
Journal of Systems Engineering and Electronics ›› 2025, Vol. 36 ›› Issue (5): 1353-1373.doi: 10.23919/JSEE.2025.000115
• CONTROL THEORY AND APPLICATION • Previous Articles
Rui ZHOU1,2( ), Weichao ZHONG3(), Wenlong LI3(), Hao ZHANG1,2,*()
), Weichao ZHONG3(), Wenlong LI3(), Hao ZHANG1,2,*()
Received:2024-09-18
Online:2025-10-18
Published:2025-10-24
Contact:
Hao ZHANG
E-mail:zhourui221@mails.ucas.ac.cn;zhongweichaohit@gmail.com;liwenlongzacao@126.com;hao.zhang.zhr@gmail.com
About author:Rui ZHOU, Weichao ZHONG, Wenlong LI, Hao ZHANG. Self-play training and analysis for GEO inspection game with modular actions[J]. Journal of Systems Engineering and Electronics, 2025, 36(5): 1353-1373.
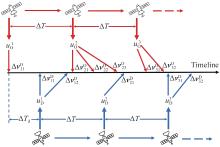
Fig 1
Turn-based impulsive orbital game decision process"
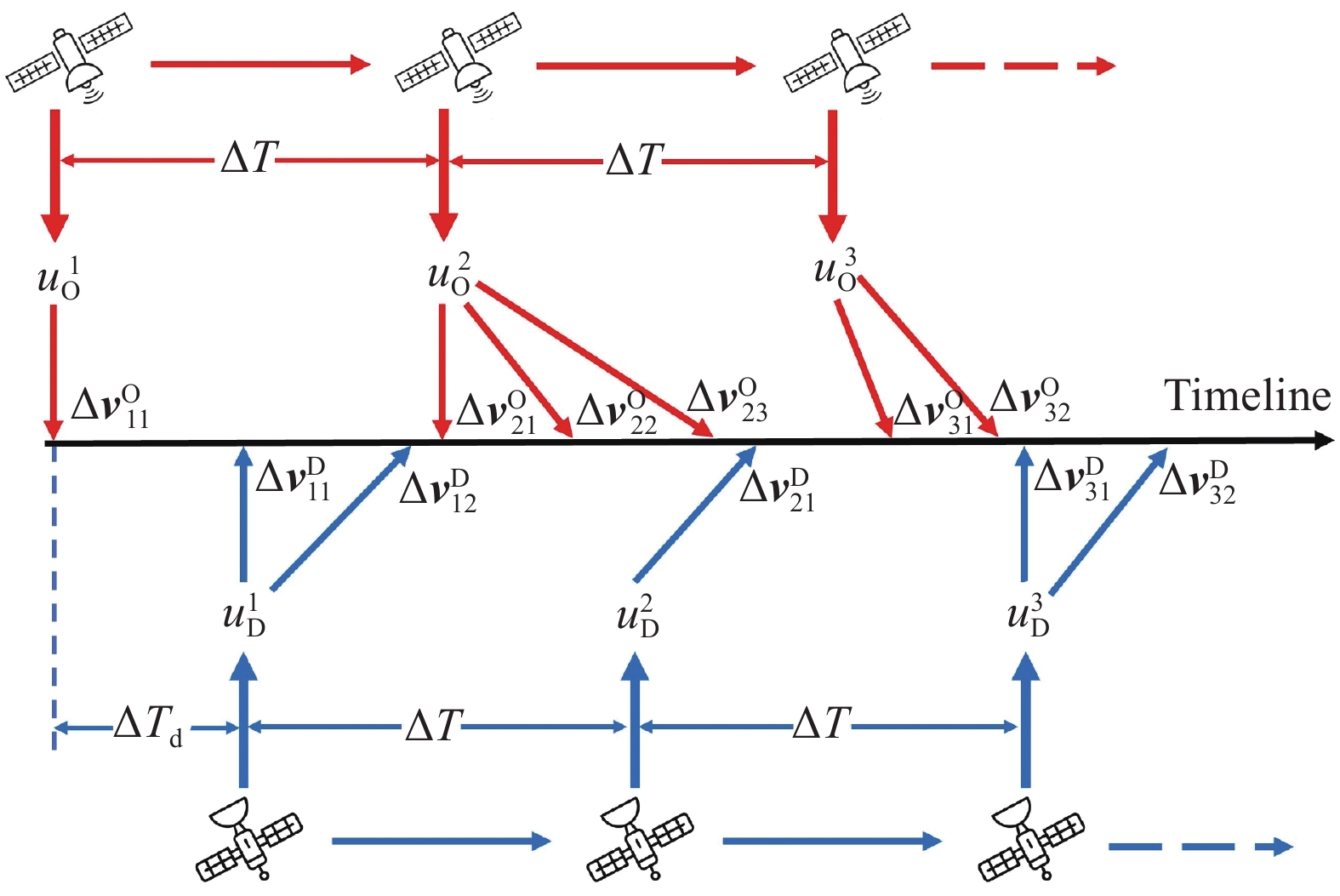
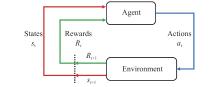
Fig 2
Principle of Markov decision process"
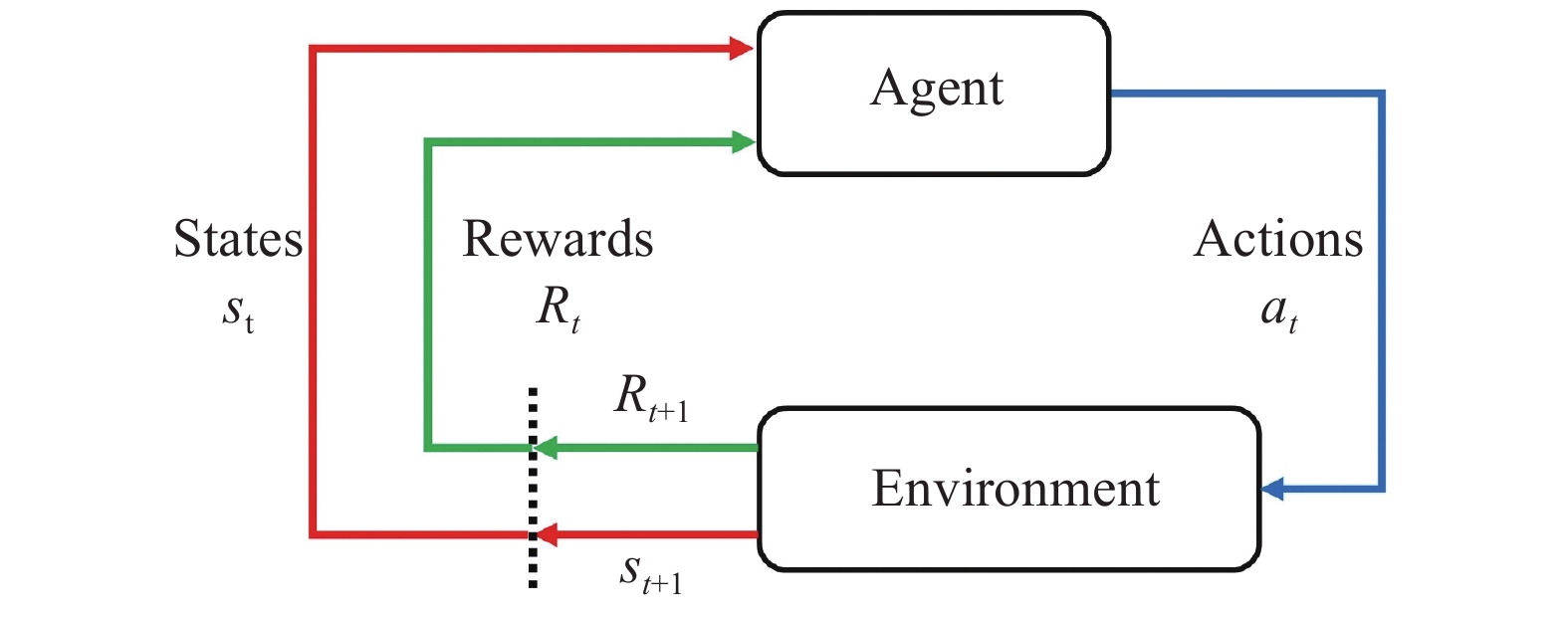
Table 1
Modular actions set"
| Module | Description |
| Hop | Transfer between two |
| ToVbar | Double impulse transfer to V-bar |
| Glideslope | Multiple impulse gliding |
| Natural motion circumnavigation (NMC) | Natural motion circumnavigation |
| Teardrop | Drop-like periodic hovering |
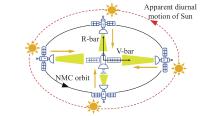
Fig 3
Inspection in front lighting on NMC orbit"
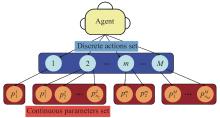
Fig 4
Generalized form of parameterized action space"
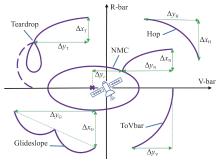
Fig 5
Trajectory and parameters of the modules"
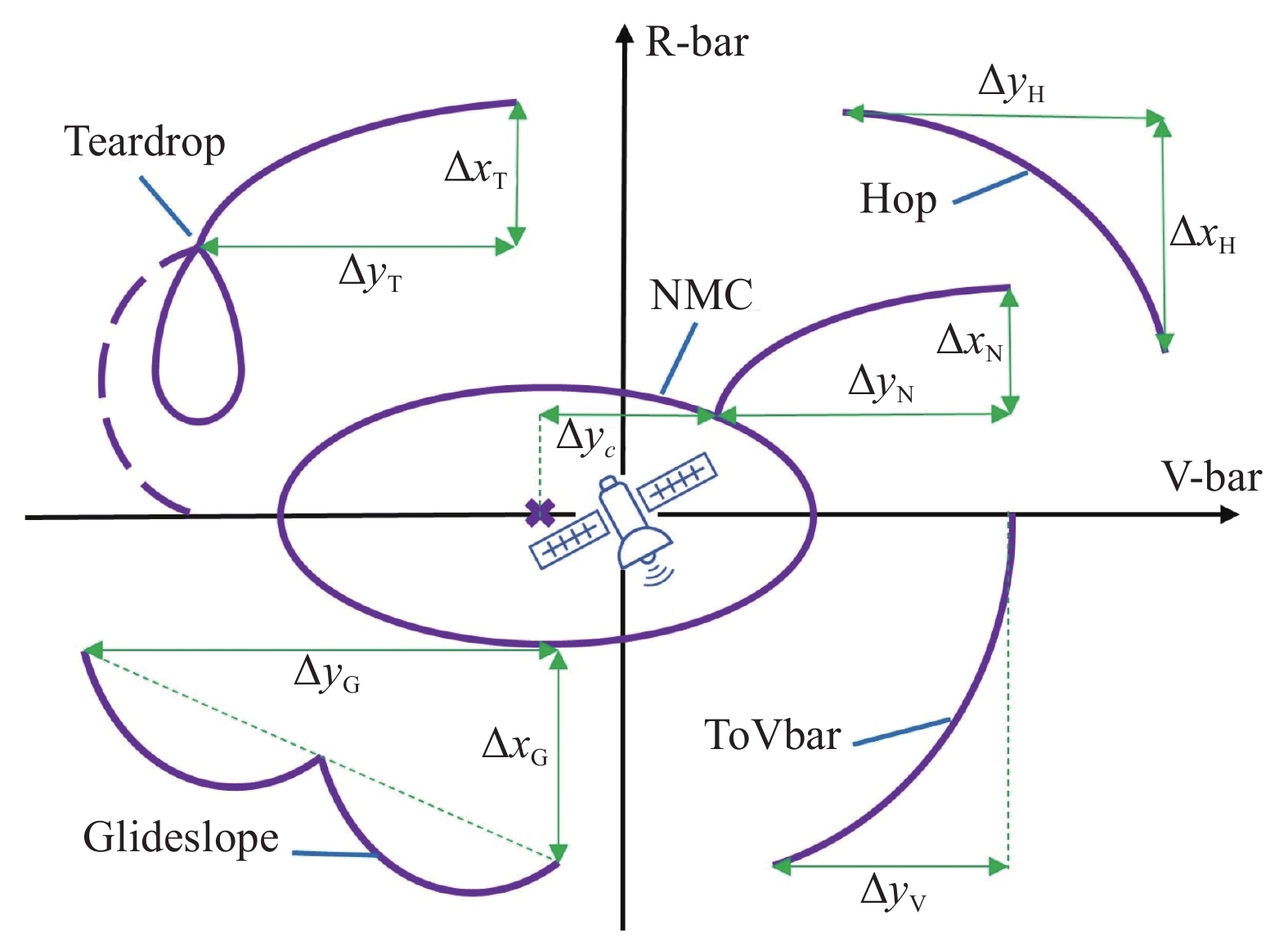
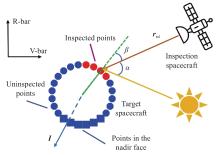
Fig 6
Geometry of the inspection reward model"
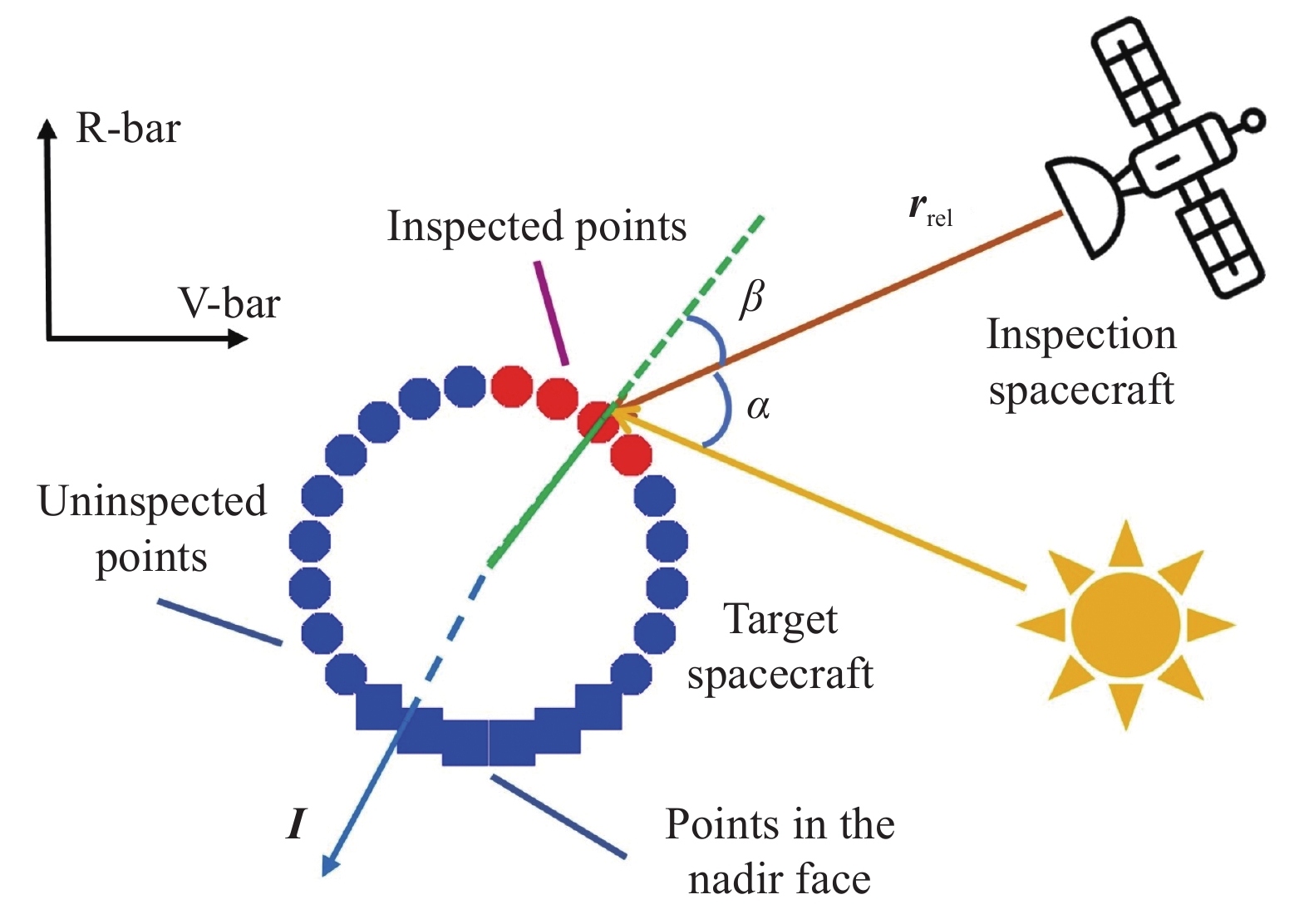
Table 6
Range of modules’ parameters"
| Module | Parameter | Range |
| Hop | [5(away from V-bar), 10(toward V-bar)] | |
| [−35, 35] | ||
| ToVbar | [1,5] | |
| [−12, 12] | ||
| Glideslope | [6(away from V-bar), 12(toward V-bar)] | |
| [−40, 40] | ||
| NMC | [−5, 5] | |
| [−10, 10] | ||
| [−25, 25] | ||
| Teardrop | [4,8] | |
| [0, 7(toward V-bar)] | ||
| [−12, 12] |
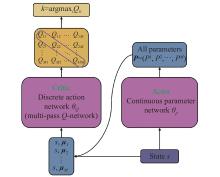
Fig 7
MPDQN network architecture"
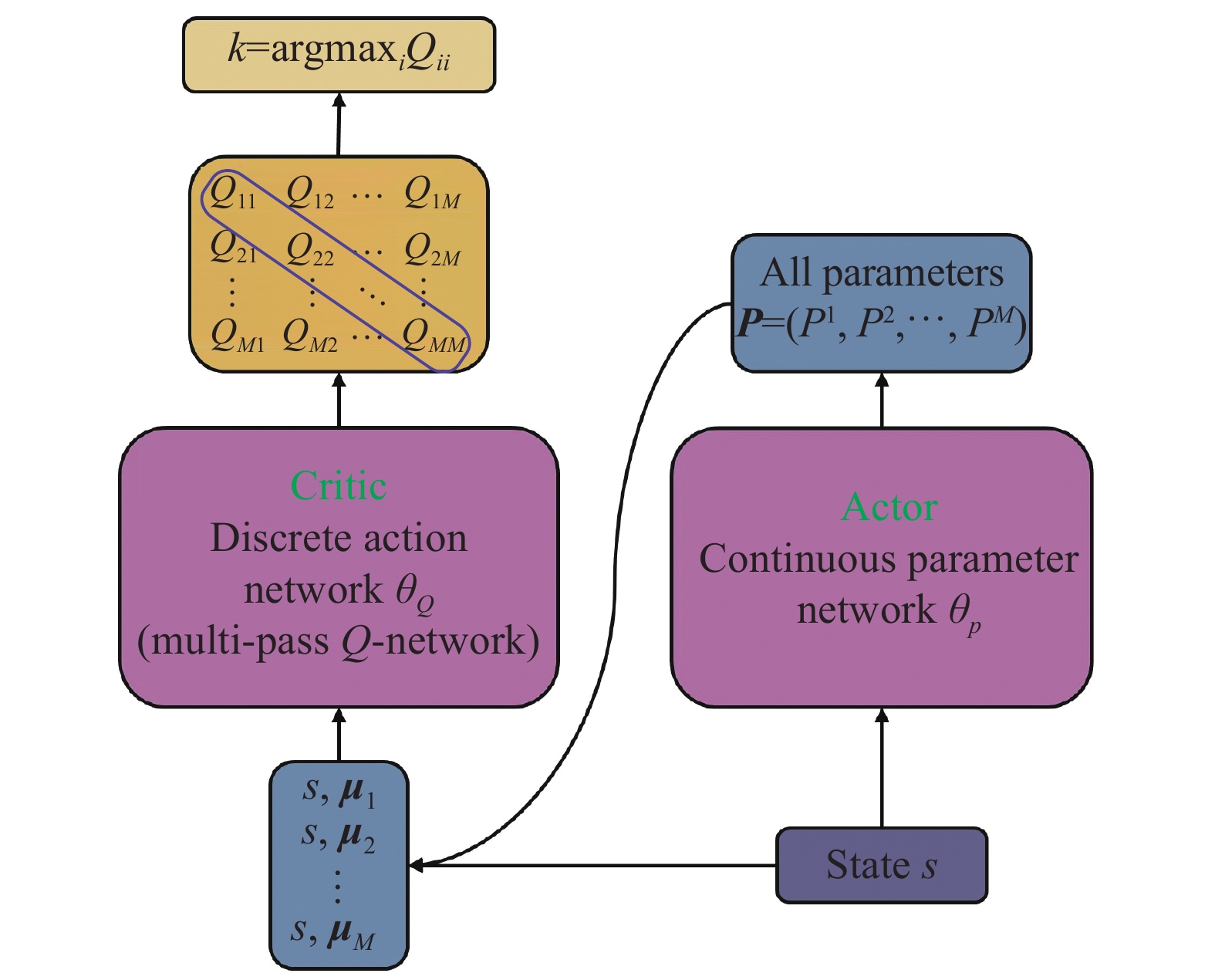
Table 2
Structure of the continuous parameter network"
| Layer name | Node | Activation function |
| Input layer | 7 | Leaky ReLU |
| Hidden layers | (64,64,128,128) | Leaky ReLU |
| Output layer | 12 | Leaky ReLU |
Table 3
Structure of the discrete action network"
| Layer name | Node | Activation function |
| Input layer | 19 | Leaky ReLU |
| Hidden layers | (64,64,128,128) | Leaky ReLU |
| Output layer | 5 | None |
Table 4
Training hyperparameter for MPDQN"
| Parameter | Value |
| Learning rate of discrete action network | |
| Learning rate of continuous parameter network | |
| Update rate of discrete action network | 0.005 |
| Update rate of continuous parameter network | 0.001 |
| Discount factor | 0.9 |
| Gradient clipping | 1 |
| Batch size | 256 |
Table 5
Parameters of the problem constraints"
| Parameter | Value |
| 10 | |
| 2.4 | |
| 50 | |
| 25 | |
| 100 |
Table 7
Parameters of inspection conditions"
| Parameter | Value |
| 15 | |
| −60 | |
| 60 | |
| −45 | |
| 45 | |
| 3 |
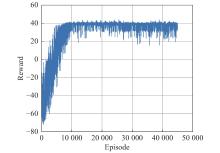
Fig 8
Curve of rewards over Curriculum 1"
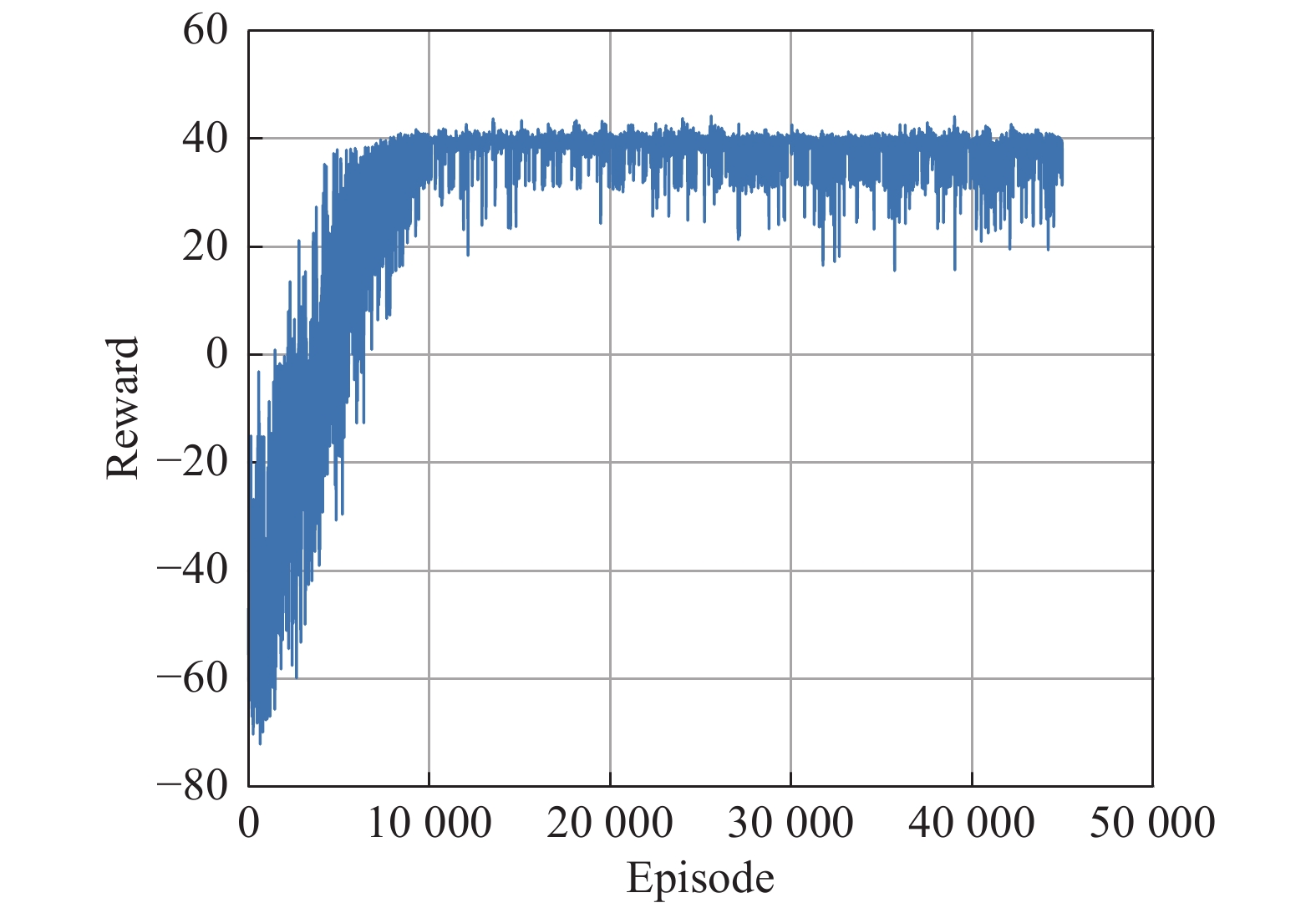
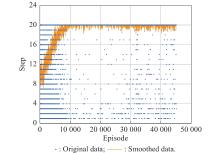
Fig 9
Curve of steps interacted per episode over Curriculum 1"
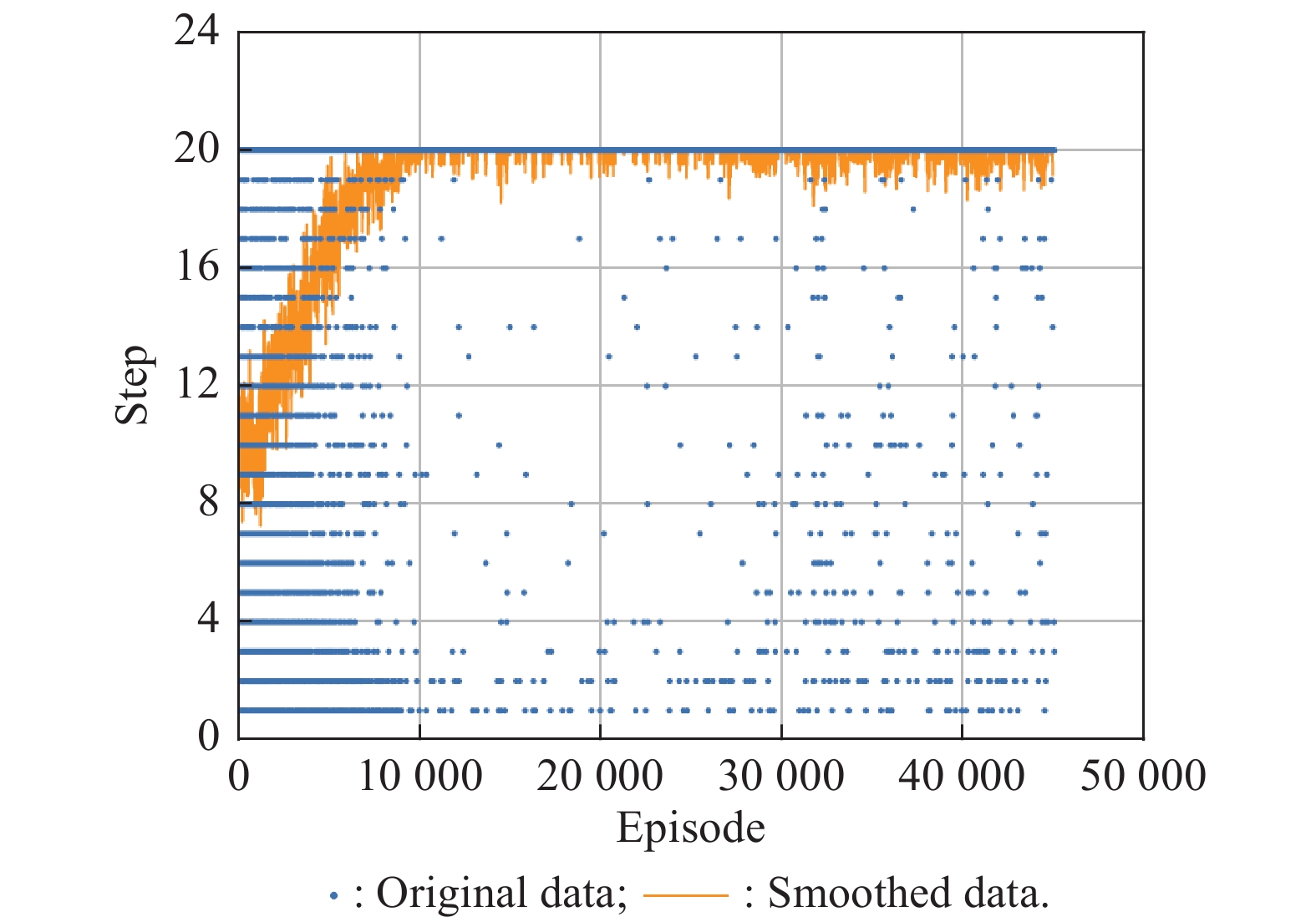

Fig 10
Stay around to opponent with ToVbar module"
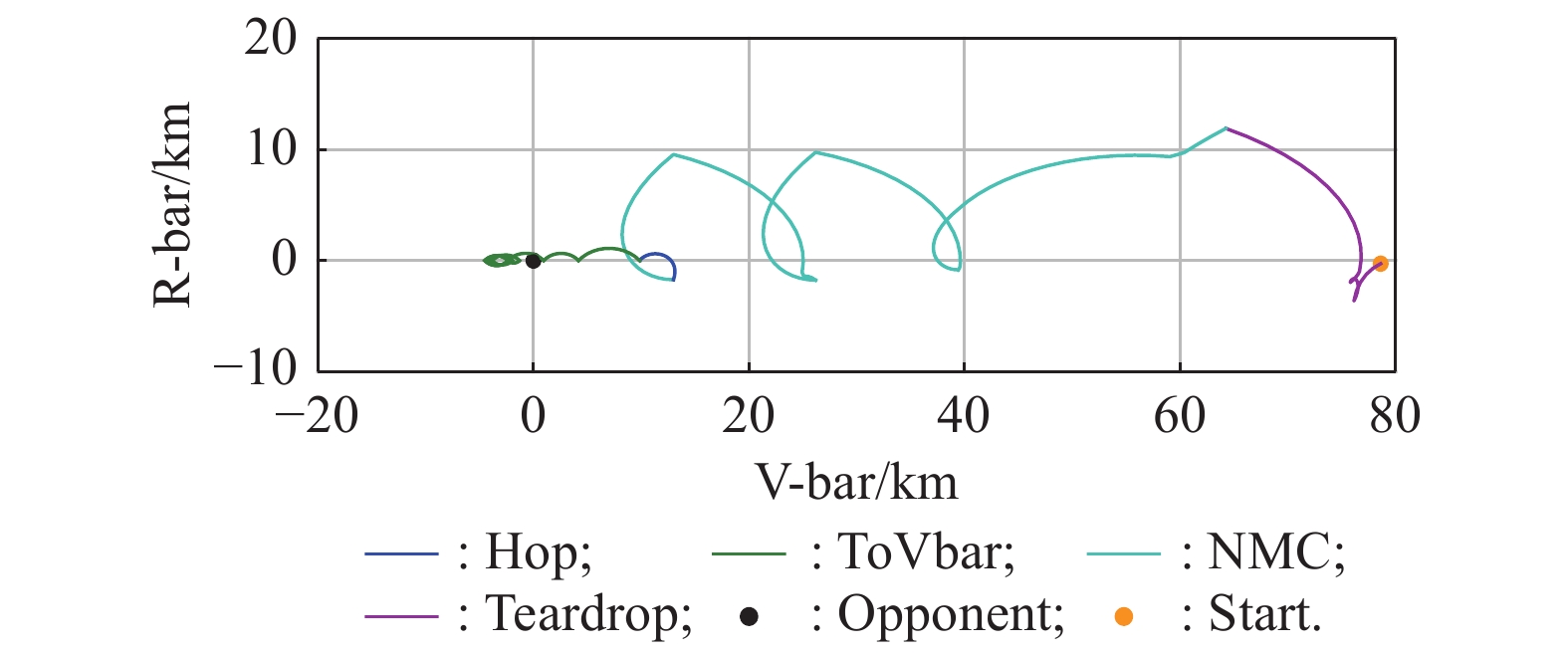
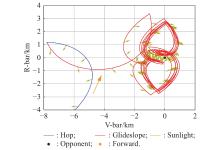
Fig 11
Petal-like trajectory formed by the ToVar"
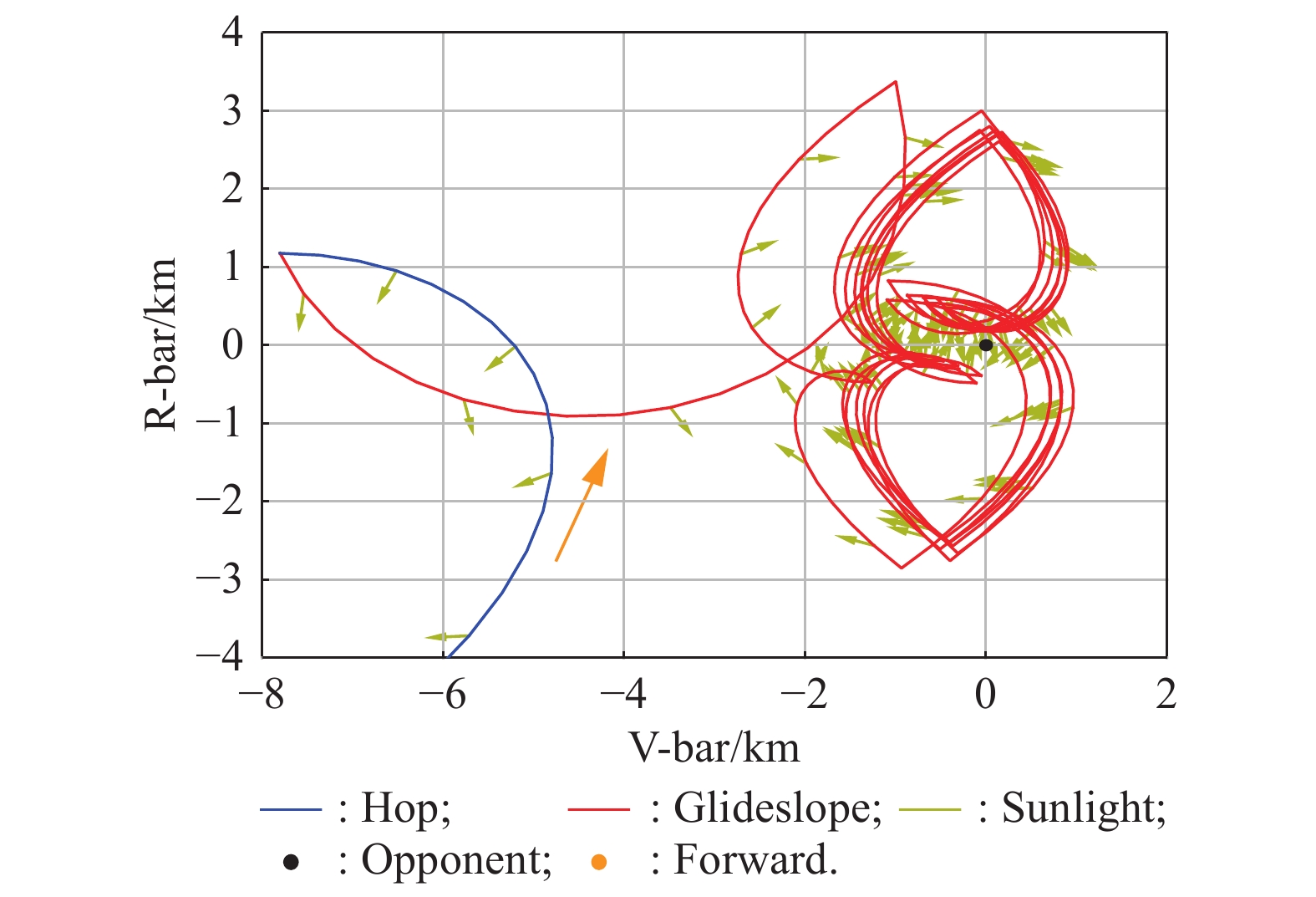
Fig 12
Fantastic circumnavigation"
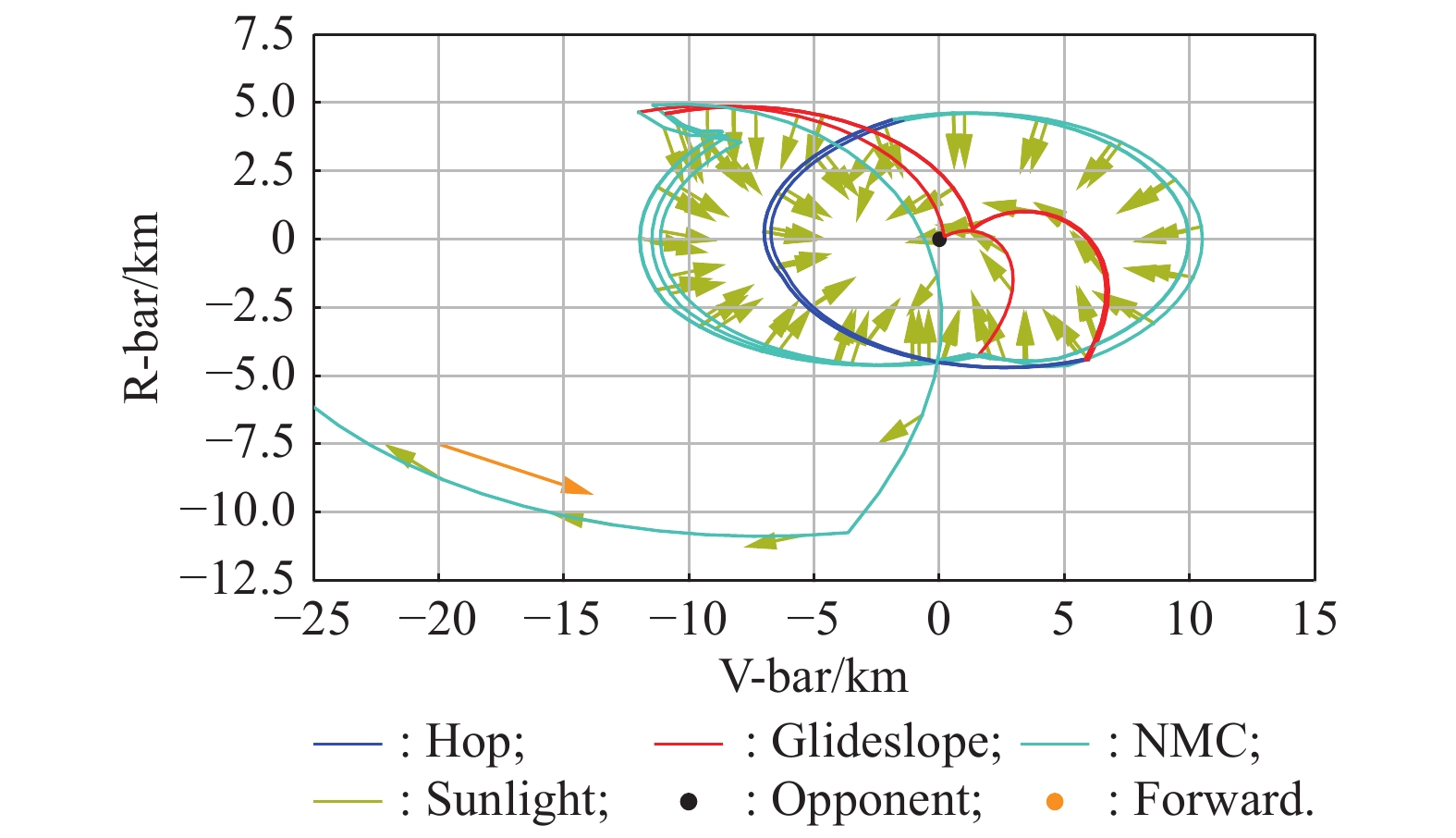
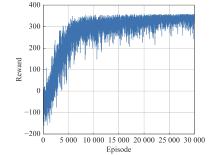
Fig 13
Curve of rewards over Curriculum 4"
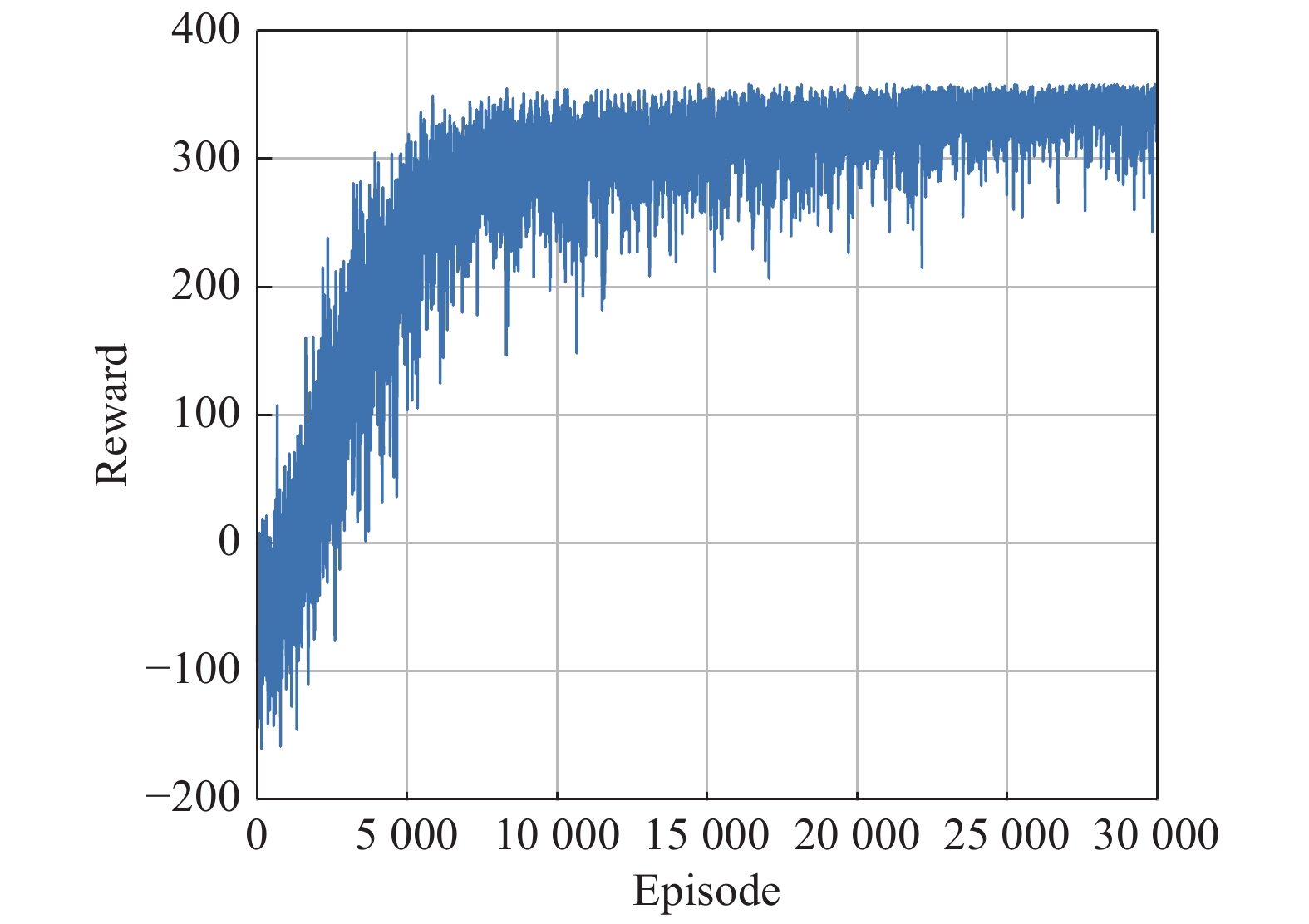
Fig 14
Best performance over Curriculum 4"
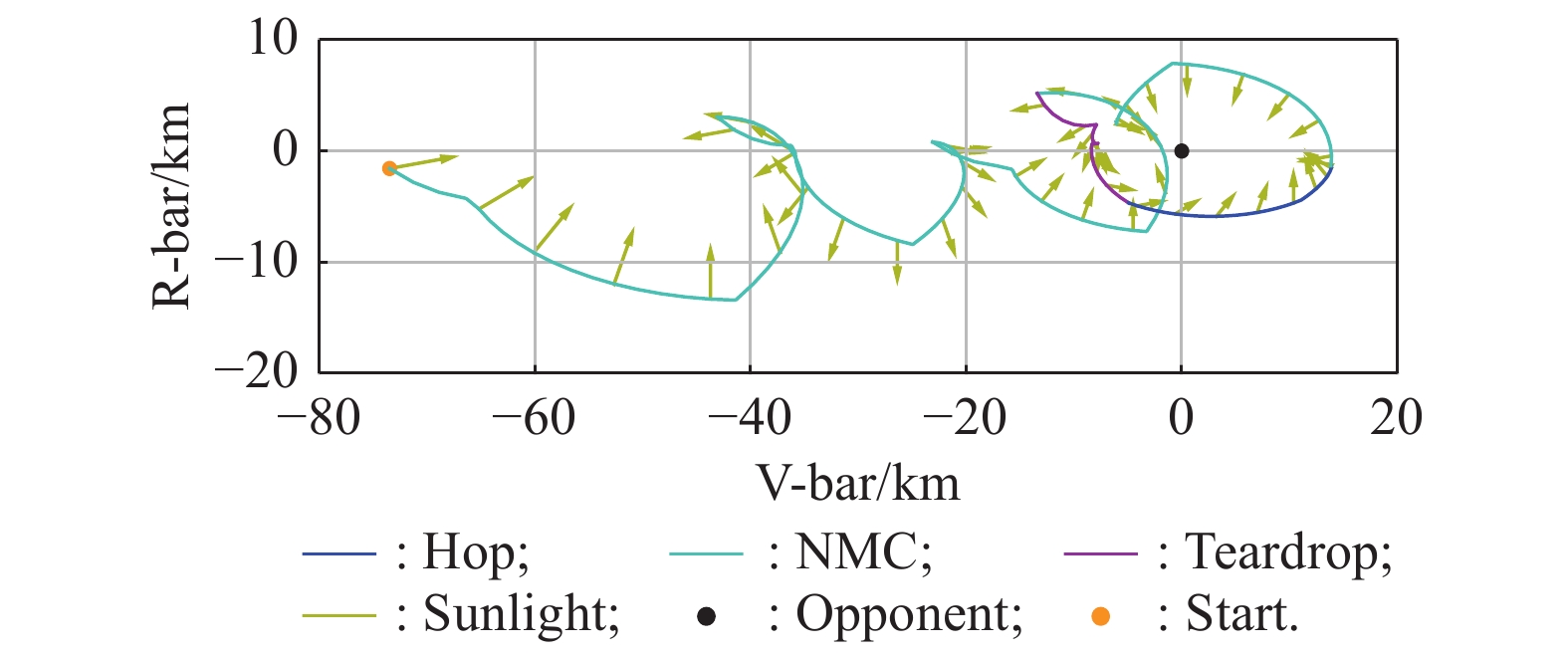
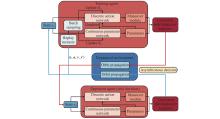
Fig 15
Game decision framework"
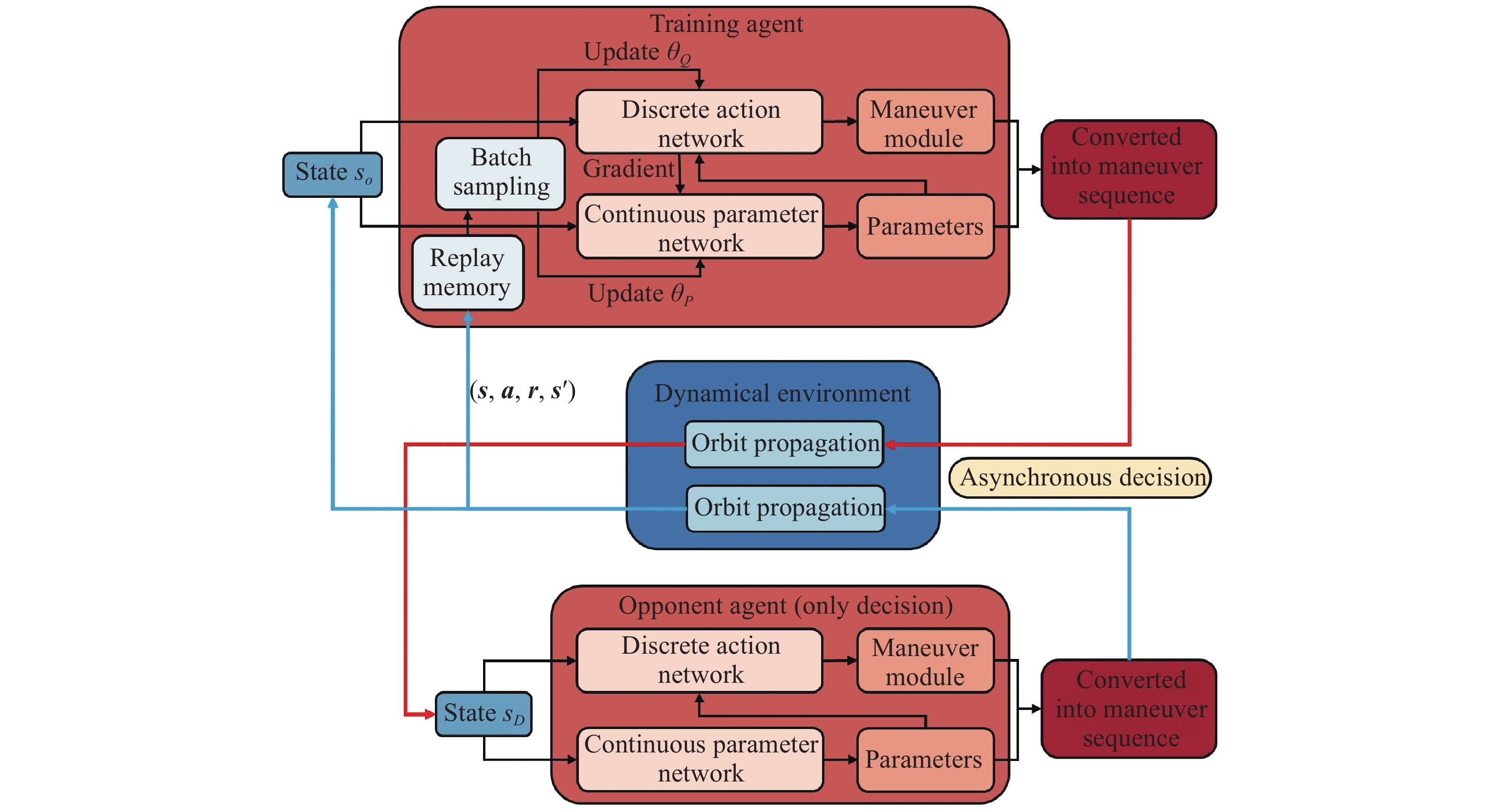
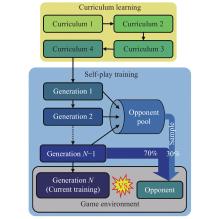
Fig 16
Training framework"
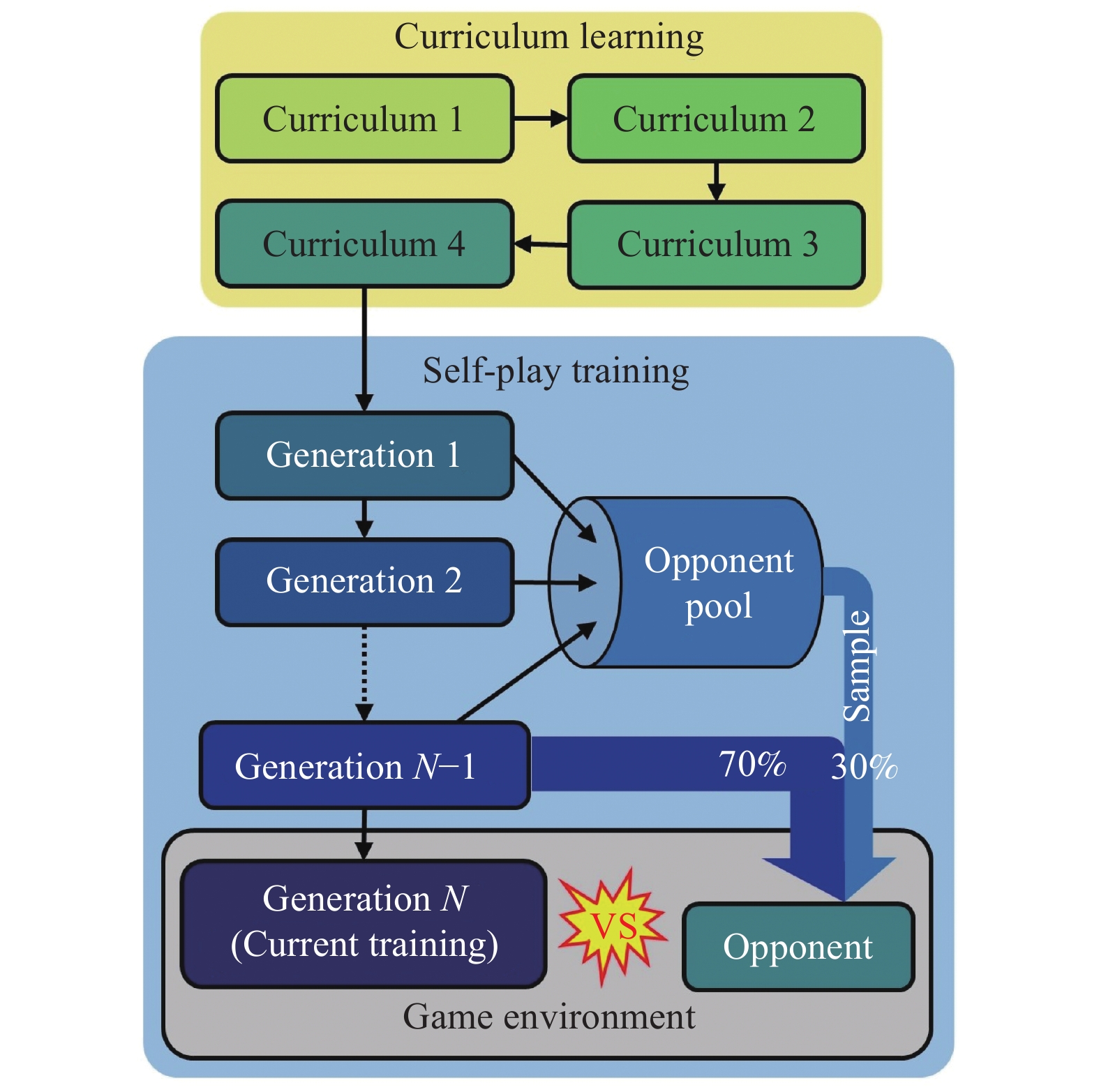
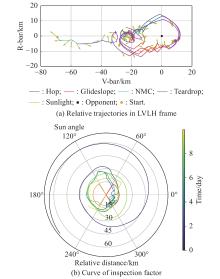
Fig 17
Multiple revolution circumnavigation inspection"
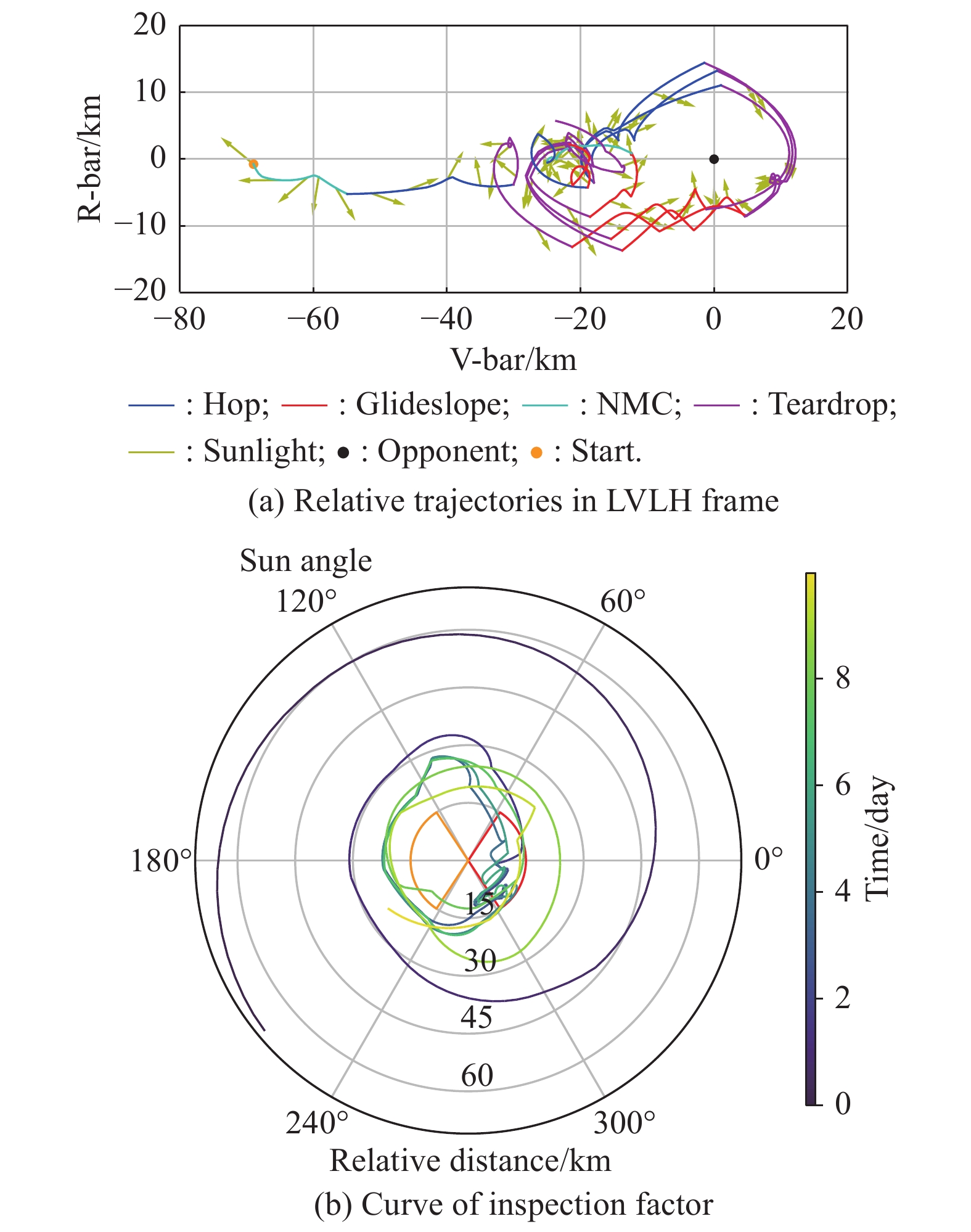
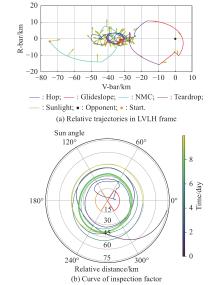
Fig 18
Single revolution circumnavigation inspection"
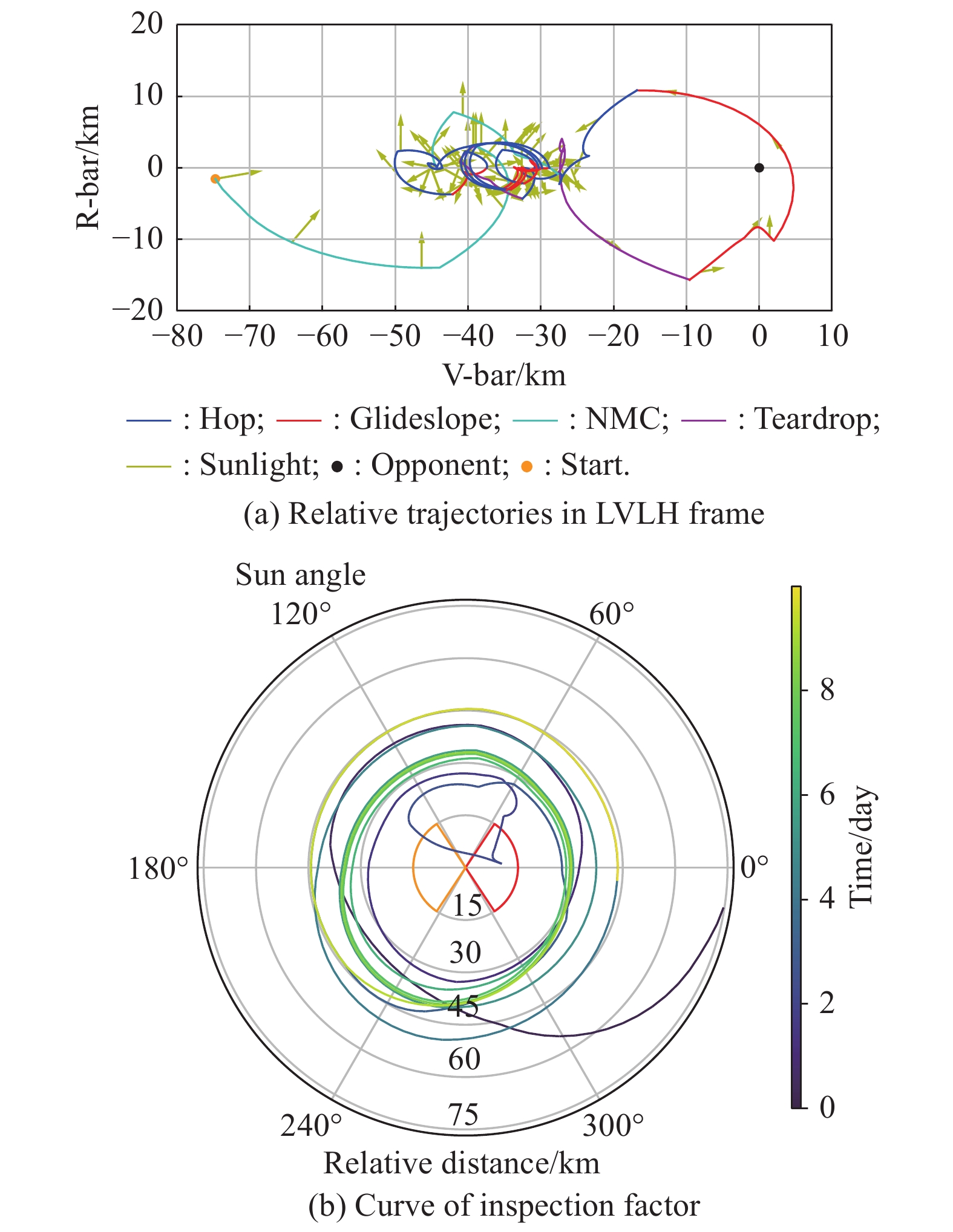
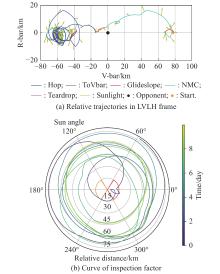
Fig 19
Flyby inspection"
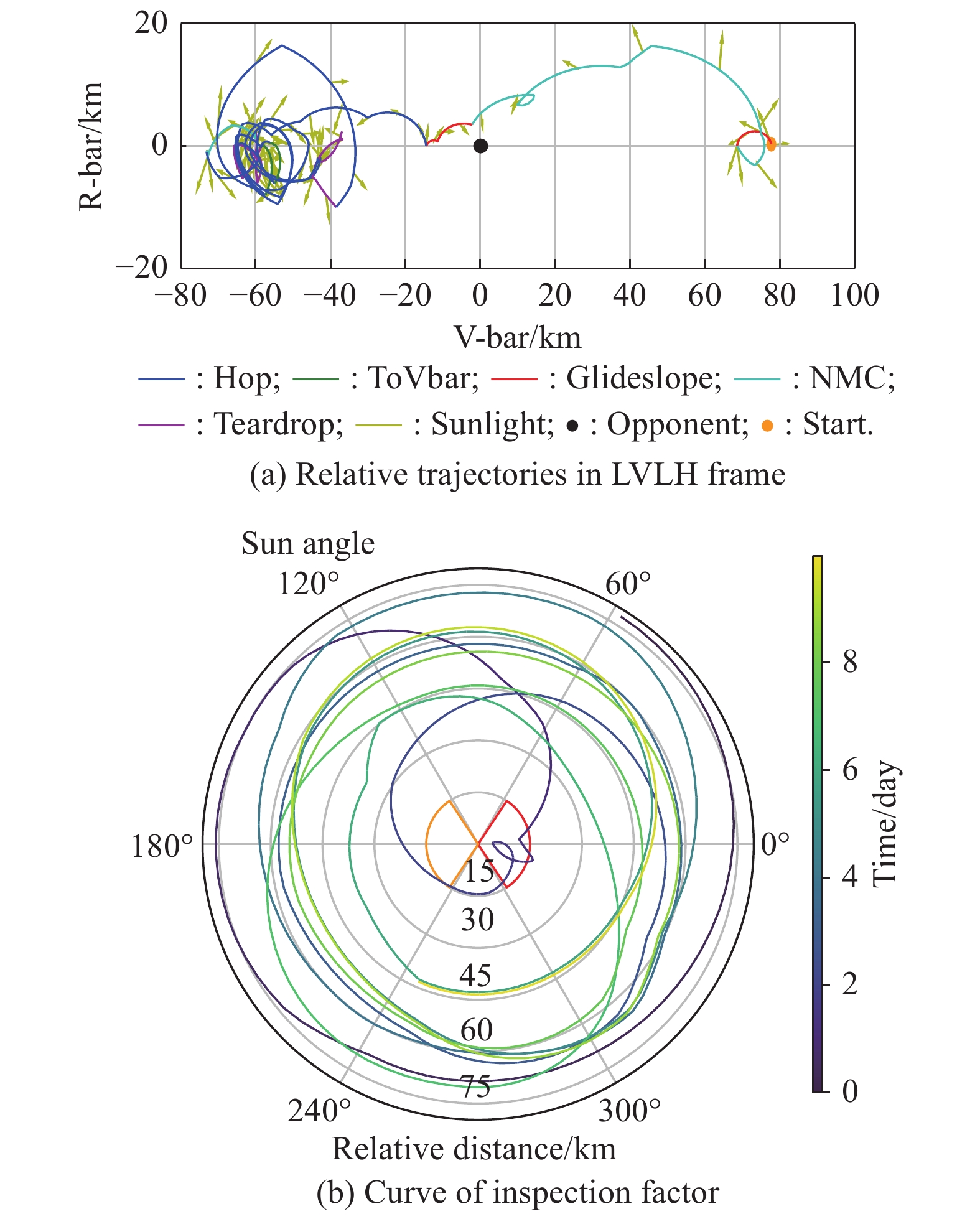
Fig 20
Stable periodic mode"
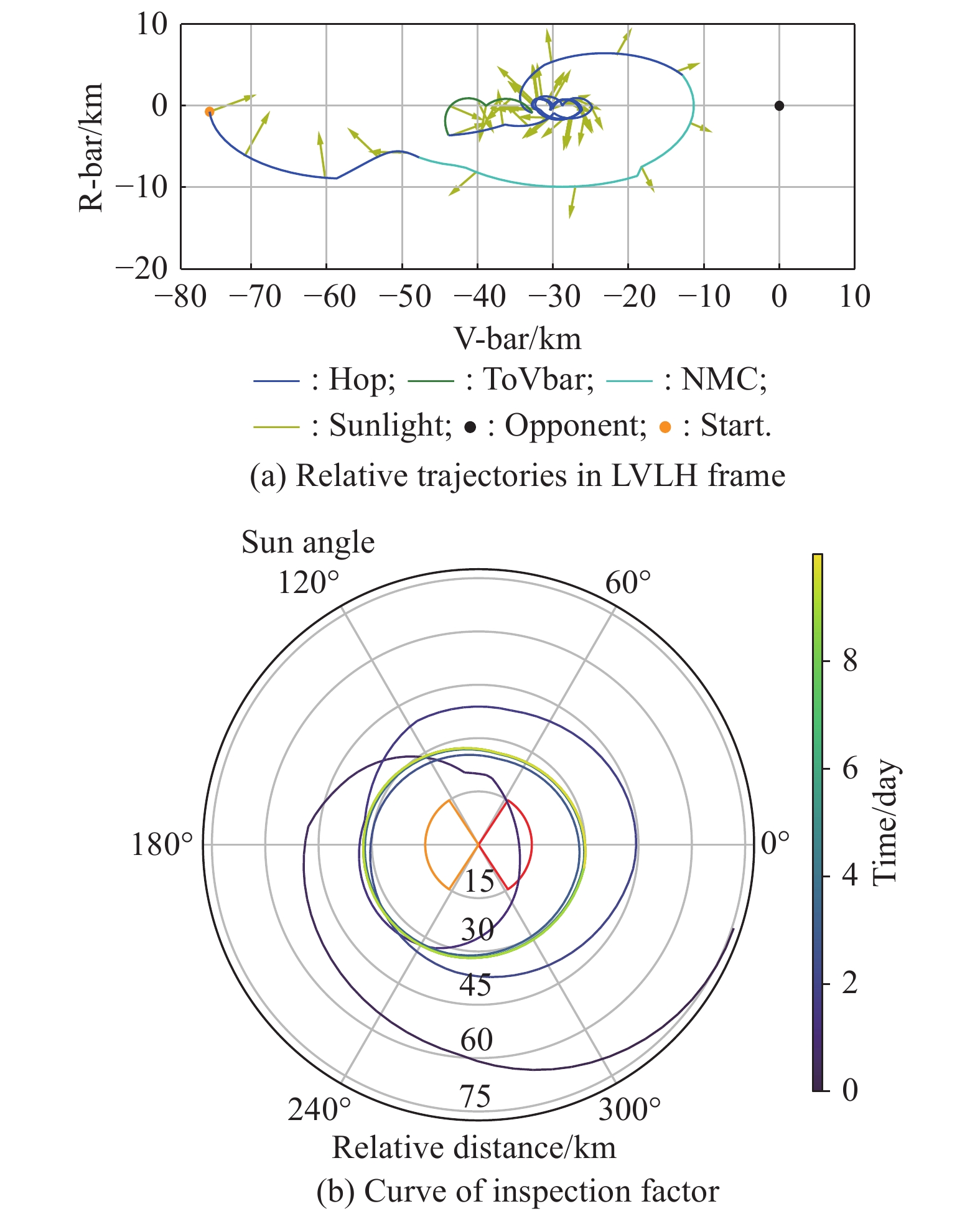

Fig 21
Another stable periodic mode"
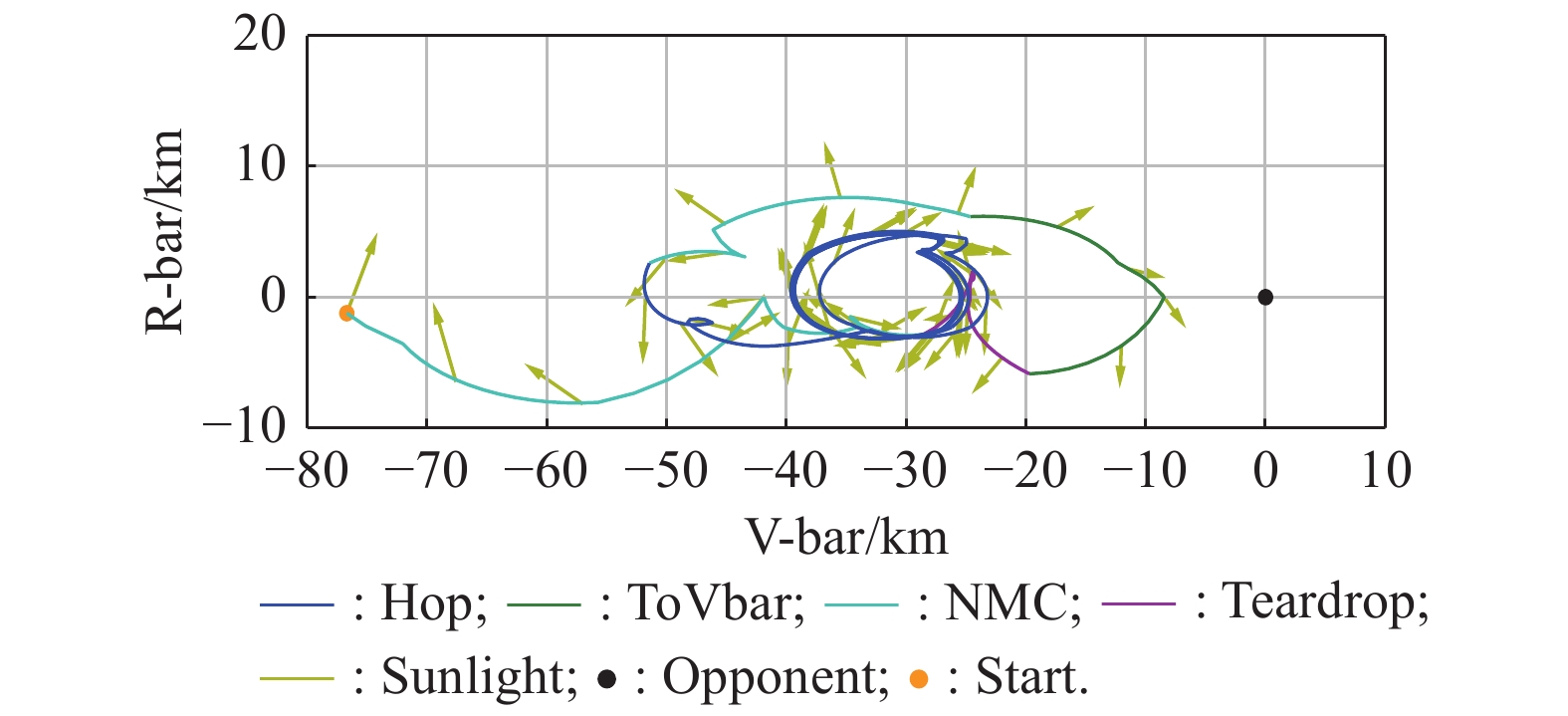
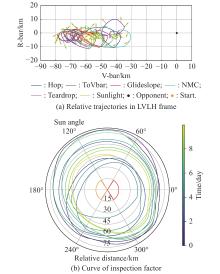
Fig 22
Extreme equilibrium phenomenon"

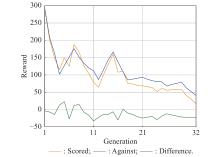
Fig 23
Variation of average rewards of main agent and opponent"
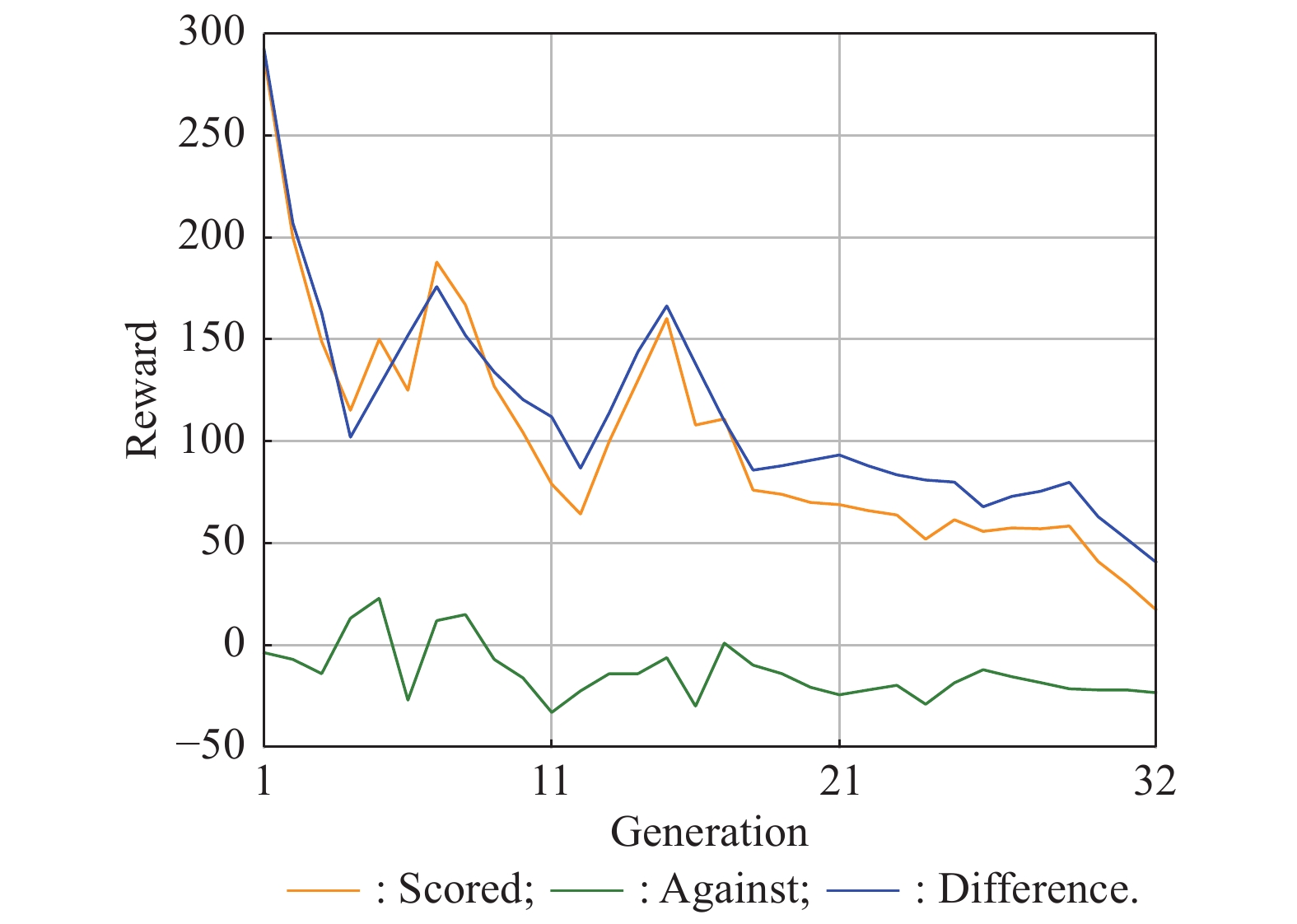
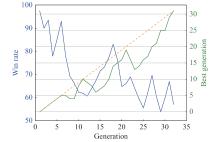
Fig 24
Variation of best past version and the main agent’s win rate against past version"
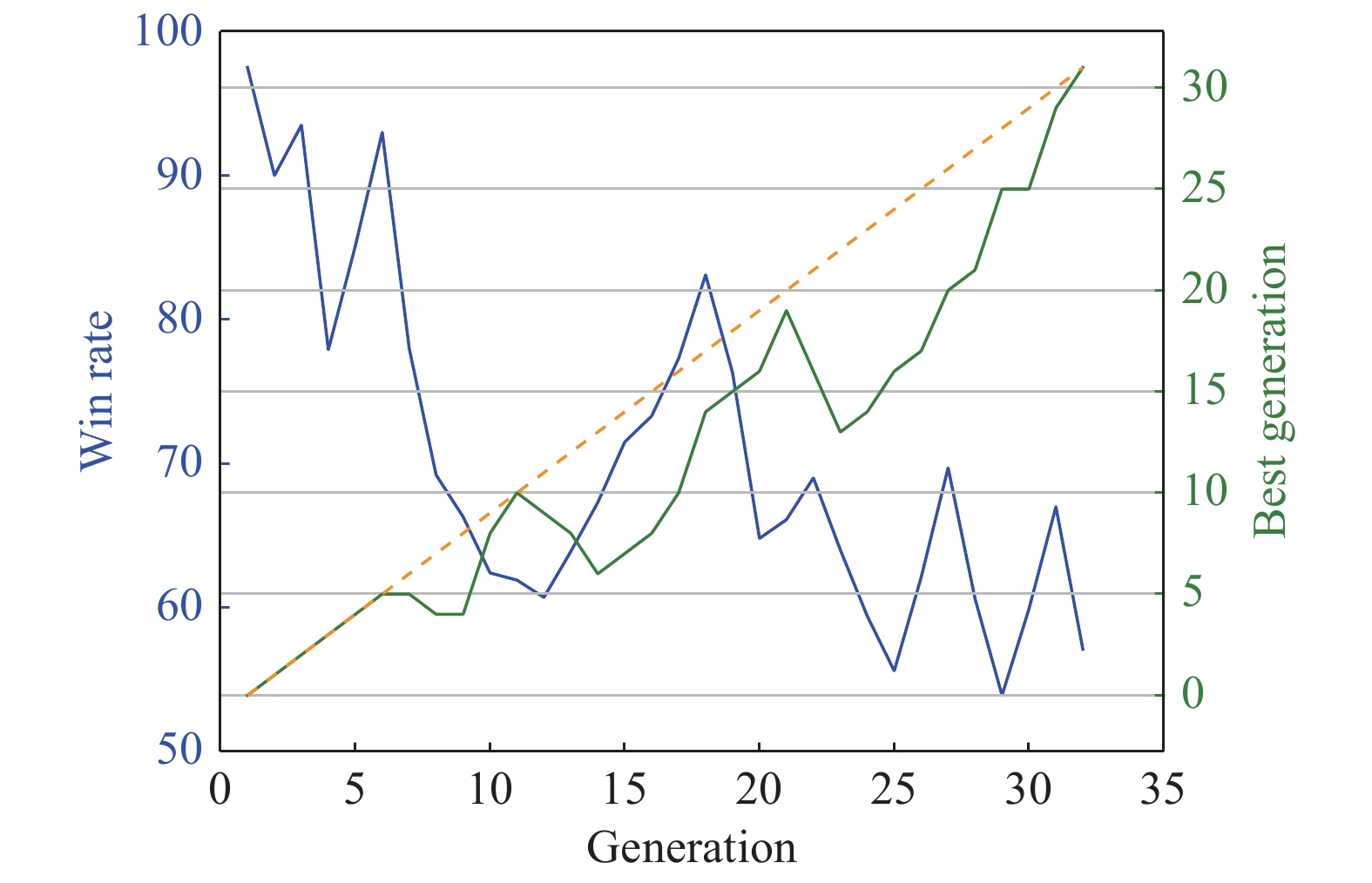
Fig 25
Variation in the usage ratio of each module"
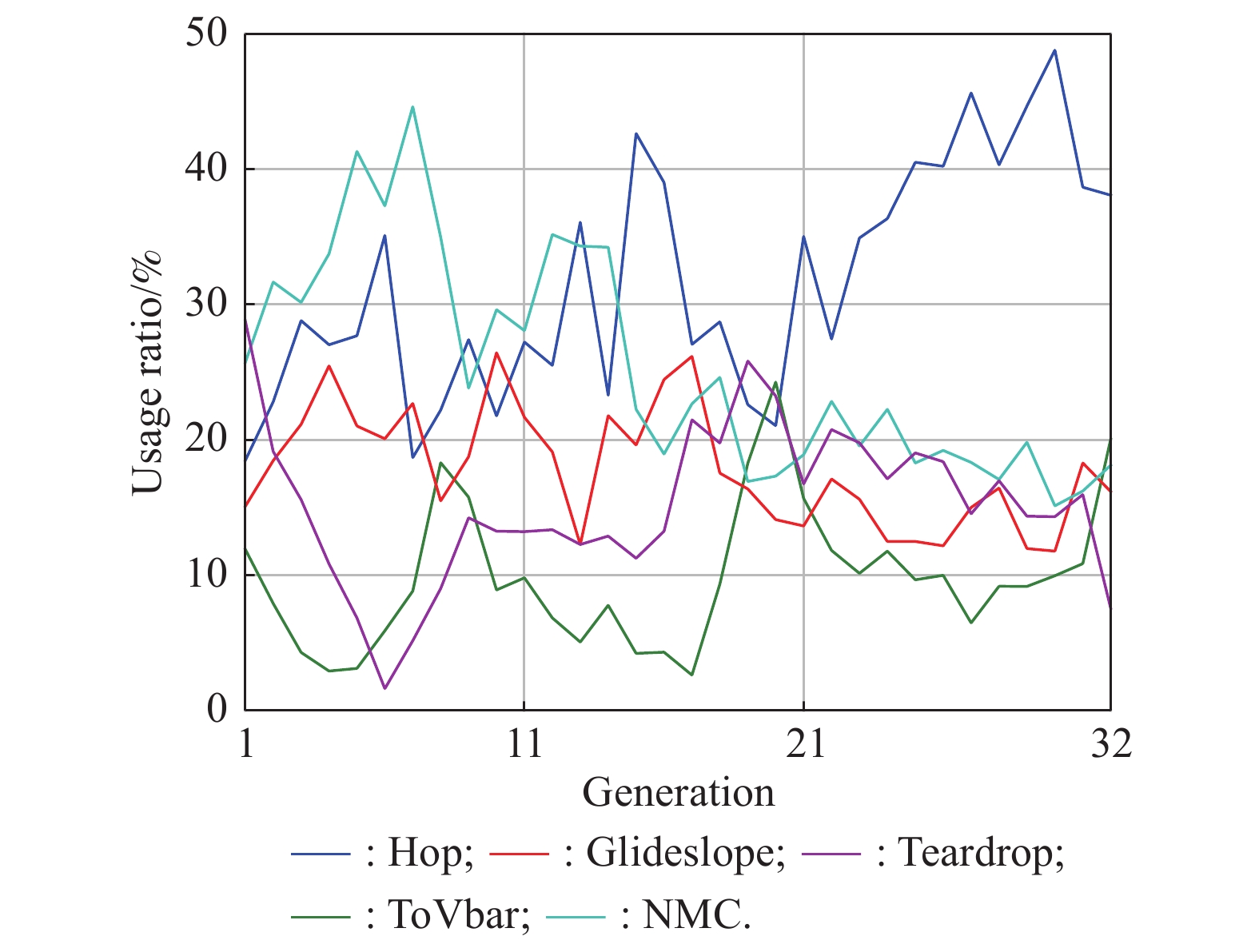
Table 8
Game results with different maximum terminal time"
| Terminal time/ day | Win rate/ % | Main agent’s reward | Opponents’ reward |
| 2.5 | 58.5 | 26.4 | −6.4 |
| 5 | 77.9 | 60.0 | −11.3 |
| 7.5 | 82.2 | 64.5 | −17.4 |
| 10 | 83.2 | 63.5 | −24.1 |
Table 9
Usage ratio of each module with different terminal time"
| Terminal time/ day | Module | ||||
| Hop | ToVbar | Glideslope | NMC | Teardrop | |
| 2.5 | 25.6 | 10.2 | 11.6 | 31.4 | 21.3 |
| 5 | 32.7 | 11.0 | 11.6 | 23.1 | 21.6 |
| 7.5 | 37.5 | 11.3 | 11.3 | 20.2 | 19.6 |
| 10 | 40.9 | 11.4 | 11.3 | 18.4 | 17.9 |
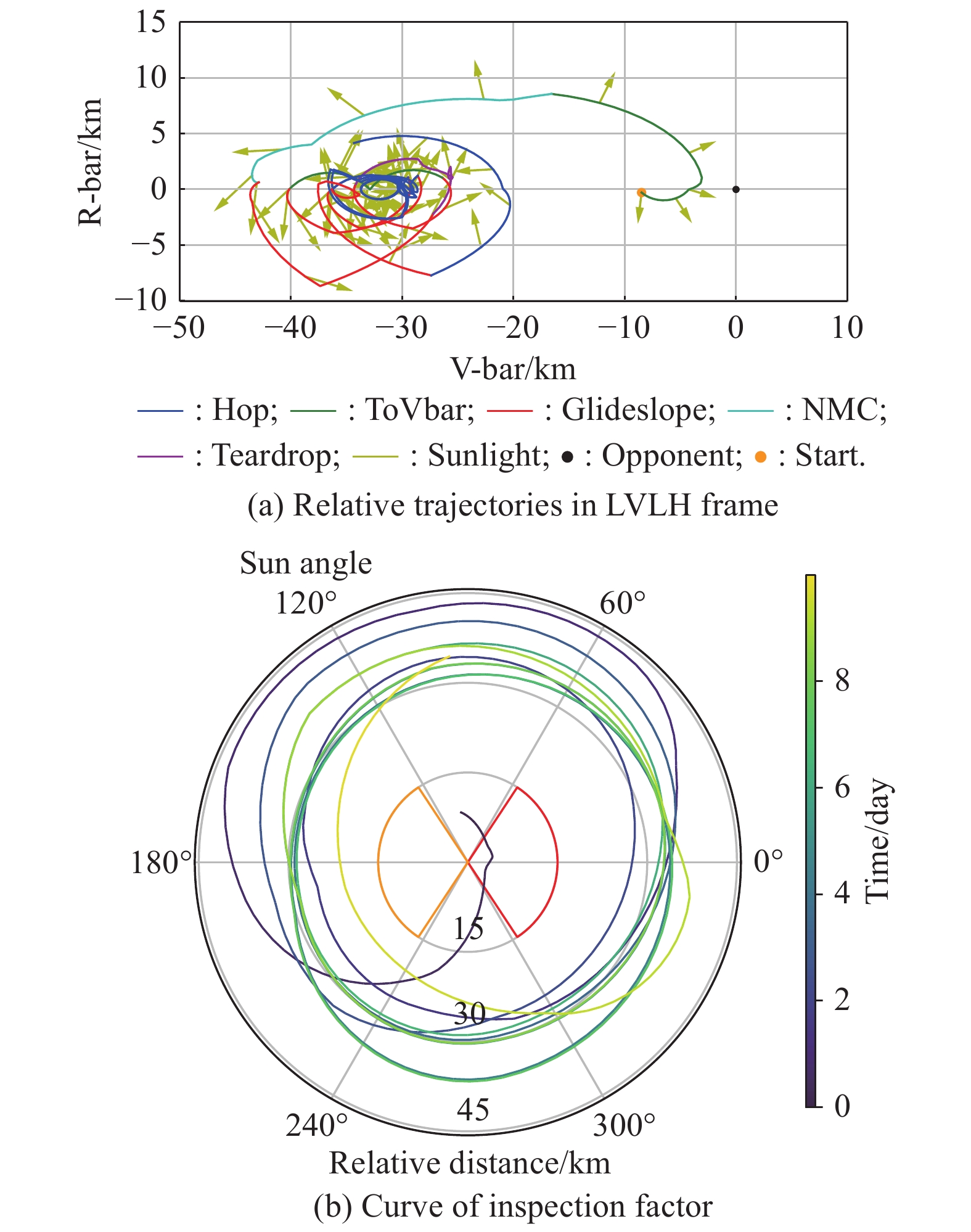
Fig 26
Conservative strategy"
| 1 | WU L J, ZHONG W C, LI W L, et al The modular relative orbit design method for spacecraft proximity motion. Journal of Physics: Conference Series, 2022, 2252 (1): 12- 32. |
| 2 | ZHU R Z, TANG Y Design methods for the closing and fly-around of space rendezvous. Chinese Space Science and Technology, 2005, 25 (1): 7- 14. |
| 3 | ZHAO G D, GUO Y N, DENG W D, et al. Natural fly-around orbital maneuvers strategy for geo spacecraft considering illumination constraints. Proc. of the Chinese Control Conference, 2019: 8182−8187. |
| 4 | PAN Y Study on spacecraft relative drip-drop hovering orbit. Spacecraft Engineering, 2014, 23 (4): 13- 18. |
| 5 | YE D, SHI M M, SUN Z W. Satellite proximate pursuit-evasion game with different thrust configurations. Aerospace Science and Technology, 2020, 99: 105715. |
| 6 |
SHI M M, YE D, SUN Z W, et al Spacecraft orbital pursuit–evasion games with J2 perturbations and direction-constrained thrust. Acta Astronautica, 2023, 202, 139- 150.
doi: 10.1016/j.actaastro.2022.10.004 |
| 7 | XIE W Y, ZHAO L R, DANG Z H. Game tree search-based impulsive orbital pursuit-evasion game with limited actions. Space: Science & Technology, 2024, 4: 87−99. |
| 8 | HAN H, DANG Z. Optimal delta-V-based strategies in orbital pursuit-evasion games. Advances in Space Research. 2023, 72(2): 243−256. |
| 9 |
LI Z Y, ZHU H, LUO Y Z Orbital inspection game formulation and epsilon-Nash equilibrium solution. Journal of Spacecraft and Rockets, 2024, 61 (1): 157- 172.
doi: 10.2514/1.A35800 |
| 10 | BRANDONISIO A, LAVAGNA M, GUZZETTI D. Reinforcement learning for uncooperative space objects smart imaging path-planning. The Journal of the Astronautical Sciences, 2021, 68(4): 1145−1169. |
| 11 |
SILVER D, HUANG A, MADDISON C J, et al Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529 (7587): 484- 489.
doi: 10.1038/nature16961 |
| 12 |
SILVER D, SCHRITTWIESER J, SIMONYAN K, et al Mastering the game of Go without human knowledge. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270 |
| 13 |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575 (7782): 350- 354.
doi: 10.1038/s41586-019-1724-z |
| 14 | XIONG J C, WANG Q, YANG Z R, et al. Parametrized deep Q-networks learning: reinforcement learning with discrete-continuous hybrid action space. https://arXiv.org/abs/1810.06394. |
| 15 | BESTER C J, STEVEN D J, GEORGE D K. Multi-pass q-networks for deep reinforcement learning with parameterised action spaces. https://arXiv.org/abs/1905.04388. |
| 16 | HAUSKNECHT M, STONE P. Deep reinforcement learning in parameterized action space. https://arXiv.org/abs/1511.04143. |
| 17 | FAN Z, SU R, ZHANG W, et al. Hybrid actor-critic reinforcement learning in parameterized action space. Proc. of the 28th International Joint Conference on Artificial Intelligence, 2019: 2279−2285. |
| 18 |
WANG X, SHI P, ZHAO Y S, et al A pre-trained fuzzy reinforcement learning method for the pursuing satellite in a one-to-one game in space. Sensors, 2020, 20 (8): 2253- 2268.
doi: 10.3390/s20082253 |
| 19 |
YANG B, LIU P X, FENG J L, et al Two-stage pursuit strategy for incomplete-information impulsive space pursuit-evasion mission using reinforcement learning. Aerospace, 2021, 8 (10): 299- 315.
doi: 10.3390/aerospace8100299 |
| 20 |
ZHAO L R, ZHANG Y L, DANG Z H PRD-MADDPG: an efficient learning-based algorithm for orbital pursuit-evasion game with impulsive maneuvers. Advances in Space Research, 2023, 72 (2): 211- 230.
doi: 10.1016/j.asr.2023.03.014 |
| 21 | JIANG R, YE D, XIAO Y, et al. Orbital interception pursuit strategy for random evasion using deep reinforcement learning. Space: Science & Technology, 2023, 3: 86−99. |
| 22 | ALFRIEND K, VADALI S R, GURFIL P, et al. Spacecraft formation flying: dynamics, control and navigation. Oxford: Elsevier, 2009. |
| 23 |
CLOHESSY W H, WILTSHIRE R S Terminal guidance system for satellite rendezvous. Journal of Aerospace Sciences, 1960, 27 (9): 653- 658.
doi: 10.2514/8.8704 |
| 24 | VAN OTTERLO M, WIERING M. Reinforcement learning: state-of-the-art. New York: Springer Science & Business Media, 2012. |
| 25 | Ansys Government Initiatives. Introduction to rendezvous and proximity operation sequences in STK. https://help.agi.com/stk/index.htm#gator/rpo_intro.htm#Config. |
| 26 | MASSON W, RANCHOD P, KONIDARIS G. Reinforcement learning with parameterized actions. Proc. of the AAAI Conference on Artificial Intelligence, 2016: 1934−1940. |
| 27 | HUANG S, ONTANON S. A closer look at invalid action masking in m gradient algorithms. https://arXiv.org/abs/2006.14171. |
| 28 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning. https://arXiv.org/abs/1312.5602. |
| 29 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning. https://arXiv.org/abs/1509.02971. |
| 30 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction. Cambridge: MIT Press, 2018. |
| 31 | NARVEKAR S, PENG B, LEONETTI M, et al Curriculum learning for reinforcement learning domains: a framework and survey. Journal of Machine Learning Research, 2020, 21 (181): 1- 50. |
| 32 | HERNANDEZ D, DENAMGANAI K, GAO Y, et al. A generalized framework for self-play training. Proc. of the IEEE Conference on Games, 2019: 1−8. |
| 33 | BALDUZZI D, GARNELO M, BACHRACH Y, et al. Open-ended learning in symmetric zero-sum games. Proc. of the International Conference on Machine Learning, 2019: 434−443. |
| 34 | BERNER C, BROCKMAN G, CHAN B, et al. Dota 2 with large scale deep reinforcement learning. https://arXiv.org/abs/1912.06680. |
| [1] | Wenhao CHEN, Gang CHEN, Jichao LI, Jiang JIANG. Disintegration of heterogeneous combat network based on double deep Q-learning [J]. Journal of Systems Engineering and Electronics, 2025, 36(5): 1235-1246. |
| [2] | Siyu HENG, Ting CHENG, Zishu HE, Yuanqing WANG, Luqing LIU. Adaptive dwell scheduling based on Q-learning for multifunctional radar system [J]. Journal of Systems Engineering and Electronics, 2025, 36(4): 985-993. |
| [3] | Yifan ZHANG, Tao DONG, Zhihui LIU, Shichao JIN. Multi-QoS routing algorithm based on reinforcement learning for LEO satellite networks [J]. Journal of Systems Engineering and Electronics, 2025, 36(1): 37-47. |
| [4] | Nanxun DUO, Qinzhao WANG, Qiang LYU, Wei WANG. Tactical reward shaping for large-scale combat by multi-agent reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1516-1529. |
| [5] | Guofei LI, Shituo LI, Bohao LI, Yunjie WU. Deep reinforcement learning guidance with impact time control [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1594-1603. |
| [6] | Qi WANG, Zhizhong LIAO. Computational intelligence interception guidance law using online off-policy integral reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(4): 1042-1052. |
| [7] | Guang ZHAN, Kun ZHANG, Ke LI, Haiyin PIAO. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience [J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 644-665. |
| [8] | Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224. |
| [9] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [10] | Yunxiu ZENG, Kai XU. Recognition and interfere deceptive behavior based on inverse reinforcement learning and game theory [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 270-288. |
| [11] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [12] | Lu DONG, Zichen HE, Chunwei SONG, Changyin SUN. A review of mobile robot motion planning methods: from classical motion planning workflows to reinforcement learning-based architectures [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 439-459. |
| [13] | Guangran CHENG, Lu DONG, Xin YUAN, Changyin SUN. Reinforcement learning-based scheduling of multi-battery energy storage system [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 117-128. |
| [14] | Peng LIU, Boyuan XIA, Zhiwei YANG, Jichao LI, Yuejin TAN. A deep reinforcement learning method for multi-stage equipment development planning in uncertain environments [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1159-1175. |
| [15] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||