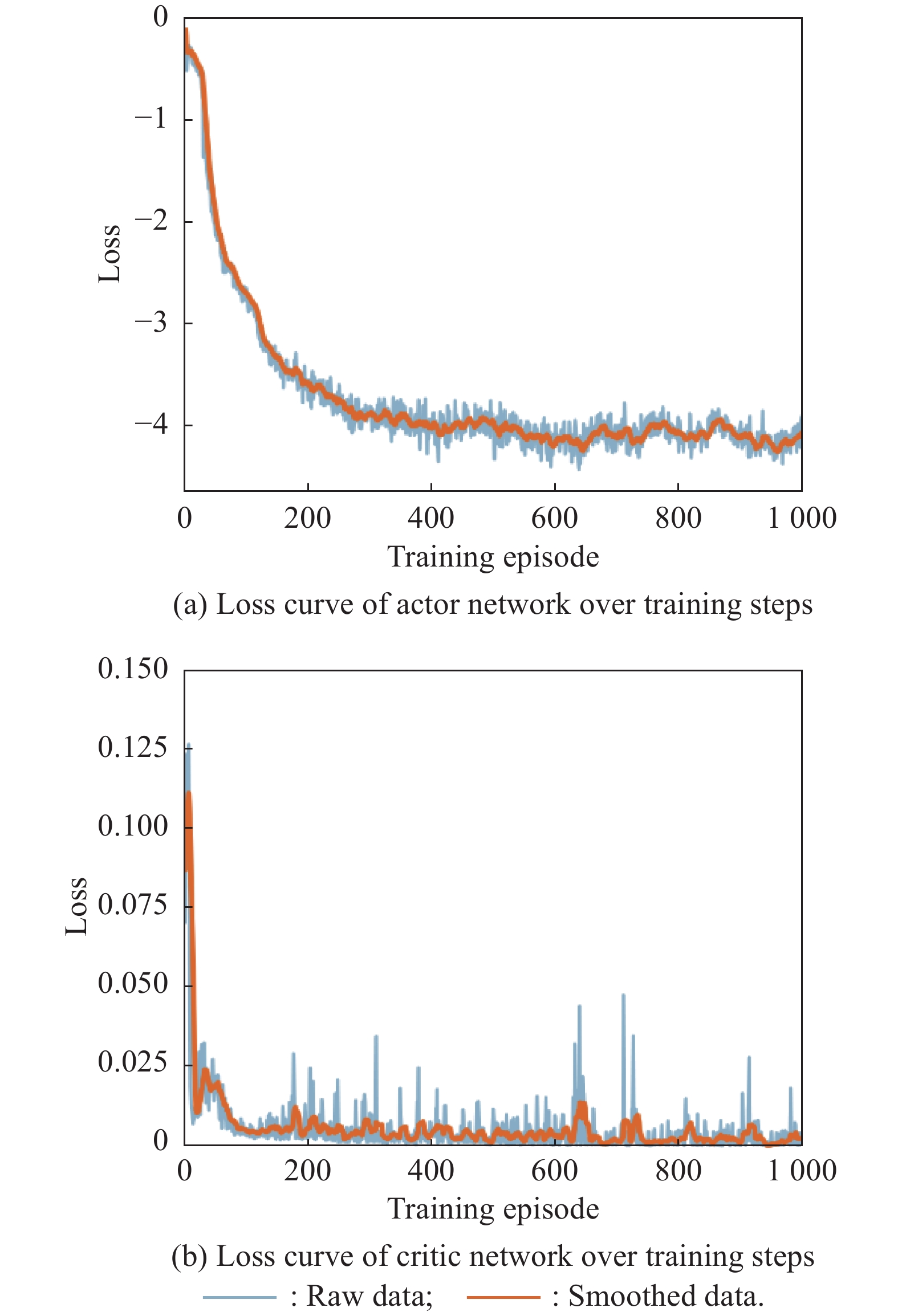
Fig 26
Loss curves of actor network and critic network over training steps under the setting of PER-DDPG and RS with advice in the guidance towards specific point task"
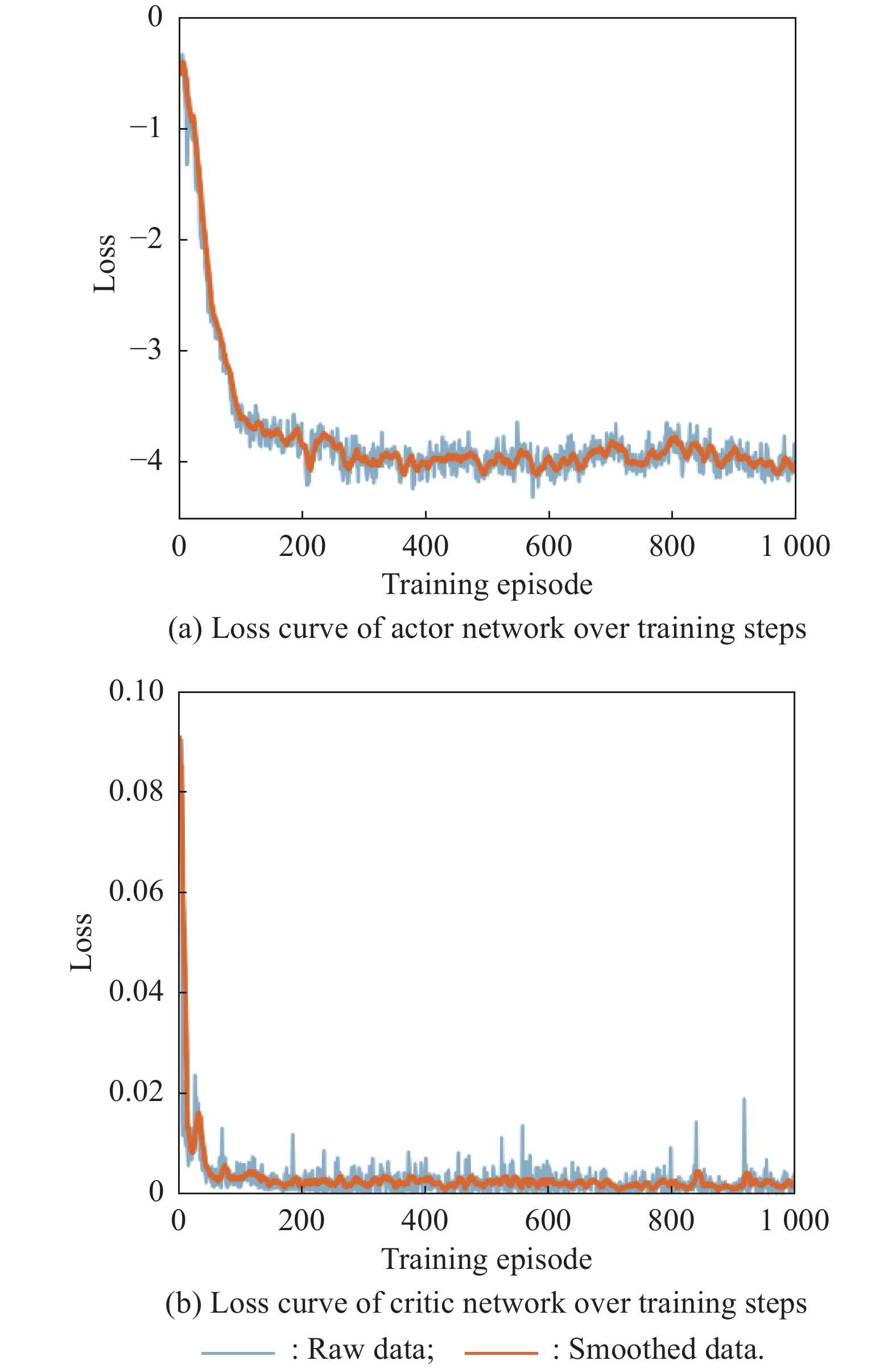
Fig 27
Curves of evaluation parameters for training under the setting of UER-DDPG and RS without advice in the guidance towards specific point task"
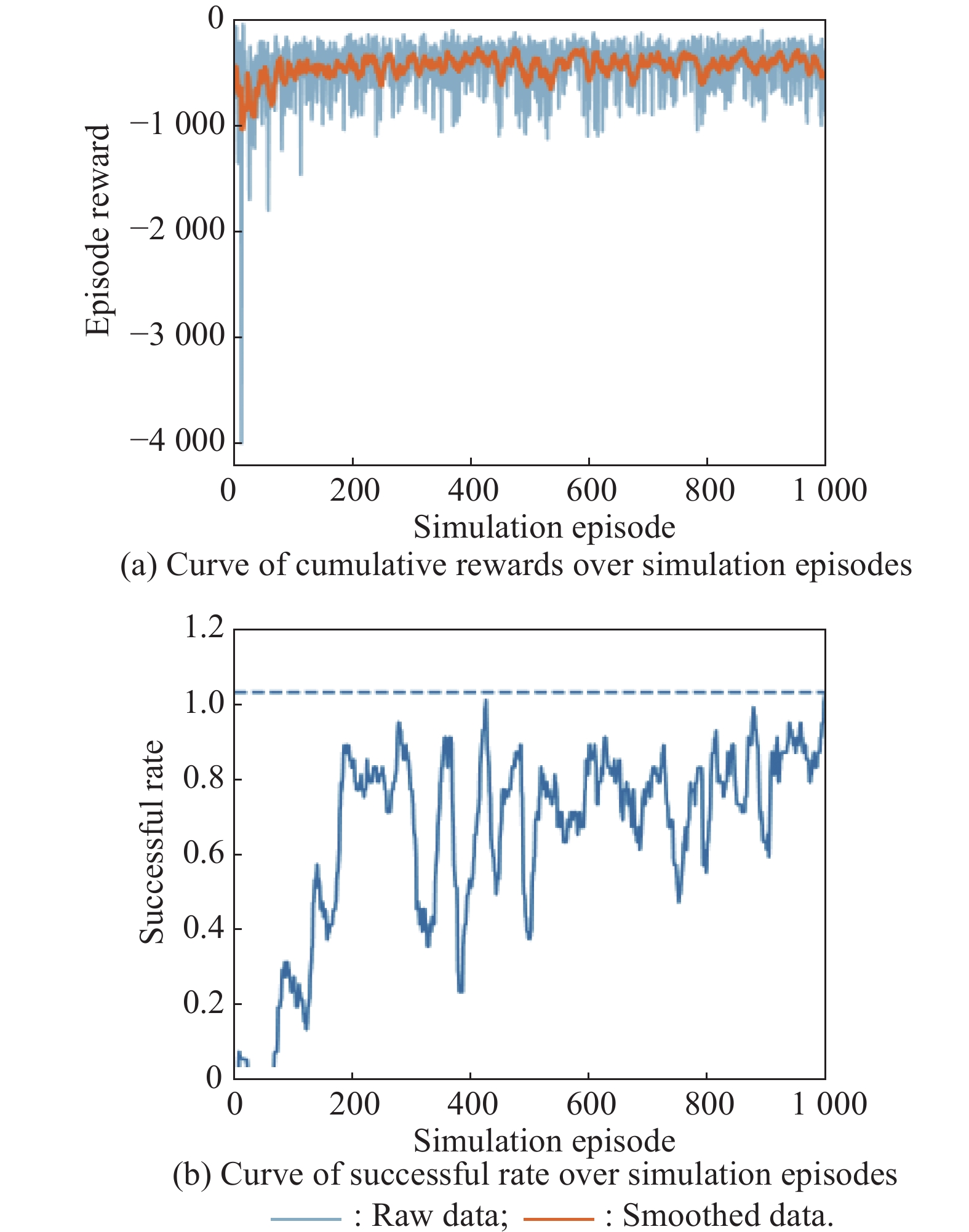
Fig 28
Curves of evaluation parameters for training under the setting of PER-DDPG and RS without advice in the guidance towards specific point task"
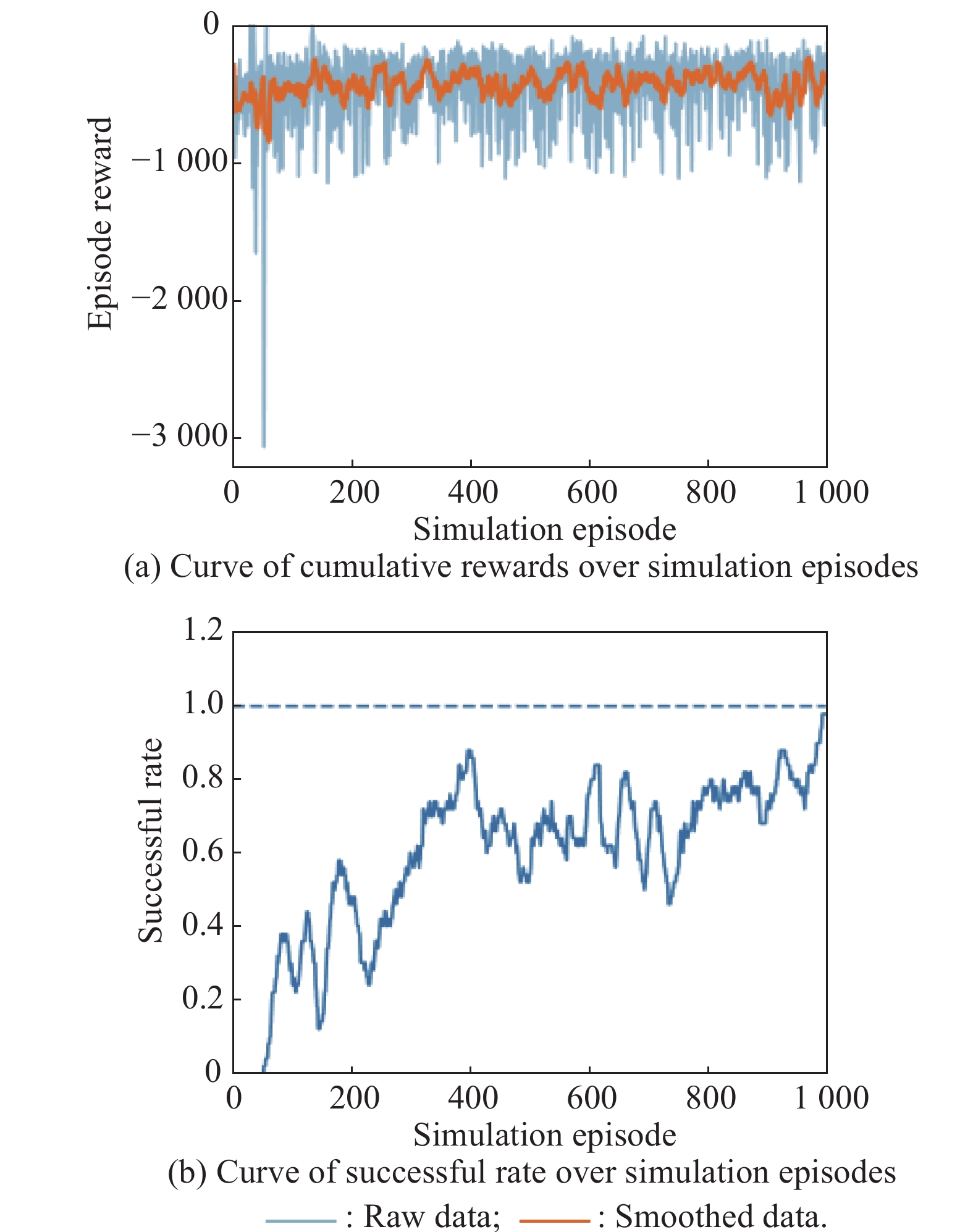
Fig 29
Curves of evaluation parameters for training under the setting of UER-DDPG and RS with advice in the guidance towards specificpoint task"
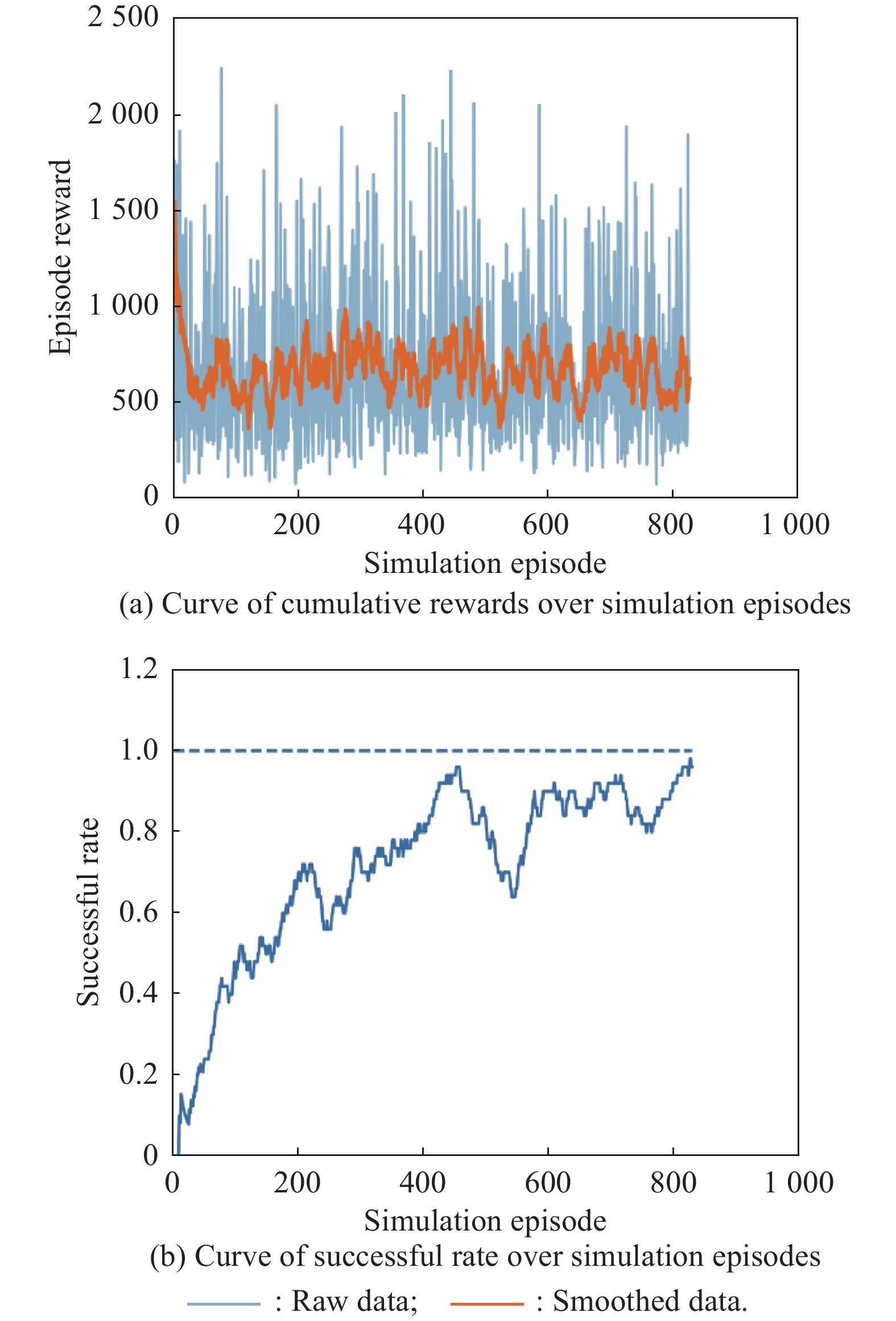
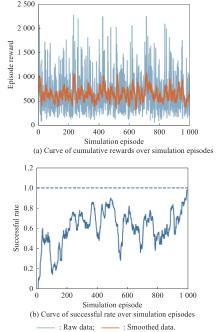
Fig 30
Curves of evaluation parameters for training under the setting of PER-DDPG and RS with advice in the guidance towards specific point task"
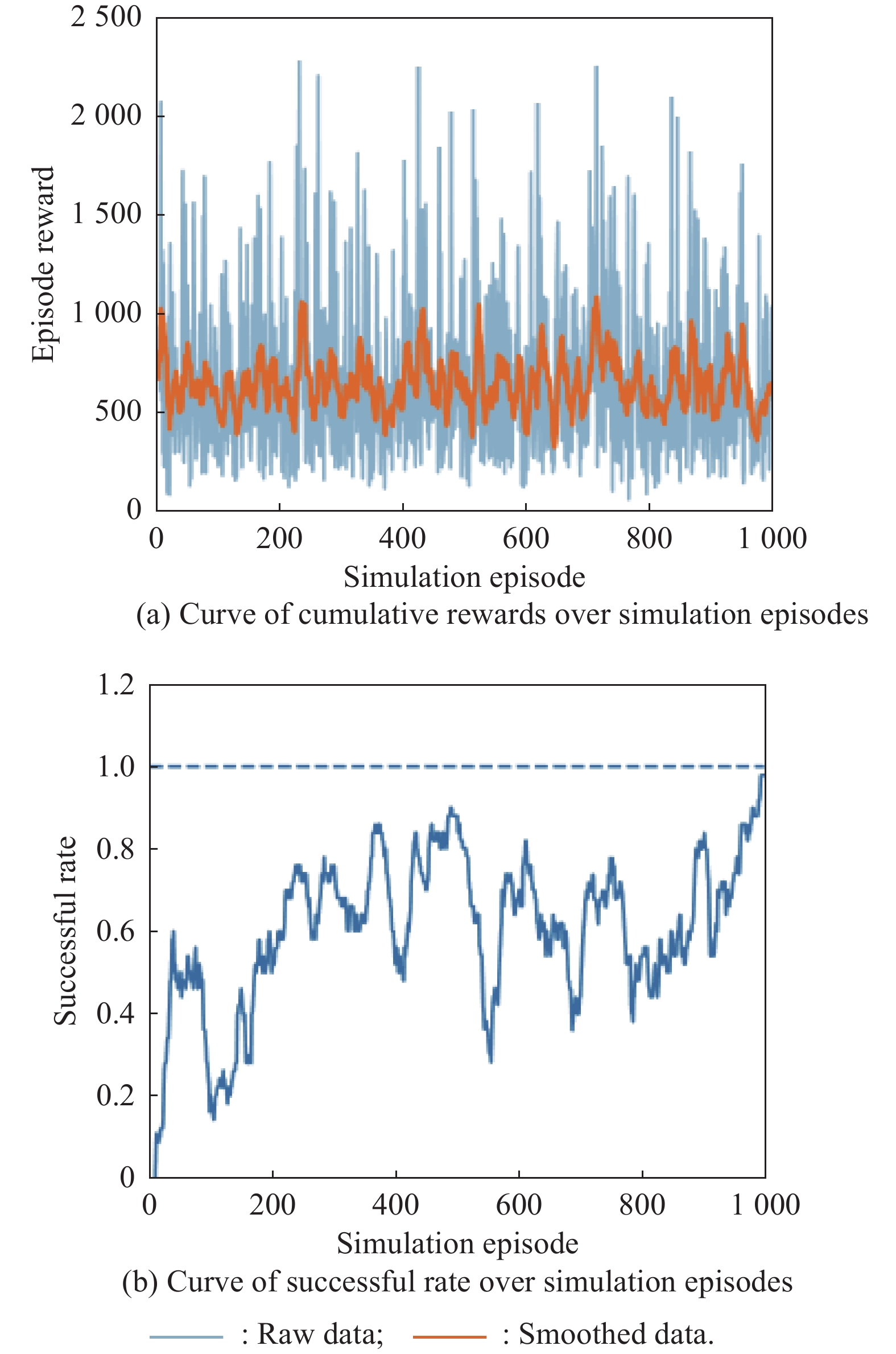
Table 9
Statistical results of MC test experiments in the guidance towards specific point task"
| Method | Number of experiments | Number of successful experiments | Successful rate |
| UER-DDPG and RS without advice | 1000 | 743 | 0.743 |
| PER-DDPG and RS without advice | 1000 | 893 | 0.893 |
| UER-DDPG and RS with advice | 1000 | 957 | 0.957 |
| PER-DDPG and RS | 1000 | 943 | 0.943 |
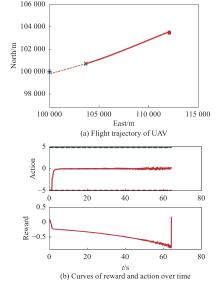
Fig 31
Visualization of test experiment for the trained policy of UER-DDPG and RS without advice in the guidance towards specific point task"
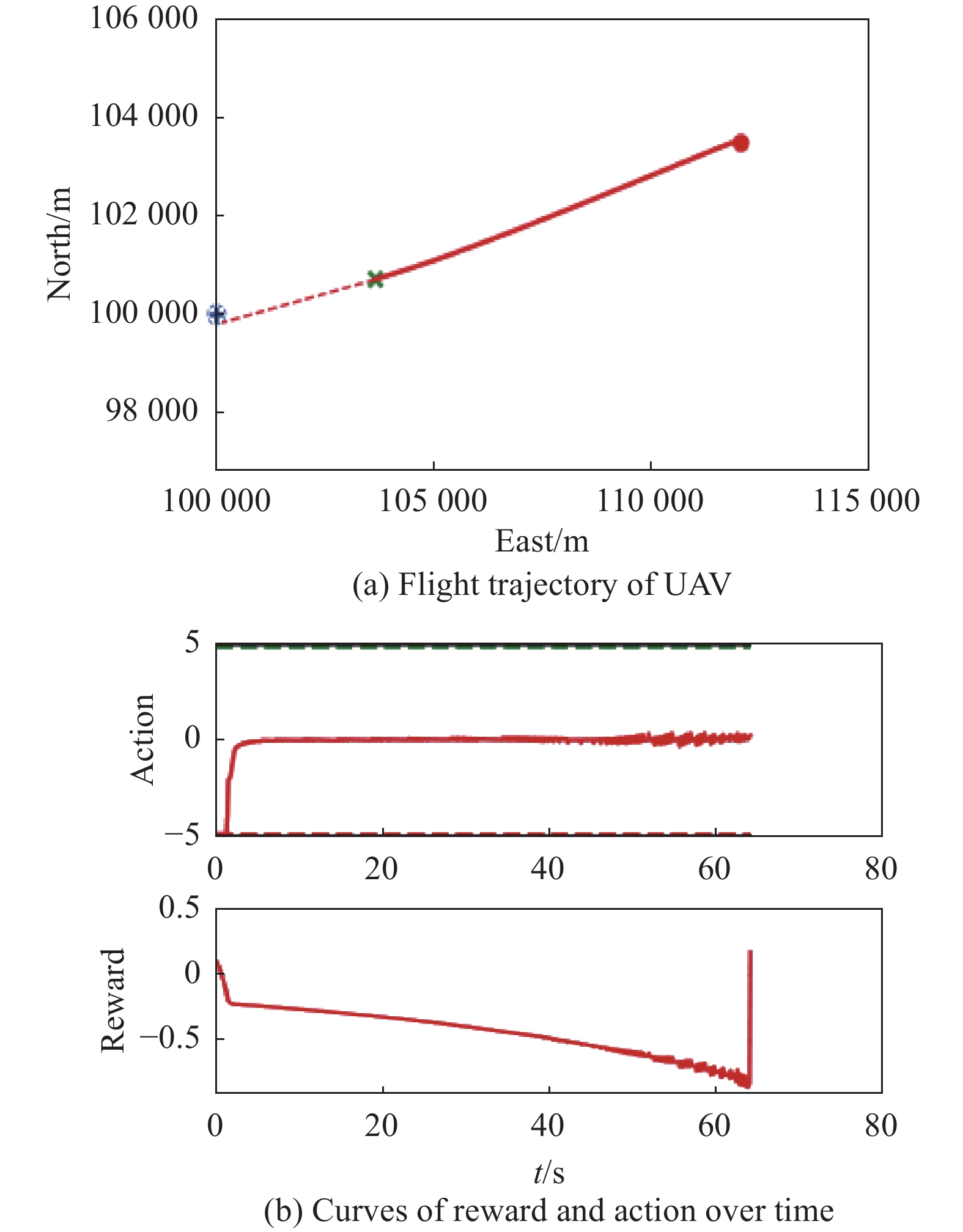
Fig 32
Visualization of test experiment for the trained policy of PER-DDPG and RS without advice in the guidance towards specific point task"
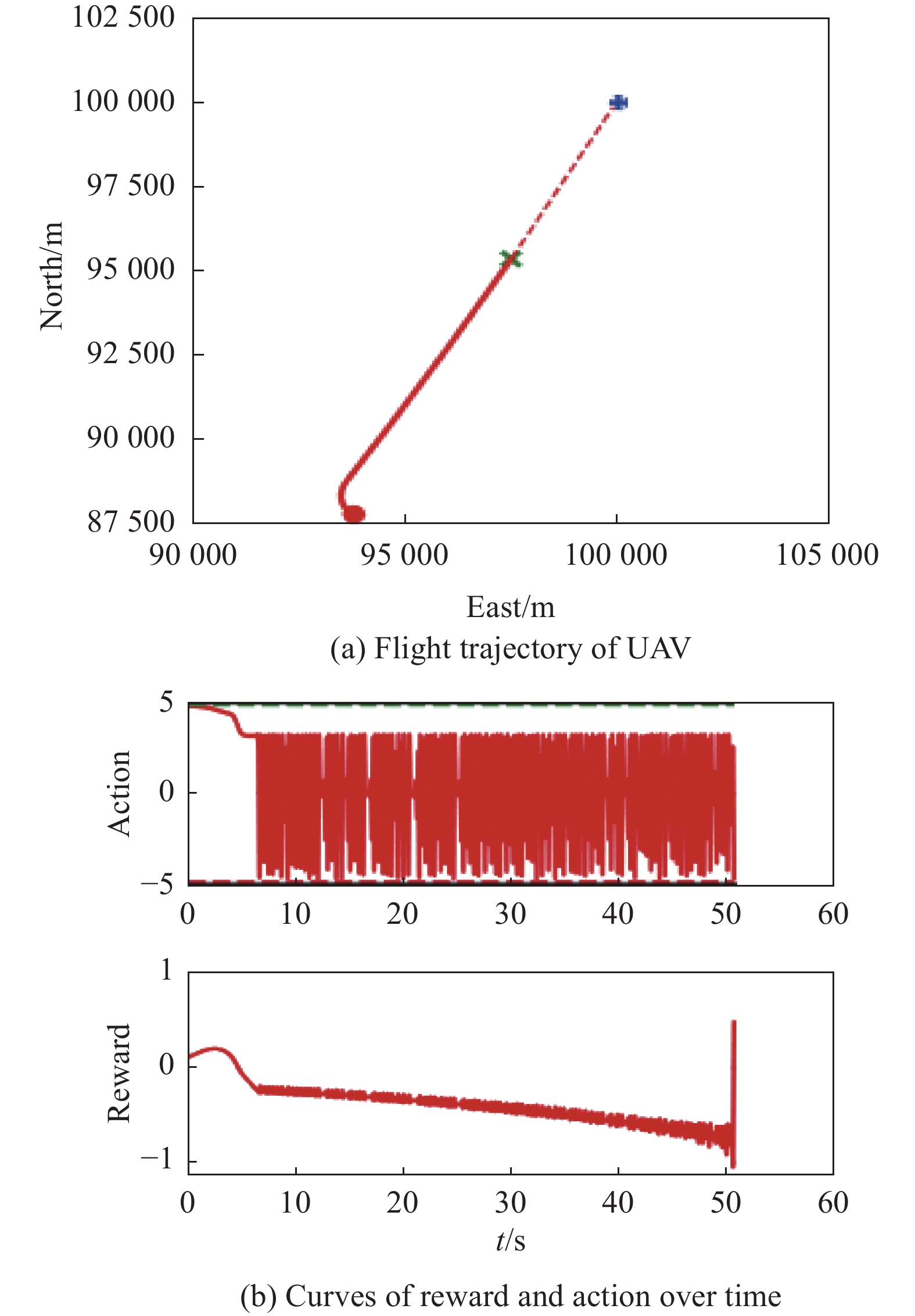
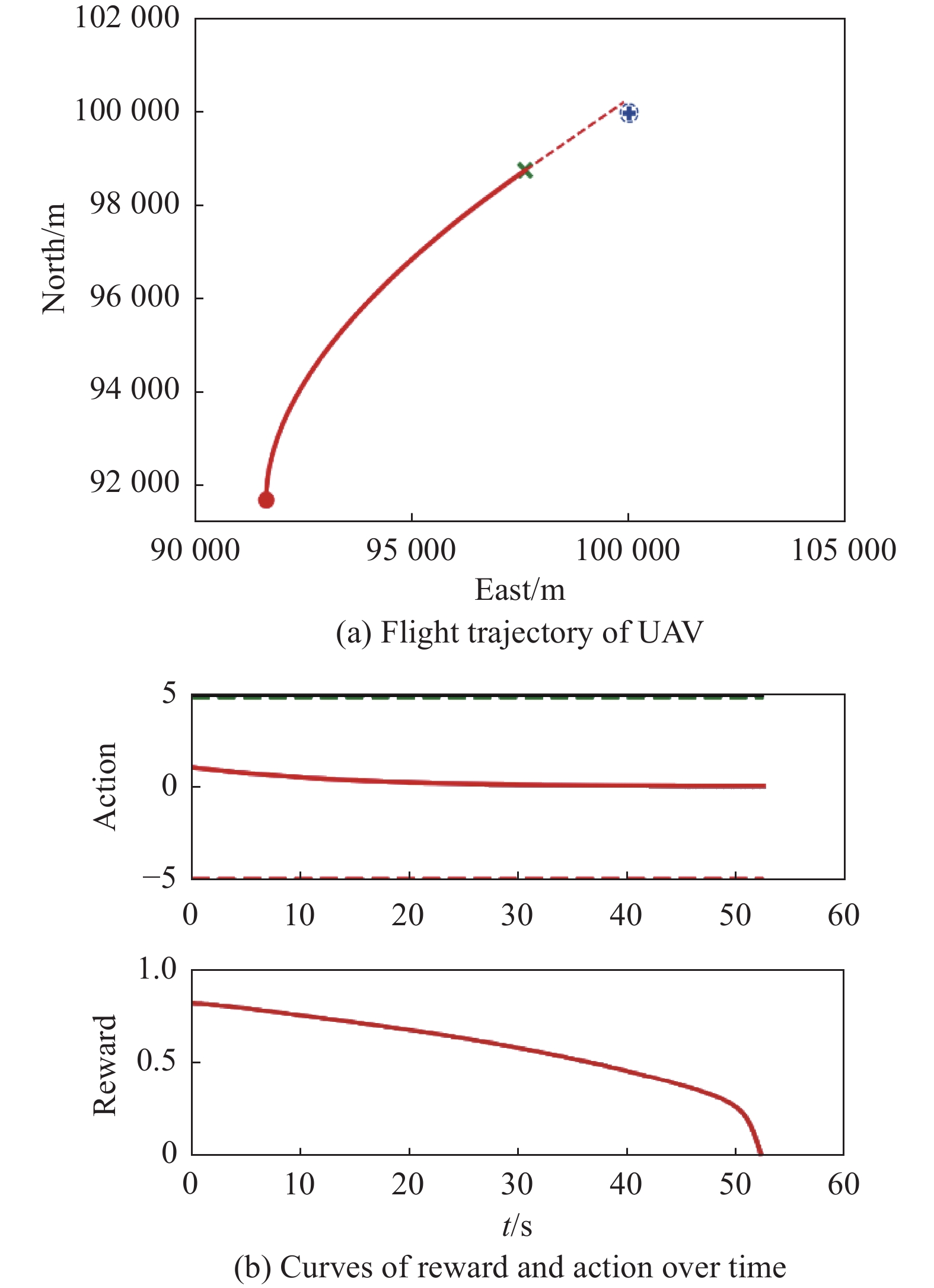
Fig 33
Visualization of test experiment for the trained policy of UER-DDPG and RS with advice in the guidance towards specific point task"
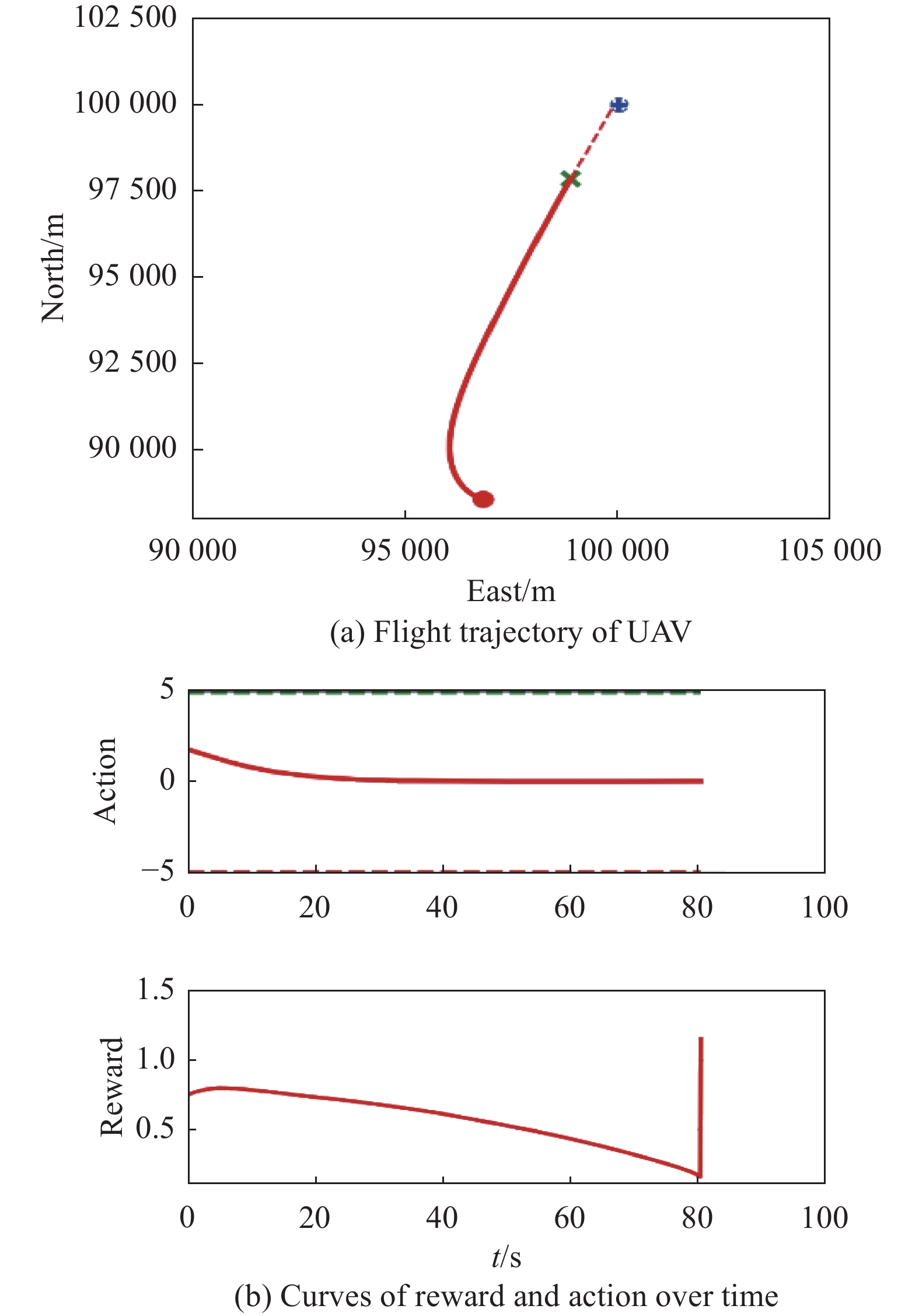
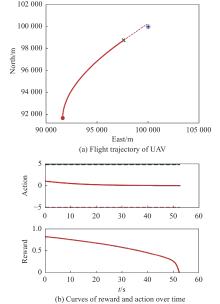
Fig 34
Visualization of test experiment for the trained policy of PER-DDPG and RS with advice in the guidance towards specific point task"
| 1 |
HALUDER H, BREZAK M, PETROVIC I, et al UAV-enabled intelligent transportation systems for the smart city: applications and challenges. IEEE Communications Magazine, 2017, 55 (3): 22- 28.
doi: 10.1109/MCOM.2017.1600238CM |
| 2 |
MATHISEN S G, LEIRA F S, HELGESEN H H, et al Autonomous ballistic airdrop of objects from a small fixed-wing unmanned aerial vehicle. Autonomous Robots, 2020, 44, 859- 875.
doi: 10.1007/s10514-020-09902-3 |
| 3 |
LYU X, LI X B, DANG D L, et al Unmanned aerial vehicle (UAV) remote sensing in grassland ecosystem monitoring: a systematic review. Remote Sensing, 2022, 14 (5): 1096.
doi: 10.3390/rs14051096 |
| 4 | UKAEGBU U, TARTIBU L, OKWU M. Unmanned aerial vehicles for the future: classification, challenges, and opportunities. Proc. of the International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems, 2021. DOI: 10.1109/icABXD51485.2021.9519367. |
| 5 |
SEUNGHYEON L, YOUNGKEUN S, SUNG-HO K Feasibility analyses of real-time detection of wildlife using UAV-derived thermal and rgb images. Remote Sensing, 2021, 13 (11): 2169.
doi: 10.3390/rs13112169 |
| 6 |
LI K, ZHANG K, ZHANG Z C, et al A UAV maneuver decision-making algorithm for autonomous airdrop based on deep reinforcement learning. Sensors, 2021, 21 (6): 2233.
doi: 10.3390/s21062233 |
| 7 | ZHANG K, LI K, HE J L, et al. A UAV autonomous maneuver decision-making algorithm for route guidance. Proc. of the International Conference on Unmanned Aircraft Systems, 2020: 17−25. |
| 8 |
WAN K F, LI B, GAO X G, et al A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments. Journal of Systems Engineering and Electronics, 2021, 32 (6): 1490- 1508.
doi: 10.23919/JSEE.2021.000126 |
| 9 |
ZHANG J D, YANG Q M, SHI G Q, et al UAV cooperative air combat maneuver decision based on multi-agent reinforcement learning. Journal of Systems Engineering and Electronics, 2021, 32 (6): 1421- 1438.
doi: 10.23919/JSEE.2021.000121 |
| 10 | YANG L, QI J T, XIAO J Z, et al. A literature review of UAV 3D path planning. Proc. of the 11th World Congress on Intelligent Control and Automation, 2014: 2376−2381. |
| 11 | HRVOJE K, MISEL B, IVAN P. A visibility graph based method for path planning in dynamic environments. Proc. of the 34th International Convention MIPRO, 2011: 717−721. |
| 12 | SUN Q P, LI M, WANG T H, et al. UAV path planning based on improved rapidly-exploring random tree. Proc. of the Chinese Control and Decision Conference, 2018: 6420−6424. |
| 13 |
YAN F, LIN Y S, XIAO J Z Path planning in complex 3D environments using a probabilistic roadmap method. International Journal of Automation and Computing, 2013, 10 (6): 525- 533.
doi: 10.1007/s11633-013-0750-9 |
| 14 | FAN H T, TSUNG T L, CHO H L, et al. A star search algorithm for civil UAV path planning with 3G communication. Proc. of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing, 2014: 942−945. |
| 15 | MENG B B. UAV path planning based on bidirectional sparse A* search algorithm. Proc. of the International Conference on Intelligent Computation Technology and Automation, 2010: 1106−1109. |
| 16 |
DAVE F, ANTHONY S Using interpolation to improve path planning: the Field D* algorithm. Journal of Field Robotics, 2006, 23 (2): 79- 101.
doi: 10.1002/rob.20109 |
| 17 |
JESIMAR D S, MARCIO D S, CLAUDIO F M T, et al Heuristic and genetic algorithm approaches for UAV path planning under critical situation. International Journal on Artificial Intelligence Tools, 2017, 26 (1): 1760008.
doi: 10.1142/S0218213017600089 |
| 18 |
LEE H, KIM H J Trajectory tracking control of multirotors from modelling to experiments: a survey. International Journal of Control, Automation and Systems, 2017, 15, 281- 292.
doi: 10.1007/s12555-015-0289-3 |
| 19 | SEBASTIAN B, BEN-TZVI P Physics based path planning for autonomous tracked vehicle in challenging terrain. Journal of Intelligent & Robotic Systems, 2019, 95, 511- 526. |
| 20 | XU Z, ZHANG E Z, CHEN Q W Rotary unmanned aerial vehicles path planning in rough terrain based on multi-objective particle swarm optimization. Journal of Systems Engineering and Electronics, 2020, 31 (1): 130- 141. |
| 21 | OBERMEYER K J. Path planning for a UAV performing reconnaissance of static ground targets in terrain. Proc. of the AIAA Guidance, Navigation, and Control Conference, 2009: 5888. |
| 22 | FRANCOIS-LAVET V, HENDERSON P, ISLAM R, et al An introduction to deep reinforcement learning. Foundations and Trends in Machine Learning, 2018, 11 (3/4): 219- 354. |
| 23 |
VOLODYMYR M, KORAY K, DAVID S, et al Human-level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 24 | TIMOTHY P L, JONATHAN J H, ALEXANDER P, et al. Continuous control with deep reinforcement learning. https://arxiv.org/abs/1509.02971. |
| 25 | TOM S, JOHN Q, IOANNIS A, et al. Prioritized experience replay. https://arxiv.org/abs/1511.05952. |
| 26 | PIAO H Y, SUN Z X, MENG G L, et al. Beyond-visual-range air combat tactics auto-generation by reinforcement learning. Proc. of the International Joint Conference on Neural Networks, 2020. DOI: 10.1109/IJCNN48605.2020.9207088. |
| 27 |
SUN Z K, PIAO H Y, YANG Z, et al Multi-agent hierarchical policy gradient for air combat tactics emergence via self-play. Engineering Applications of Artificial Intelligence, 2021, 98, 104112.
doi: 10.1016/j.engappai.2020.104112 |
| 28 |
SHANKARACHARY R, EDWIN K P C UAV path planning in a dynamic environment via partially observable Markov decision process. IEEE Trans. on Aerospace and Electronic Systems, 2013, 49 (4): 2397- 2412.
doi: 10.1109/TAES.2013.6621824 |
| 29 | MARTIJN V O, MARCO W. Reinforcement learning. Cham: Springer, 2012: 3−42. |
| 30 | MASSENGILL H J. A technique for predicting aircraft flow-field effects upon an unguided bomb ballistic trajectory and comparison with flight test results. Proc. of the 31st Aerospace Sciences Meeting, 1993: 856. |
| 31 | MASSENGILL H J. A comparison of simulated and flight test ballistic trajectories for stores released from an aircraft in flight. Proc. of the 35th Aerospace Sciences Meeting and Exhibit, 1997: 926. |
| 32 | BABAK B, NASSER M, MOZAYANI N et al. A new potential-based reward shaping for reinforcement learning agent. Proc. of the IEEE 13th Annual Computing and Communication Workshop and Conference, 2023. DOI: 10.1109/CCWC57344.2023.10099211. |
| 33 | ANDREW Y N, DAISHI H, STUART R. Policy invariance under reward transformations: theory and application to reward shaping. Proc. of the International Conference on Machine Learning, 1999: 278−287. |
| 34 | ERIC W, GARRISON W C, CHARLES E. Principled methods for advising reinforcement learning agents. Proc. of the 20th International Conference on Machine Learning, 2003: 792−799. |
| [1] | Jiandong ZHANG, Yukun GUO, Lihui ZHENG, Qiming YANG, Guoqing SHI, Yong WU. Real-time UAV path planning based on LSTM network [J]. Journal of Systems Engineering and Electronics, 2024, 35(2): 374-385. |
| [2] | Boyu QIN, Dong ZHANG, Shuo TANG, Yang XU. Two-layer formation-containment fault-tolerant control of fixed-wing UAV swarm for dynamic target tracking [J]. Journal of Systems Engineering and Electronics, 2023, 34(6): 1375-1396. |
| [3] | Jianhong WANG, RAMIREZ-MENDOZA Ricardo A., Yang XU. Nonlinear direct data-driven control for UAV formation flight system [J]. Journal of Systems Engineering and Electronics, 2023, 34(6): 1409-1418. |
| [4] | Zhiwen XIAO, Xiaowei FU. A cooperative detection game: UAV swarm vs. one fast intruder [J]. Journal of Systems Engineering and Electronics, 2023, 34(6): 1565-1575. |
| [5] | Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224. |
| [6] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [7] | Jie LI, Xiaoyu DANG, Sai LI. DQN-based decentralized multi-agent JSAP resource allocation for UAV swarm communication [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 289-298. |
| [8] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [9] | Xing LEI, Xiaoxuan HU, Guoqiang WANG, He LUO. A multi-UAV deployment method for border patrolling based on Stackelberg game [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 99-116. |
| [10] | Hao LI, Hemin SUN, Ronghua ZHOU, Huainian ZHANG. Hybrid TDOA/FDOA and track optimization of UAV swarm based on A-optimality [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 149-159. |
| [11] | Weikun HE, Jingbo SUN, Xinyun ZHANG, Zhenming LIU. Micro-Doppler feature extraction of micro-rotor UAV under the background of low SNR [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1127-1139. |
| [12] | Yang XU, Weiming ZHENG, Delin LUO, Haibin DUAN. Dynamic affine formation control of networked under-actuated quad-rotor UAVs with three-dimensional patterns [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1269-1285. |
| [13] | Honghong ZHANG, Xusheng GAN, Shuangfeng LI, Zhiyuan CHEN. UAV safe route planning based on PSO-BAS algorithm [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1151-1160. |
| [14] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| [15] | Yangjun GAO, Guangyun LI, Zhiwei LYU, Lundong ZHANG, Zhongpan LI. Improved adaptively robust estimation algorithm for GNSS spoofer considering continuous observation error [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1237-1248. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||