
Journal of Systems Engineering and Electronics ›› 2025, Vol. 36 ›› Issue (6): 1692-1708.doi: 10.23919/JSEE.2025.000112
• CONTROL THEORY AND APPLICATION • Previous Articles
Shijie DENG1,*( ), Yingxin KOU1(), Maolong LYU2(), Zhanwu LI1(), An XU1()
), Yingxin KOU1(), Maolong LYU2(), Zhanwu LI1(), An XU1()
Received:2024-03-06
Online:2025-12-18
Published:2026-01-07
Contact:
Shijie DENG
E-mail:dengshijiesilence@163.com;kgykyx@hotmail.com;maolonglv@163.com;afeulzw@189.cn;18157494594@163.com
About author:Shijie DENG, Yingxin KOU, Maolong LYU, Zhanwu LI, An XU. λ-return-based aircraft maneuvering for terminal defense and positioning guidance strategies[J]. Journal of Systems Engineering and Electronics, 2025, 36(6): 1692-1708.
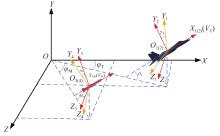
Fig 1
Coordinate system and angle diagram"
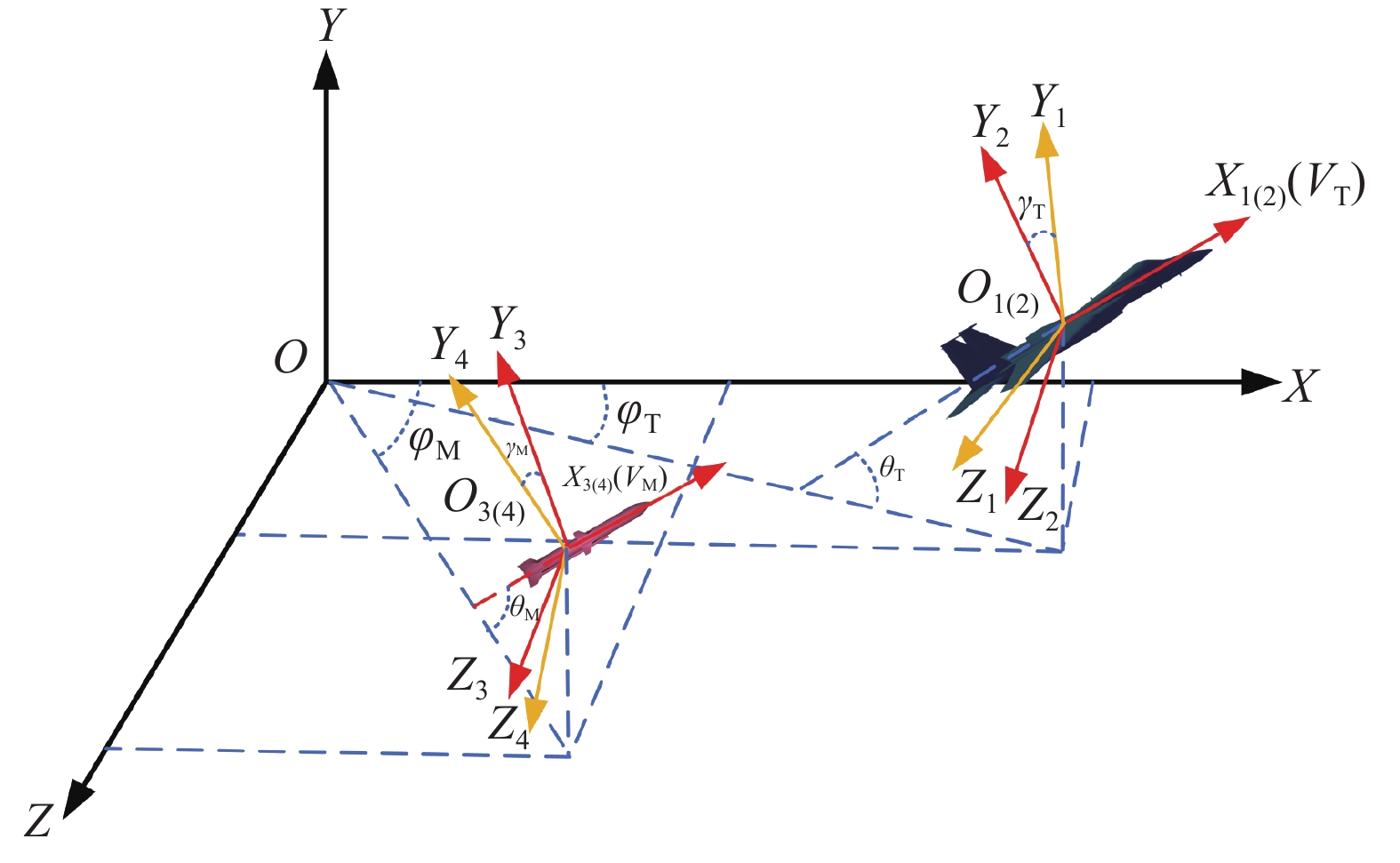
Table 1
Maneuver and its control variables"
| Number | Maneuver mode | Control quantity | ||
| 1 | Constant speed forward flight | 0 | 1 | 0 |
| 2 | Accelerated forward flight | 4 | 1 | 0 |
| 3 | Slow-speed forward flight | −4 | 1 | 0 |
| 4 | Turn right | 0 | 2 | |
| 5 | Turn left | 0 | 2 | |
| 6 | Accelerated dive | 4 | −5 | 0 |
| 7 | Accelerated climb | 4 | 7 | 0 |
| 8 | Deceleration dive | −4 | −5 | 0 |
| 9 | Slow down climb | −4 | 7 | 0 |
Table 2
Environmental model parameters"
| Parameter | Value | Illustration |
| 50 | Pitch overload limit | |
| 50 | Yaw overload limit | |
| 4 | Proportional guidance coefficient | |
| 0.3 | Indicating the maximum first-order time constant |

Fig 2
Principle demonstration of TD(λ)"
Fig 3
3DACTE training environment"
Table 3
Initial parameters of missile and aircraft"
| Object | X/m | Y/m | Z/m | V/(m/s) |
| Fighter | 0 | 0 | 300 | |
| Missile | − | 0 | ||
| Object | − | |||
| Fighter | 1 | 0 | 0 | − |
| Missile | 1 | 0 | 0 | − |
Table 4
Hyperparameters of DQN and λ-DQN algorithms"
| Hyperparameter | Value | Description |
| Input layer | 9 | Input state space dimension |
| Hidden layer 1 | 1e2 | Number of neurons in hidden layer 1 |
| Hidden layer 1 | 50 | Number of neurons in hidden layer 2 |
| Out layer | 9 | Output action space action number |
| Memory capacity | 2e4 | Only when the memory bank is full of data can the network start training |
| Minibatch size | 32 | The number of samples used during each training session |
| Learning rate | 1e-5 | The magnitude of parameter updates each time |
| Init exploration | 0.9 | Initial the value of ε in ε-greedy exploration |
| Final exploration | 0.3 | Final the value of ε in ε-greedy exploration |
| Gamma | 0.99 | Discount factor gamma used in the Q-learning update |
| Target network update frequency | 1e2 | The target network is updated once every 100 times the evaluation network is updated |
| Back step | 2 | The length of the storage queue for the illegal action blocking mechanism |
| λ | 0.8 | The λ value of the λ-return method |
Table 5
Hyperparameters of A2C and λ-A2C algorithms"
| Hyperparameter | Value | Description |
| Actor net input layer | 9 | “Actor” network input state space dimension |
| Actor net hidden layer | 1e2 | The number of hidden neurons in the “actor” network |
| Actor net out layer | 9 | Dimension of “actor” network output action probability |
| Critic net input layer | 9 | Dimension of network input state space for “critic” |
| Critic net hidden layer 1 | 1e2 | Number of neurons in the hidden layer 1 of the “commentator” network |
| Critic net hidden layer 2 | 50 | Number of neurons in the hidden layer 2 of the “commentator” network |
| Critic net out layer | 1 | Dimension of “critic” network output state estimation |
| Actor net learning rate | 1e-3 | Learning rate of the actor network |
| Critic net learning rate | 1e-3 | Learning rate of the “commentator” network |
| Back step | 2 | The length of the storage queue for the illegal action blocking mechanism |
| λ | 0.8 | The λ value of the λ-return method |
Table 6
Hyperparameters of PPO and λ-PPO algorithms"
| Hyperparameter | Value | Description |
| Actor net input layer | 9 | “Actor” network input state space dimension |
| Actor net hidden layer | 1e2 | The number of hidden neurons in the “actor” network |
| Actor net out layer | 9 | Dimension of “actor” network output action probability |
| Critic net input layer | 9 | Dimension of network input state space for “critic” |
| Critic net hidden layer 1 | 1e2 | Number of neurons in the hidden layer 1 of the “commentator” network |
| Critic net hidden layer 2 | 50 | Number of neurons in the hidden layer 2 of the “commentator” network |
| Critic net out layer | 1 | Dimension of “critic” network output state estimation |
| Actor net learning rate | 1e-4 | Learning rate of actor’s network |
| Critic net learning rate | 1e-3 | Learning rate of the “critic” network |
| 0.95 | Scaling factor of the dominance function | |
| N | 10 | Round of single-session training |
| 0.2 | Parameters of truncation range in PPO | |
| Back step | 2 | The length of the storage queue for the illegal action blocking mechanism |
| λ | 0.8 | The λ value of the λ-return method |
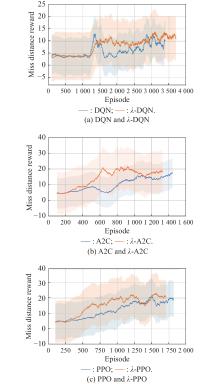
Fig 4
Training effect of different algorithms based on λ-return"
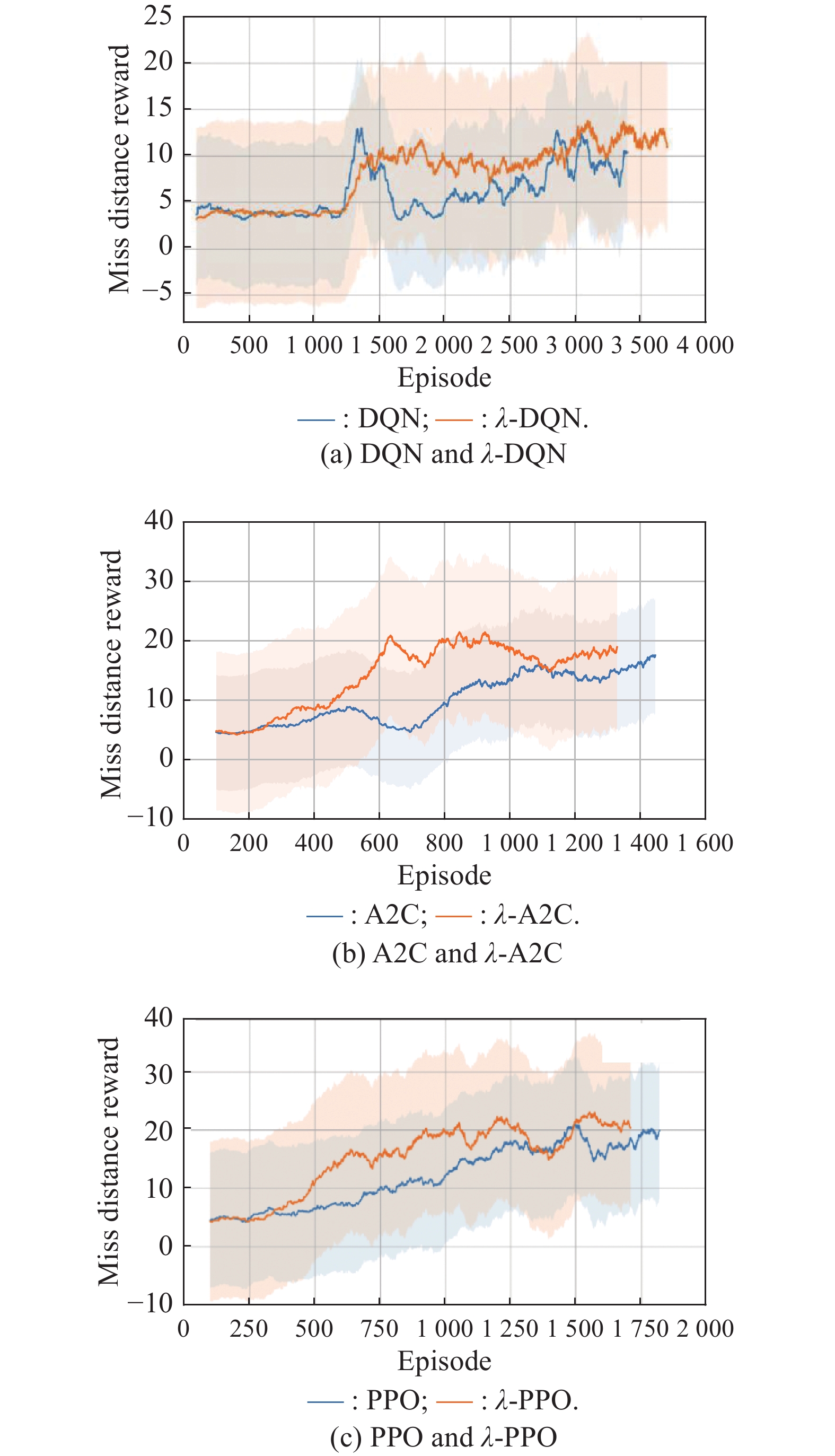
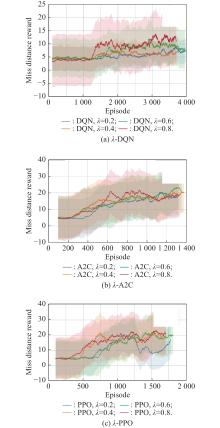
Fig 5
Training effect of different algorithms with different λ values"
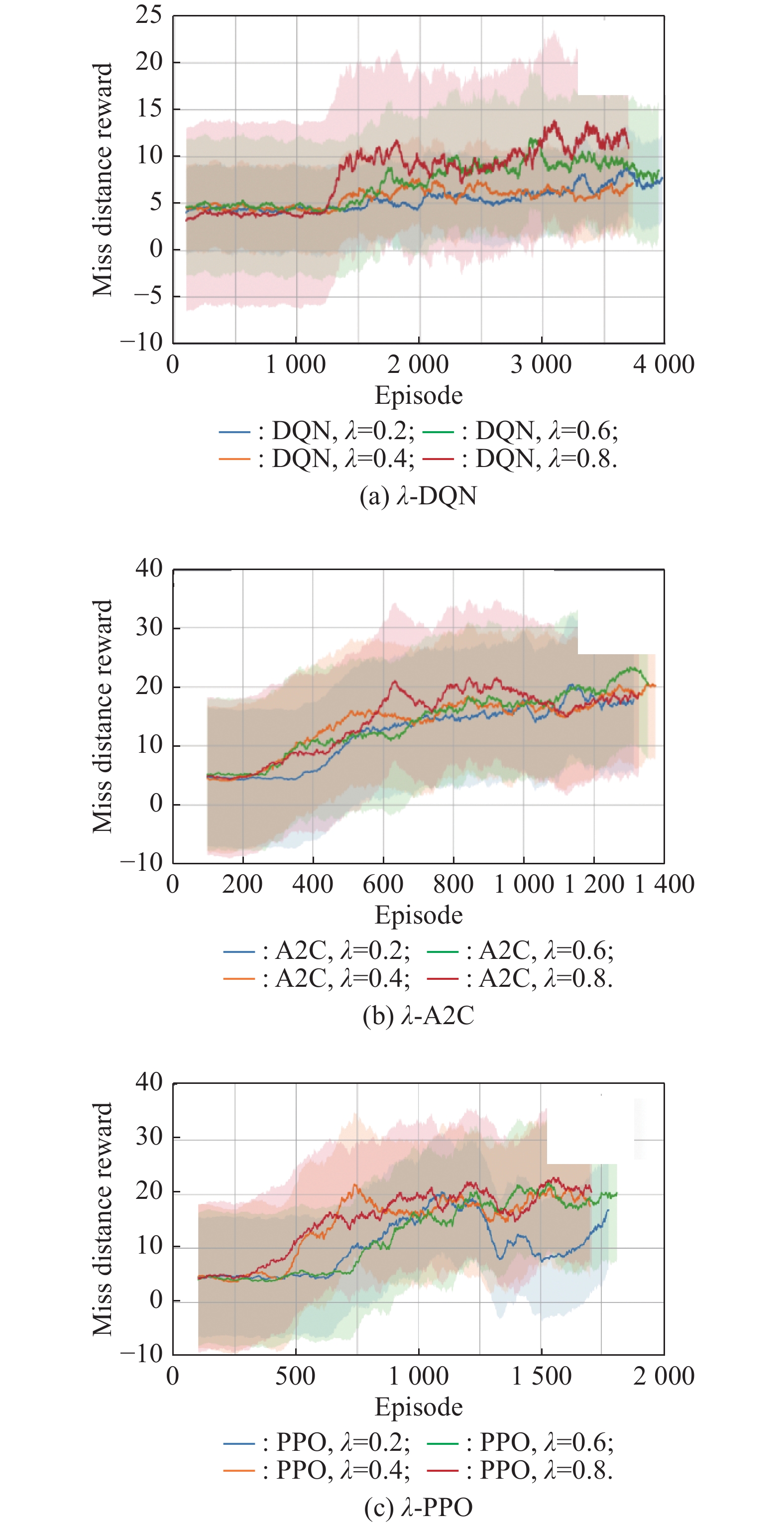
Table 7
Convergence statistics test convergence number of significance"
| Algorithm | λ=0.2 | λ=0.4 | λ=0.6 | λ=0.8 |
| λ-DQN | ||||
| λ-A2C | − | − | 950 | 600 |
| λ-PPO | − | 590 |
Table 8
Effective number of scenes corresponding to different back steps"
| Algorithm | Scenes’ number | Back step | |||
| 0 | 1 | 2 | 3 | ||
| λ-DQN | 690 | ||||
| λ-A2C | 221 | ||||
| λ-PPO | 410 | ||||
Fig 6
Histogram of data generation efficiency"
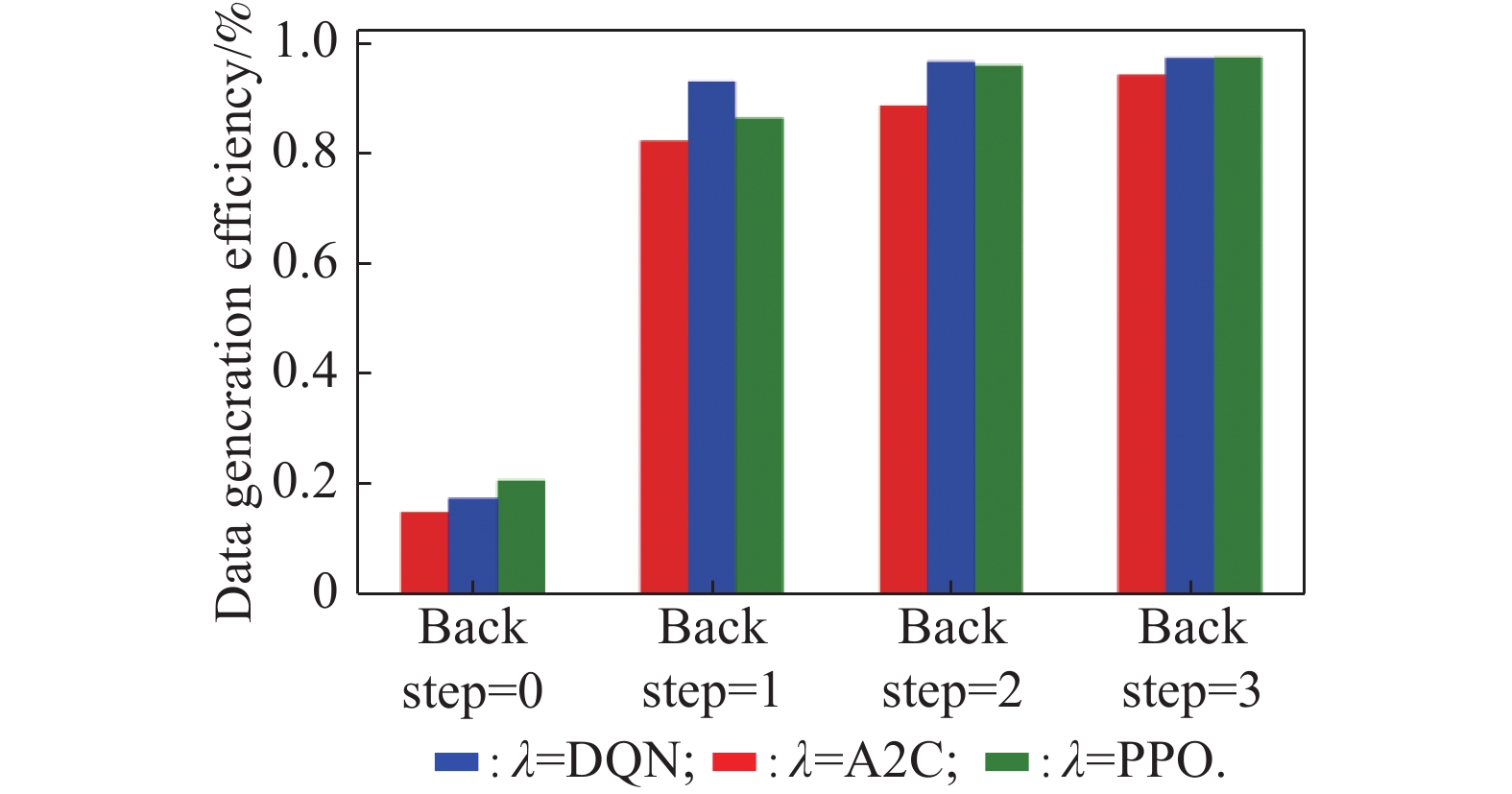
Fig 7
Training time with different back steps"
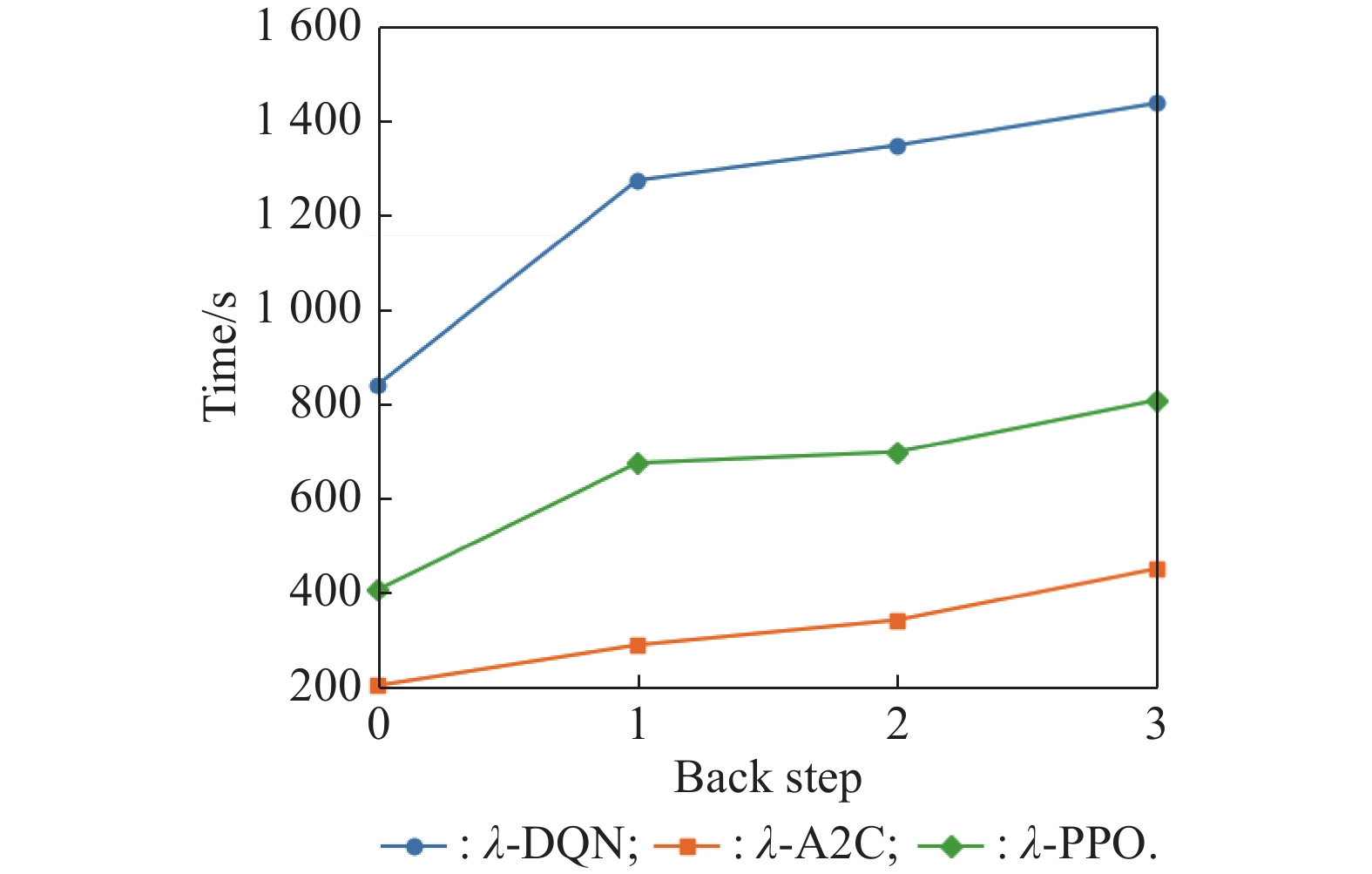
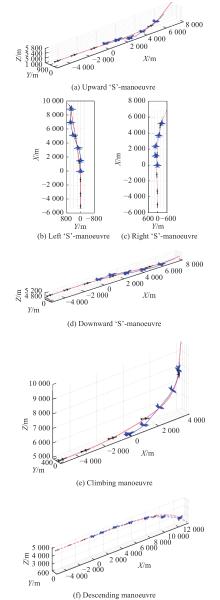
Fig 8
Typical manoeuvres during the training process"

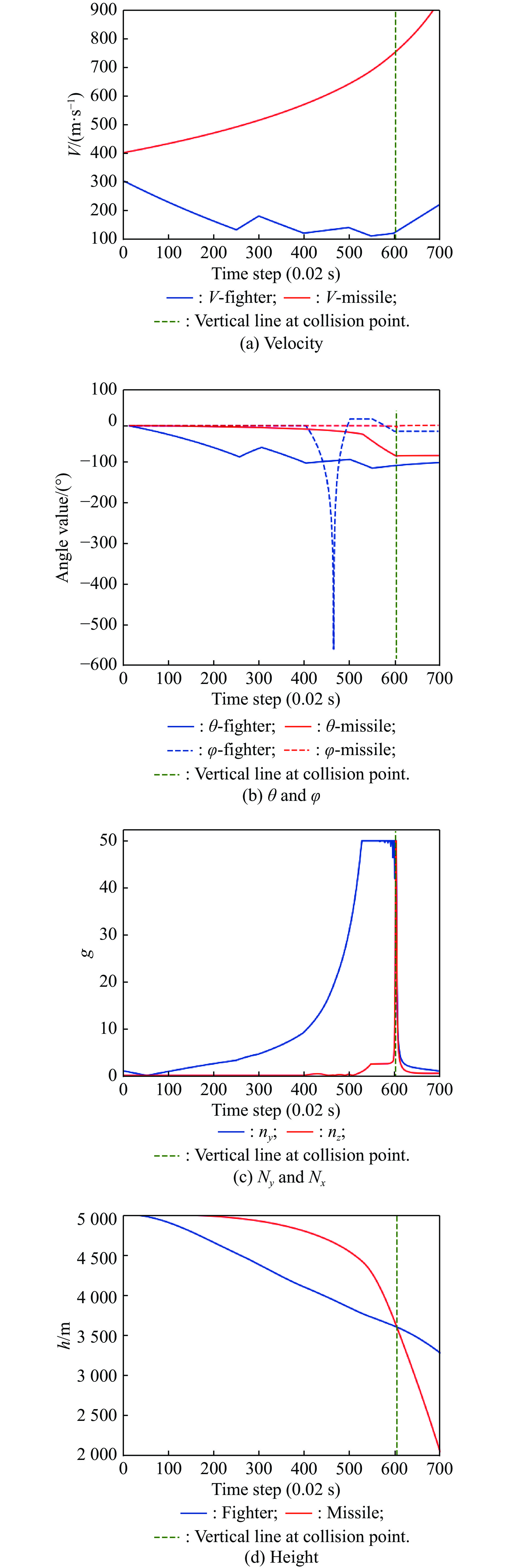
Fig 9
Relationship graph of speed, attitude angle, overload, and altitude changes over time during manoeuvre"
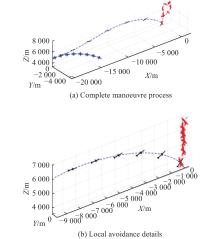
Fig 10
Training results"
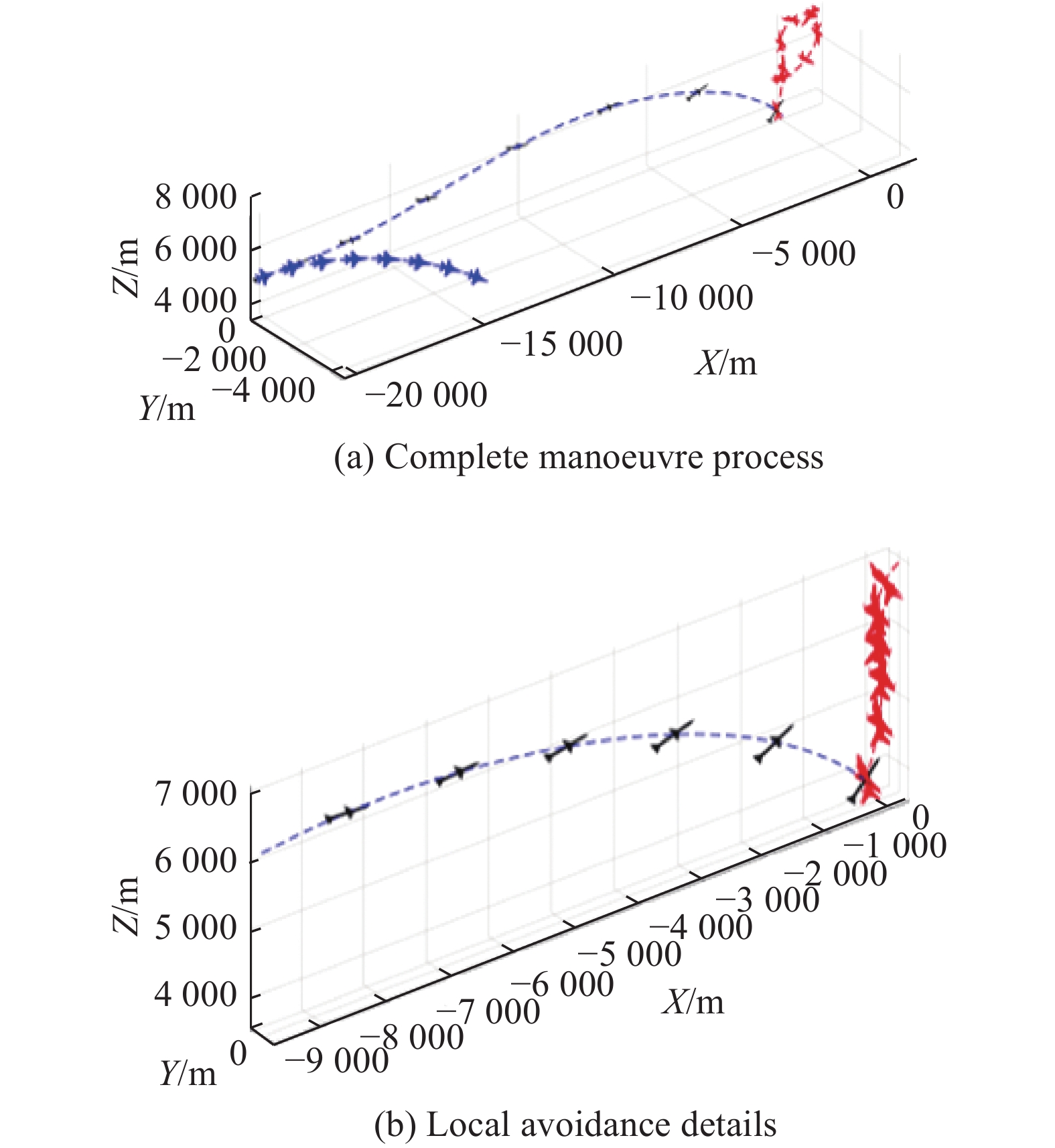
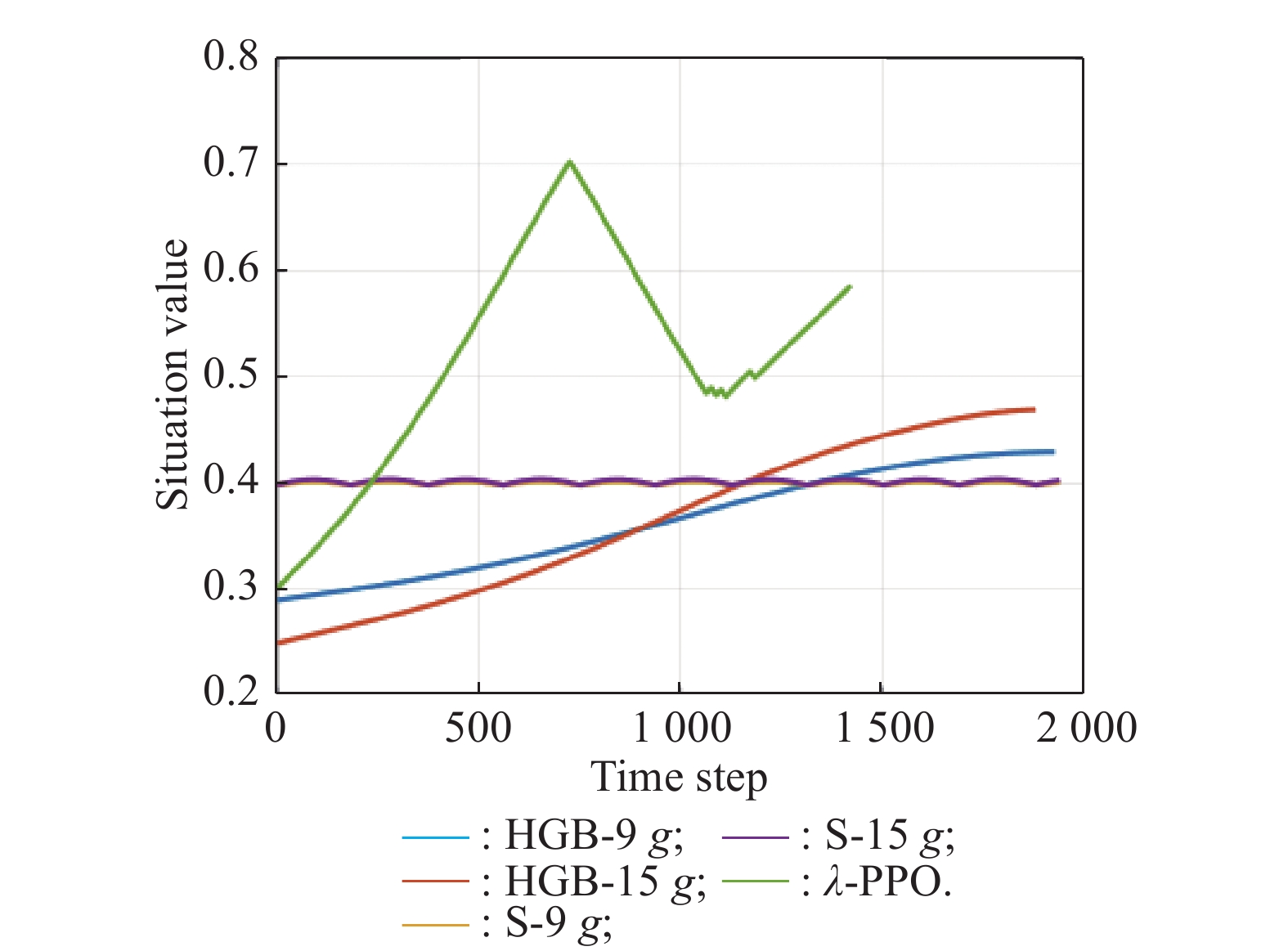
Fig 11
Situational change curve during manoeuvre"
| 1 | YANG X Z, AI J L Evasive maneuvers against missiles for unmanned combat aerial vehicle in autonomous air combat. Journal of System Simulation, 2018, 30 (5): 1957- 1966. |
| 2 |
ZHAN G, ZHANG K, LI K, et al UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience. Journal of Systems Engineering and Electronics, 2024, 35 (3): 644- 665.
doi: 10.23919/JSEE.2024.000022 |
| 3 |
DUO N X, WANG Q Z, LV Q, et al Tactical reward shaping for large-scale combat by multi-agent reinforcement learning. Journal of Systems Engineering and Electronics, 2024, 35 (6): 1516- 1529.
doi: 10.23919/JSEE.2024.000062 |
| 4 |
IMADO F Some aspects of a realistic three-dimensional pursuit-evasion game. Journal of Guidance, Control, and Dynamics, 1993, 16 (2): 289- 293.
doi: 10.2514/3.21002 |
| 5 |
IMADO F, KURODA T Family of local solutions in a missile-aircraft differential game. Journal of Guidance, Control, and Dynamics, 2011, 34 (2): 583- 591.
doi: 10.2514/1.48345 |
| 6 |
ALKAHER D, MOSHAIOV A Game-based safe aircraft navigation in the presence of energy-bleeding coasting missile. Journal of Guidance, Control, and Dynamics, 2016, 39 (7): 1539- 1550.
doi: 10.2514/1.G001676 |
| 7 |
KARELAHTI J, VIRTANEN K, RAIVIO T Near-optimal missile avoidance trajectories via receding horizon control. Journal of Guidance, Control, and Dynamics, 2007, 30 (5): 1287- 1298.
doi: 10.2514/1.26024 |
| 8 |
CARR R W, COBB R G, PACHTER M, et al Solution of a pursuit-evasion game using a near-optimal strategy. Journal of Guidance, Control, and Dynamics, 2018, 41 (4): 841- 850.
doi: 10.2514/1.G002911 |
| 9 | SINGH L. Autonomous missile avoidance using nonlinear model predictive control. Proc. of the AIAA Guidance, Navigation, and Control Conference and Exhibit, 2004. DOI: 10.2514/6.2004−4910. |
| 10 | ZHANG N, CHEN C S, SUN J G, et al Strategy of barrel roll and decoy deployment against infrared air-to-air missile. Infrared Technology, 2022, 44 (3): 236- 248. |
| 11 |
YANG Z, ZHOU D Y, KONG W R, et al Nondominated manoeuvre strategy set with tactical requirements for a fighter against missiles in a dogfight. IEEE Access, 2020, 8, 117298- 117312.
doi: 10.1109/ACCESS.2020.3004864 |
| 12 | YAGCI O, NIKBAY M. Evasive maneuver trajectory optimization of an UCAV against an air to air missile. Proc. of the AIAA Aviation Forum, 2022: 3791. |
| 13 | WANG X P, LIN Q Y, DONG X M. Aircraft evasive maneuver trajectory optimization based on QPSO. Proc. of the International Congress on Ultra Modern Telecommunications and Control Systems, 2010: 416−420. |
| 14 |
LEE G T, KIM C O Autonomous control of combat unmanned aerial vehicles to evade surface-to-air missiles using deep reinforcement learning. IEEE Access, 2020, 8, 226724- 226736.
doi: 10.1109/ACCESS.2020.3046284 |
| 15 | HUANG C H, WANG C Z, CHAI S J, et al. Research on evasion policy of UCAV against infrared air-to-air missile based on soft actor critic algorithm. Proc. of the 14th International Conference on Computer Modeling and Simulation, 2022: 153−159. |
| 16 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al Human-level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 17 |
DEGRAVE J, FELICI F, BUCHLI J, et al Magnetic control of tokamak plasmas through deep reinforcement learning. Nature, 2022, 602 (7897): 414- 419.
doi: 10.1038/s41586-021-04301-9 |
| 18 |
FAWZI A, BALOG M, HUANG A, et al Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 2022, 610 (7930): 47- 53.
doi: 10.1038/s41586-022-05172-4 |
| 19 | WATKINS C J C H. Learning from delayed rewards. Cambridge: Cambridge University, 1989. |
| 20 | SUTTON R S Learning to predict by the methods of temporal differences. Machine Learning, 1988, 3, 9- 44. |
| 21 |
WANG B, LI X L, GAO Z Q, et al Gradient compensation traces based temporal difference learning. Neurocomputing, 2021, 442, 221- 235.
doi: 10.1016/j.neucom.2021.02.042 |
| 22 | LI T, YANG D S, XIE X P, et al Event-triggered control of nonlinear discrete-time system with unknown dynamics based on HDP (λ). IEEE Trans. on Cybernetics, 2021, 52 (7): 6046- 6058. |
| 23 | LI B, LI T, LIU M H, et al. A non-asymptotic analysis of adaptive TD (λ) learning in wireless sensor networks. International Journal of Distributed Sensor Networks, 2022. DOI: 10.1177/15501329221114546. |
| 24 | NAIK A, SUTTON R S. Multi-step average-reward prediction via differential TD (λ). Proc. of the Conference on Reinforcement Learning and Decision Making. http://incompleteideas.net/papers/RLDM22-NS-Differential_{T}Dlambda.pdf. |
| 25 | WAN Y, NAIK A, SUTTON R S. Learning and planning in average-reward Markov decision processes. Proc. of the International Conference on Machine Learning, 2021. DOI: 10.48550/arXiv.2006.16318. |
| 26 | MADAN K, RECTOR-BROOKS J, KORABLYOV M, et al Learning GflowNets from partial episodes for improved convergence and stability. Proc. of the International Conference on Machine Learning, 2023, 23467- 23483. |
| 27 |
CHEN Z, MAGULURI S T, SHAKKOTTAI S, et al A Lyapunov theory for finite-sample guarantees of Markovian stochastic approximation. Operations Research, 2024, 72 (4): 1352- 1367.
doi: 10.1287/opre.2022.0249 |
| 28 | KOU Y X, DENG S J, LI Z W, et al. Collaborative air warfare game environment for multi-agent in 3D space. Proc. of the IEEE International Conference on Unmanned Systems, 2023. DOI: 10.1109/ICUS58632.2023.10318365. |
| 29 | FU S T, ZHANG H J A method of high-precision and fast calculation for attack area of air-to-air missile. Science Technology and Engineering, 2012, 12 (27): 7074- 7077. |
| 30 | YANG W Y, BAI C J, CAI C, et al Survey on sparse reward in deep reinforcement learning. Computer Science, 2020, 47 (3): 182- 191. |
| 31 | SUTTON R S. Reinforcement learning: an introduction. Cambridge: MIT Press, 2018. |
| 32 | FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods. Proc. of the International Conference on Machine Learning, 2018. DOI: 10.48550/arXiv.1802.09477. |
| 33 | CHEN G, PENG Y M, ZHANG M J. An adaptive clipping approach for proximal policy optimization. https://arXiv.org/abs/180406461. |
| [1] | Wenhao CHEN, Gang CHEN, Jichao LI, Jiang JIANG. Disintegration of heterogeneous combat network based on double deep Q-learning [J]. Journal of Systems Engineering and Electronics, 2025, 36(5): 1235-1246. |
| [2] | Rui ZHOU, Weichao ZHONG, Wenlong LI, Hao ZHANG. Self-play training and analysis for GEO inspection game with modular actions [J]. Journal of Systems Engineering and Electronics, 2025, 36(5): 1353-1373. |
| [3] | Siyu HENG, Ting CHENG, Zishu HE, Yuanqing WANG, Luqing LIU. Adaptive dwell scheduling based on Q-learning for multifunctional radar system [J]. Journal of Systems Engineering and Electronics, 2025, 36(4): 985-993. |
| [4] | Yifan ZHANG, Tao DONG, Zhihui LIU, Shichao JIN. Multi-QoS routing algorithm based on reinforcement learning for LEO satellite networks [J]. Journal of Systems Engineering and Electronics, 2025, 36(1): 37-47. |
| [5] | Nanxun DUO, Qinzhao WANG, Qiang LYU, Wei WANG. Tactical reward shaping for large-scale combat by multi-agent reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1516-1529. |
| [6] | Guofei LI, Shituo LI, Bohao LI, Yunjie WU. Deep reinforcement learning guidance with impact time control [J]. Journal of Systems Engineering and Electronics, 2024, 35(6): 1594-1603. |
| [7] | Qi WANG, Zhizhong LIAO. Computational intelligence interception guidance law using online off-policy integral reinforcement learning [J]. Journal of Systems Engineering and Electronics, 2024, 35(4): 1042-1052. |
| [8] | Guang ZHAN, Kun ZHANG, Ke LI, Haiyin PIAO. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience [J]. Journal of Systems Engineering and Electronics, 2024, 35(3): 644-665. |
| [9] | Yaozhong ZHANG, Zhuoran WU, Zhenkai XIONG, Long CHEN. A UAV collaborative defense scheme driven by DDPG algorithm [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1211-1224. |
| [10] | Jiawei XIA, Xufang ZHU, Zhong LIU, Qingtao XIA. LSTM-DPPO based deep reinforcement learning controller for path following optimization of unmanned surface vehicle [J]. Journal of Systems Engineering and Electronics, 2023, 34(5): 1343-1358. |
| [11] | Lu DONG, Zichen HE, Chunwei SONG, Changyin SUN. A review of mobile robot motion planning methods: from classical motion planning workflows to reinforcement learning-based architectures [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 439-459. |
| [12] | Yaozhong ZHANG, Yike LI, Zhuoran WU, Jialin XU. Deep reinforcement learning for UAV swarm rendezvous behavior [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 360-373. |
| [13] | Yunxiu ZENG, Kai XU. Recognition and interfere deceptive behavior based on inverse reinforcement learning and game theory [J]. Journal of Systems Engineering and Electronics, 2023, 34(2): 270-288. |
| [14] | Guangran CHENG, Lu DONG, Xin YUAN, Changyin SUN. Reinforcement learning-based scheduling of multi-battery energy storage system [J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 117-128. |
| [15] | Peng LIU, Boyuan XIA, Zhiwei YANG, Jichao LI, Yuejin TAN. A deep reinforcement learning method for multi-stage equipment development planning in uncertain environments [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1159-1175. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||